最近要开展接口测试,起初打算使用公司已有的Fitnesse测试工具来进行接口测试。过程中发现,构造接口字段数据、测试数据都比较困难,接口参数多的时候,用例量就会很多,关键执行速度还慢。所以放弃了。
找了一些其它工具,都不太能解决数据构造困难的问题。找不到工具,就直接使用代码来实现。考虑到代码量,结合网上的一些推荐,决定使用python+pytest来编写接口自动化用例。
决定了语言和框架,接下来要考虑一下实现需求。
1.一套用例可以测试多套环境
2.可以被jenkins调度执行
3.拥有测试报告
4.接口中某些字段值在每次请求中不重复
5.可以多接口关联测试
6.构造的表数据可以和接口字段数据关联
7.pytest用例和实际用例数据要分离,方便维护
8.针对多样的响应内容,具备多样的断言方式。
需求一:一套用例可以测试多套环境
公司的测试环境不止一套,希望在使用接口自动化用例时,可以随意的切换被测环境。
为了满足这个需求,首先要完成接口地址等信息的独立配置,而且是要按照一套环境的维度去管理信息。

我的做法如上图,首先我给每套环境设置了一个别名,比如上图中的lion环境,然后设计了一个服务去持久化变量值信息(变量名称所有环境保存一致)。
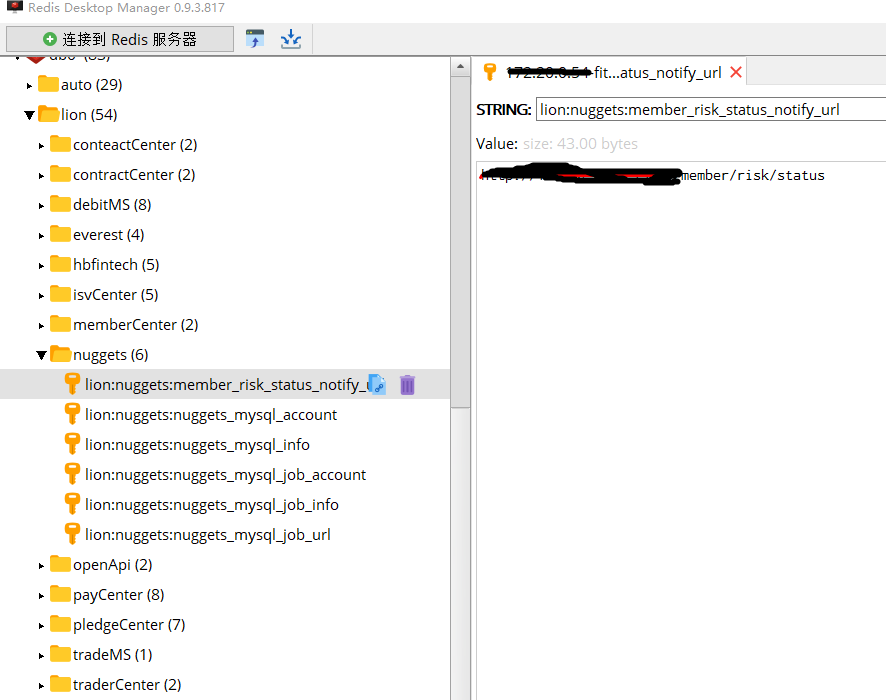
接着将环境名称和变量名称,组合起来,保存到redis中(如上图),供后续接口自动化用例读取并使用。
环境信息搞定之后,接下来的任务就是,设计一种方法让接口自动化用例使用环境信息。
这里采用的方法是,在执行时,指定环境别名。
pytest的用例有多种执行方式,这里使用pytest.main()来启动,通过将pytest.main()写入一个py文件中,如下面代码。
memberCenter.py
1 if __name__ == "__main__": 2 if (len(sys.argv) == 2): 3 _, env = sys.argv 4 else: 5 env = 'lion' 6 BaseUtil.initTest(env) 7 pytest.main(['--alluredir=./allure-results', '--maxfail=5','-s','-rA', 'testcase/membercenter/'])
