FP-growth(Frequent Pattern Growth)算法用于发现频繁项集
作用:比 Apriori 更高效的发现频繁项集
特点:快于 Apriori、实现比较困难
Apriori
每次增加频繁项集的大小,都会重新扫描整个数据集
当数据集很大时,这会显著降低频繁项集发现的速度
FP-growth
只需要对数据进行两次遍历,能够显著加快发现繁项集的速度
主要任务是将数据集存储在 FP 树 (频繁模式 Frequent Pattern)
通过 FP 树可以高效发现频繁项集,执行速度通常要比 Apriori 好两个数量级
这种算法虽然能更为高效地发现频繁项集,但不能用于发现关联规则
它发现频繁项集的基本过程如下:
(1) 构建 FP 树
(2) 从 FP 树中挖掘频繁项集
FP 树
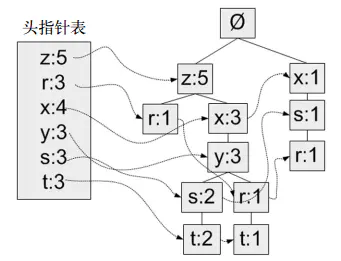
一个元素项可以在一棵 FP 树中出现多次
FP 树会存储项集的出现频率,每个项集以路径的方式存储在树中
存在相似元素的集合会共享树的一部分,只有当集合之间完全不同时,树才会分叉
树节点上给出集合中的单个元素及其在序列中的出现次数,路径会给出该序列的出现次数
相似项之间会有链接即节点链接 (node link) 用于快速发现相似项的位置
如图,根节点是空集,从上越往下每个元素出现的次数越少
第一遍扫描会计算所有元素出现的次数,然后第二遍依次对每个记录进行操作
比如记录 {x,y,z},假设 z 出现的次数最多,x 次之,y 最少
则从上往下是 z 节点,x 节点,y 节点
然后首先看根节点下有没有 z 节点,有则增加节点的计数
没有则创建 z 节点作为根节点的子节点,并赋予计数值
再看 z 节点下有没有 x 节点,有则增加计数
没有则创建 x 节点作为 z 节点的子节点并赋予计数值
以此类推对 y 进行操作,然后再取下一条记录操作
FP 树可以有相同节点比如有多个 x 节点,这些 x 节点会通过节点链接串起来
会有个 header 表存储每个元素的第一个链接、以及该元素出现的总次数
从该图可以判断子集 {z,x,y,s,t} 出现过 2 次
{z,x,y,r,t} 出现过 1 次,{z,x,y} 出现过 3 次,{z} 出现过 5 次,{y,s} 出现过 2 次
{x,s} 有两条分支分别出现 2 次和 1 次总共出现 3 次
每个节点都是只有一个元素的频繁项集
从根节点到叶子节点的每条路径上的元素可以任意组合(该路径必须包括根节点)
该组合中最下层节点的数字就是该组合出现的次数,达到阀值的既为频繁项集
算法
遍历所有记录的所有项,计算每个单项的出现次数(第一次遍历)
取达到阀值的单项,记为频繁项集 L1,并记录每个单项的总的出现次数
构建 FP 树
空集作为树的根节点
遍历每一条记录(第二次遍历)
取该记录中存在于L1的单项,并按L1记录的总次数降序排序
取第一个既次数最多的单项
如果根节点没有该单项的子节点,则创建子节点并记录该记录出现的次数
如果有相应的子节点则只增