启动时,接受一个参数env,并将env作为属性添加到Context中,供用例使用。
BaseUtil.py from context import Context as ct def initTest(env): ct.env = env
调用命令:

这里就指定了测试环境的别名为lion。
有了环境别名,再加上统一的变量名称,就可以使用下面的方式,去redis获取对应的变量值了。

以上就实现了多环境测试的需求。后续只要维护好环境别名、变量名称和变量值就可以了。
需求二: 可以被jenkins调度执行
这个比较简单,通过参数化构建就可以。
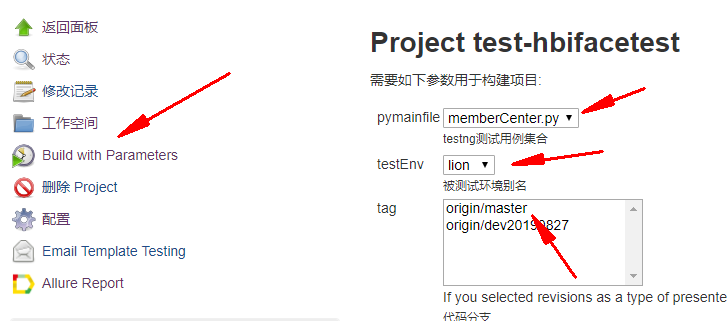
不过为了不影响Jenkins所在服务器,我使用了docker去执行用例
下面是Dockerfile的配置

下面是jenkins中的Execute shell
1 echo "清除历史报告记录" 2 cd ${WORKSPACE} 3 cd allure-report && rm -rf * 4 cd ${WORKSPACE} 5 cd allure-results && rm -rf * 6 7 echo "开始执行命令" 8 cd ${WORKSPACE} 9 10 function del_ci { 11 echo "$1" 12 docker stop chbifacetest 13 docker rm chbifacetest 14 docker rmi hbifacetest:1.1 15 } 16 17 docker inspect --format '{{.State.Running}}' chbifacetest && del_ci "删除容器和镜像" 18 19 20 docker build -t hbifacetest:1.1 . 21 docker run -v ${WORKSPACE}/allure-results:/usr/local/hbifacetest/allure-results -v ${WORKSPACE}/allure-report:/usr/local/hbifacetest/allure-report --name chbifacetest hbifacetest:1.1 ${pymainfile} ${testEnv} 22 echo "执行结束"
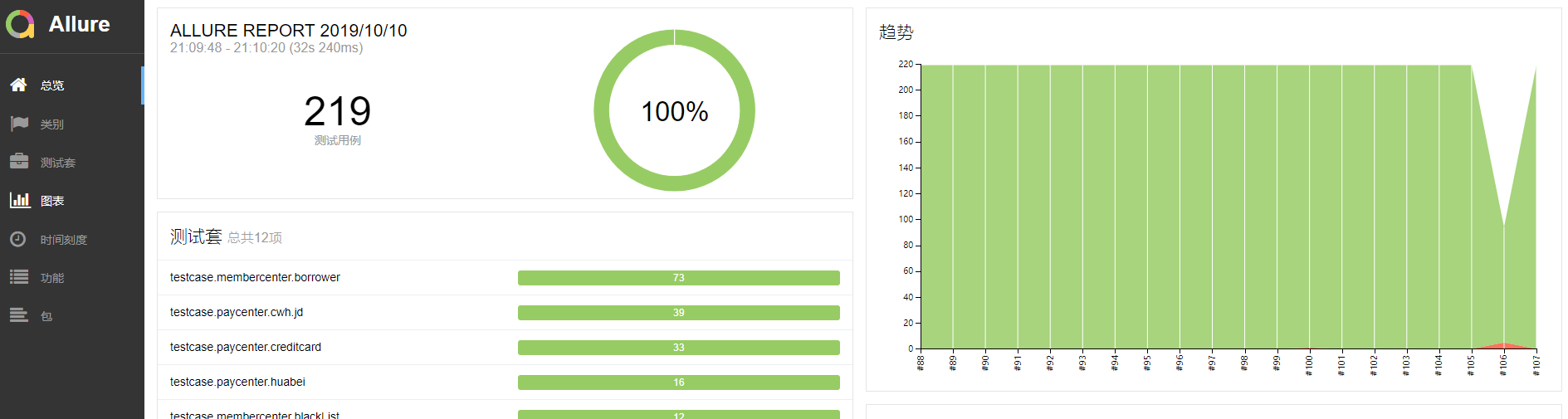
需求三 拥有测试报告
测试报告使用的是Allure,主要是美观且配置简单,(参考:https://docs.qameta.io/allure/#_pytest)
step1:配置报告路径
添加一个参数--alluredir=./allure-results

step2:编写用例时,添加注释
step3:在jenkins中安装插件

step4:在job中配置报告路径
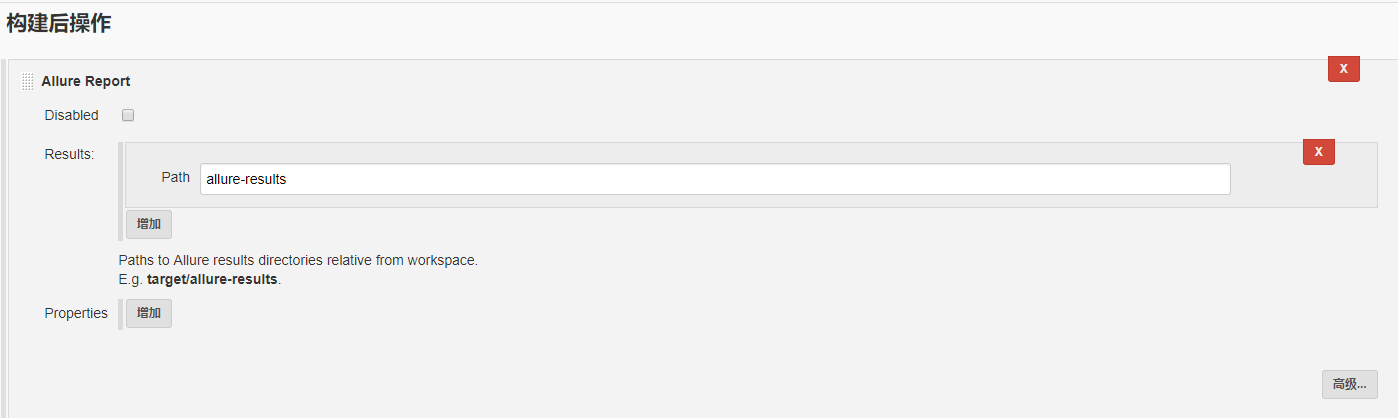
step5:在另一个job中添加执行计划
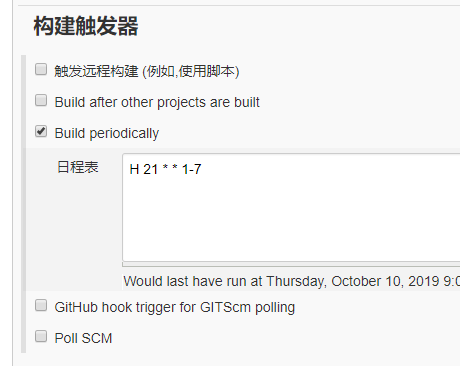
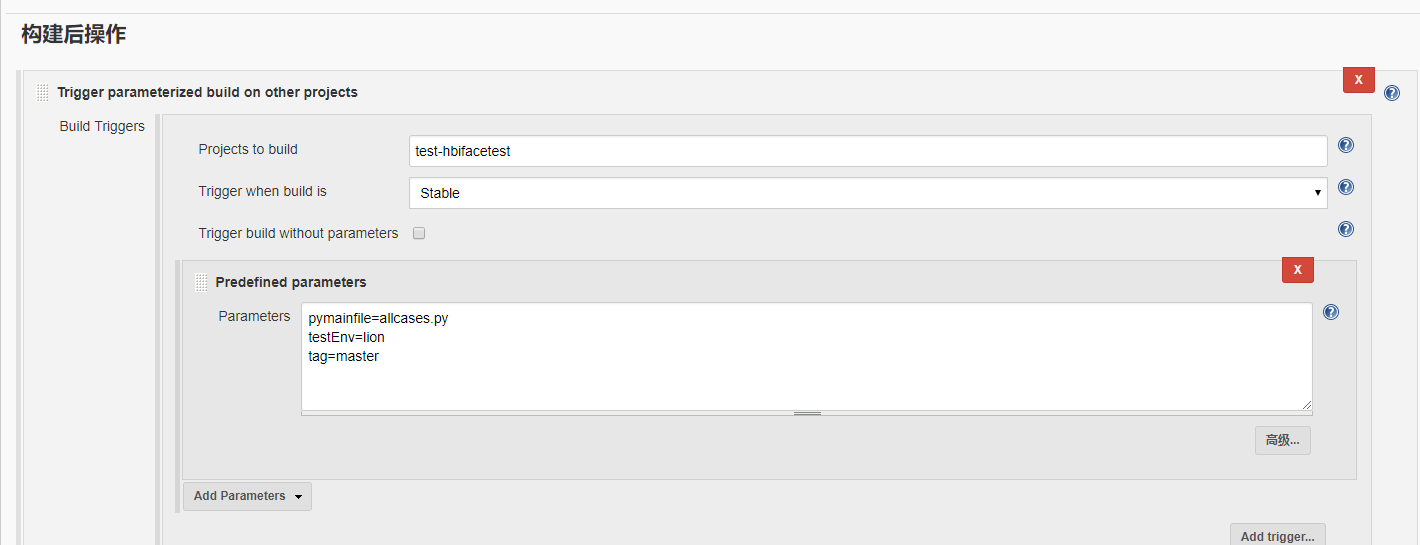
step6:查看报告
需求四:接口中某些字段值在每次请求中不重复
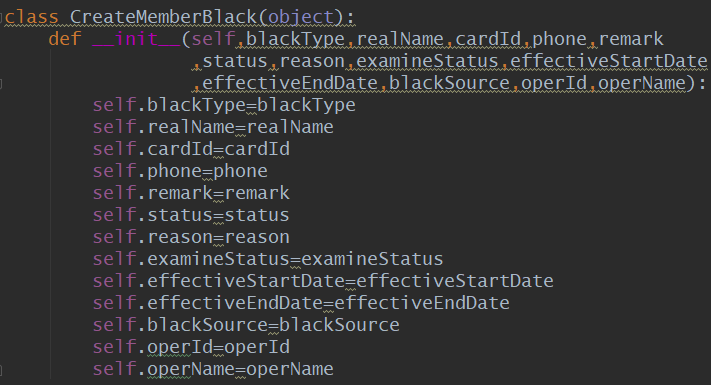
这里通过python的一个库factory-boy来实现该需求。(参考:https://www.cnblogs.com/moonpool/p/11352705.html)
大概的原理就是将每个接口当做一个对象来处理,通过factory-boy给每个字段添加值,可以是固定值,也可以是随机值。然后将对象转成dict,并发送请求。(复杂对象转dict比较麻烦,参考:https://www.cnblogs.com/moonpool/p/11454902.html)
如下图中的红框部分字段,每次请求都将是不同的值。
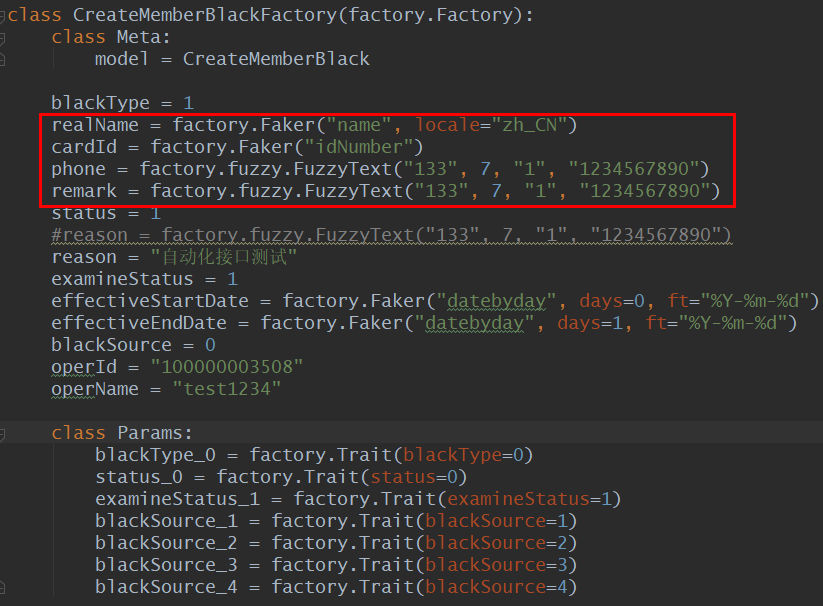
需求五: 可以多接口关联测试
针对这个需求,实现的主要思路是,可以在一条Pytest用例中,拿到所有接口的请求和响应参数。
这里利用了pytest中fixture,将每个接口的http请求方法封装成fixture,后续传递给pytest用例使用。同理实现了 加载用例数据的Fixture
1 #接口Fixture 2 @pytest.fixture(scope="function") 3 def member_borrower_addBorrower_http_json(): 4 def _member_borrower_addBorrower_http_json(dict={"key": "value"}): 5 r = ht.post_json(url=member_borrower_addBorrower_url, json=dict,headers=headers_json) 6 return r 7 8 return _member_borrower_addBorrower_http_json 9 10 @pytest.fixture(scope="function") 11 def member_borrower_updateBorrower_http_json(): 12 def _member_borrower_updateBorrower_http_json(dict={"key": "value"}): 13 r = ht.post_json(url=member_borrower_updateBorrower_url, json=dict,headers=headers_json) 14 return r 15 16 return _member_borrower_updateBorrower_http_json 17 18 #加载用例数据的Fixture 19 @pytest.fixture(scope="function",params=addBorrower) 20 def test_member_borrower_addBorrower(request): 21 dict=request.param 22 return dict 23 24 @pytest.fixture(scope="function",params=updateBorrower) 25 def test_member_borrower_updateBorrower(request): 26 dict=request.param 27 return dict
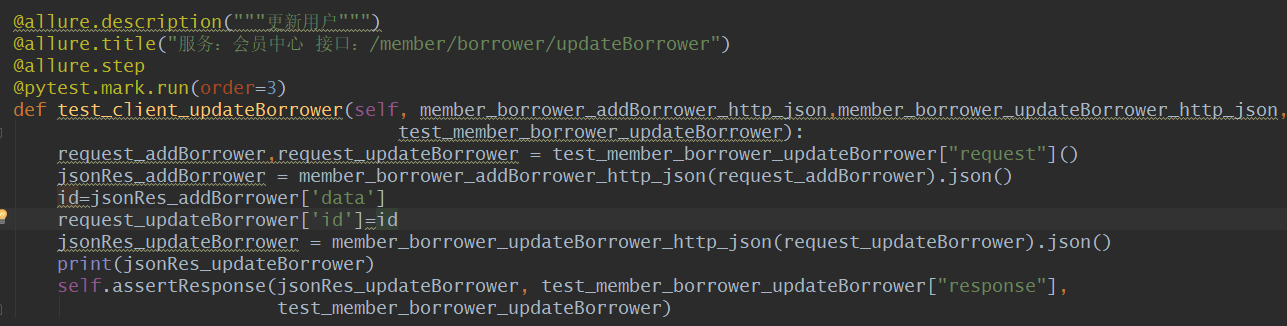
下面是用例数据,可以看到request中传递的是一个函数,函数执行后,可以拿到两个请求的请求参数。

下面的是pytest用例,可以看到用例中可以同时维护两个请求接口的请求参数和响应内容
这里例子比较简单,更新请求中,需要使用到添加响应中的data字段值。
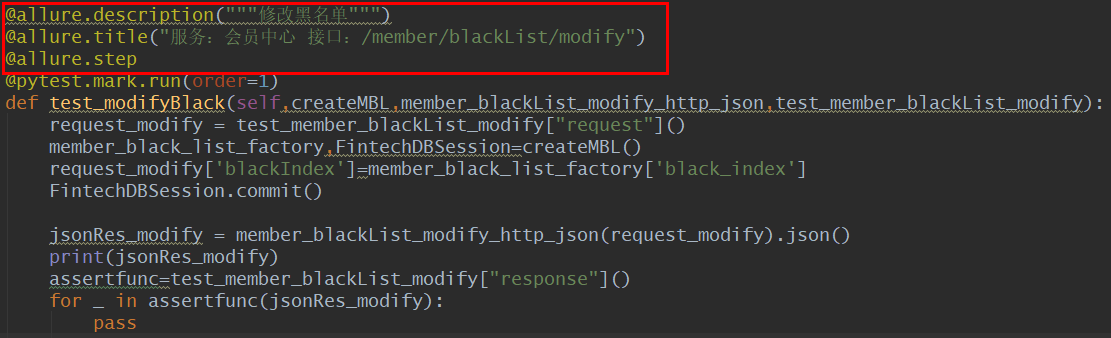
需求六 构造的表数据可以和接口字段数据关联
有时候没有办法,通过其它接口的调用得到的信息,来为当前测试接口做数据入参。可偏偏需要在数据库中存在数据,才可以调用当前测试接口。
可以利用Factory-boy和sqlalchemy来实现这个需求。利用Factory-boy生成随机数据,利用sqlalchemy将数据入库。
例如下面pytest用例的红框部分,就是在插入数据,并使用数据中black_index,作为当前测试接口的请求入参
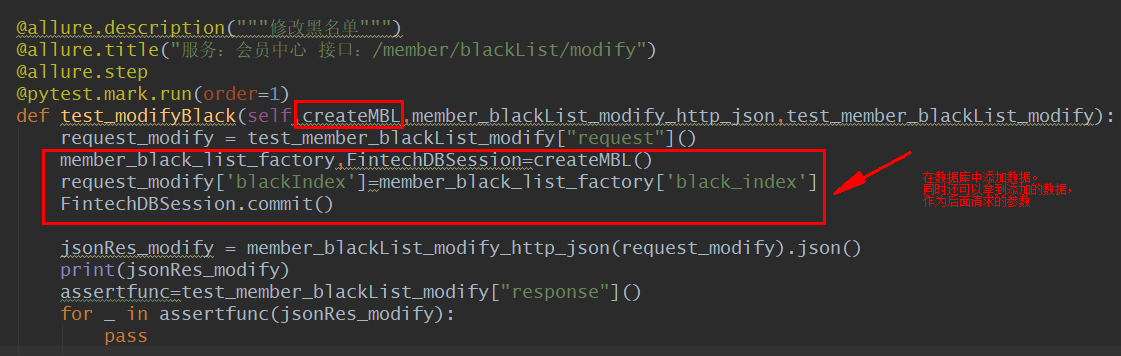
下面是CreateMBL函数的实现
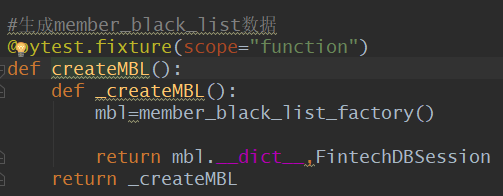
下面是Factory-boy生成数据的代码 (参考:https://www.cnblogs.com/moonpool/p/11370502.html)
1 import factory 2 import factory.fuzzy 3 from sqlalchemy import Column,String,BIGINT,INT,VARCHAR,DECIMAL, Unicode, create_engine 4 from sqlalchemy.ext.declarative import declarative_base 5 from sqlalchemy.orm import scoped_session, sessionmaker 6 from .dbsession import FintechDBSession 7 from baseutil.pr import Provider 8 9 Base = declarative_base() 10 11 class member_black_list(Base): 12 # 表的名字: 13 __tablename__ = 'member_black_list' 14 15 # 表的结构: 16 black_index=Column(BIGINT(), primary_key=True) 17 black_type=Column(INT()) 18 real_name=Column(VARCHAR(120)) 19 card_id=Column(VARCHAR(40)) 20 phone=Column(VARCHAR(40)) 21 remark=Column(VARCHAR(1024)) 22 oper_id=Column(VARCHAR(40)) 23 oper_name=Column(VARCHAR(255)) 24 create_time = Column(VARCHAR(14)) 25 update_time=Column(VARCHAR(14)) 26 status=Column(INT()) 27 reason=Column(VARCHAR(512)) 28 examine_status=Column(INT()) 29 effective_start_date=Column(VARCHAR(8)) 30 effective_end_date=Column(VARCHAR(8)) 31 black_source=Column(INT()) 32 version=Column(INT()) 33 34 factory.Faker.add_provider(Provider) 35 36 class member_black_list_factory(factory.alchemy.SQLAlchemyModelFactory): 37 class Meta: 38 model = member_black_list 39 sqlalchemy_session = FintechDBSession 40 41 black_index = factory.Faker("randomInt") 42 black_type = 1 43 real_name = factory.Faker("name", locale="zh_CN") 44 card_id = factory.Faker("idNumber") 45 phone = factory.fuzzy.FuzzyText("1333", 6, "1", "1234567890") 46 remark = "自动化接口测试" 47 oper_id = "100000003508" 48 oper_name = "test1234" 49 create_time = factory.Faker("currentTimeByFormat") 50 update_time = factory.Faker("currentTimeByFormat") 51 status = 1 52 reason = "自动化接口测试" 53 examine_status = 1 54 effective_start_date = factory.Faker("datebyday", days=0, ft="%Y-%m-%d") 55 effective_end_date = factory.Faker("datebyday", days=1, ft="%Y-%m-%d") 56 black_source = 0 57 version = 0
需求七 pytest用例和实际用例数据要分离,方便维护
在需求五中依据可以看出, pytest用例和实际用例数据是分离。
大部分接口自动化做法是使用excel去维护用例,但是当接口或响应字段比较多的时候,编写用例比较麻烦。如果出现接口字段变更,修改用例也变得比较麻烦。
首先pytest用例和实际用例分离是必须的,接下来就是怎么维护用例的问题。
下面就是我的实际用例数据,可以看到request中通过不同的参数,可以生成不同的请求数据。至于怎么执行用例,参考https://www.cnblogs.com/moonpool/p/11351859.html
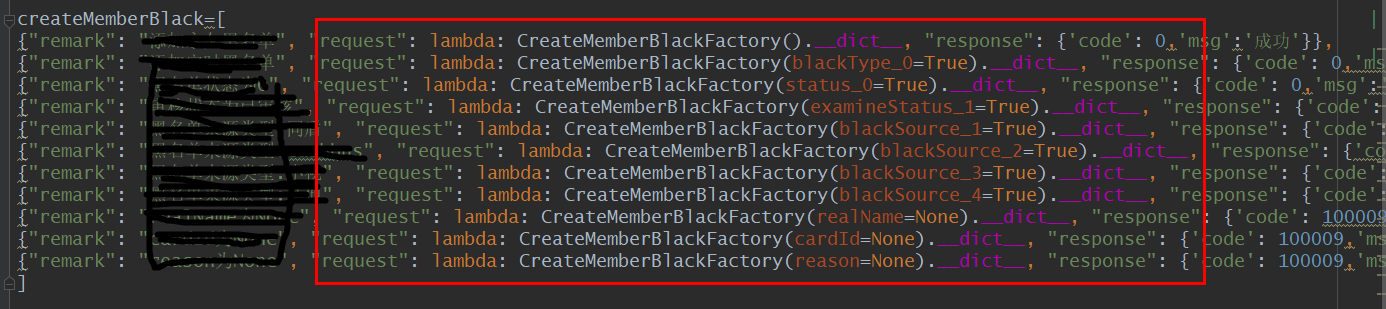
需求八 针对多样的响应内容,具备多样的断言方式
起初在用例的response中,只存放了一个dict,如下图,但是有时候响应内容(json格式)是多样的,需要断言的字段不一定都在json的顶层结构中,可能还会出现嵌套dict以及list的情况。

下面是我的实现。主要的思想就是根据不同的断言需求,传递给不同的断言方法。

用例中调用下面的函数,可以生成一批断言集合。
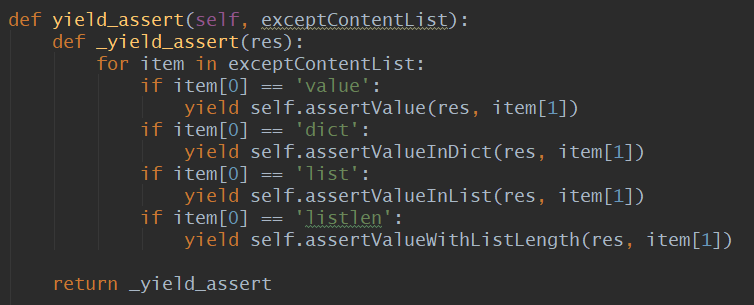
当断言需求类型是dict的时候,会调用下面的函数。
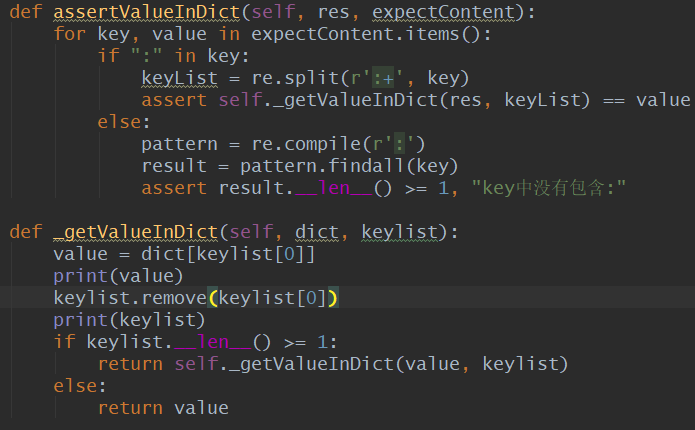
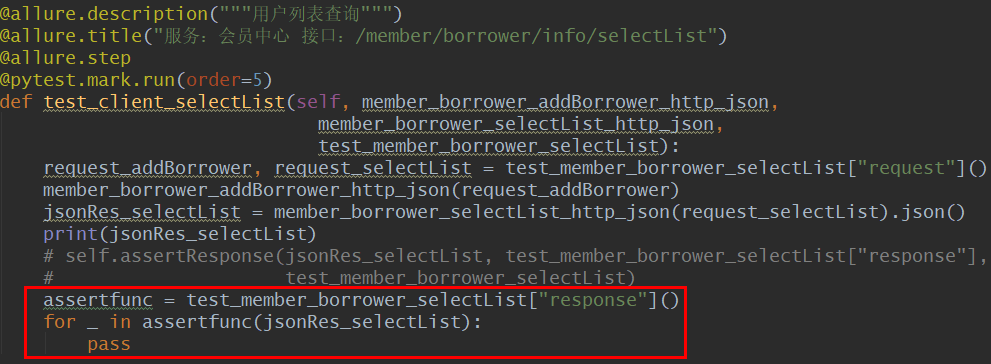
用例response编写,指定不同的断言需求

pytest 用例使用,如红框部分,结合上面的用例的断言需求,在用例执行时,实时传入实际响应内容。再遍历执行断言函数集合。就完成了多样的断言需求。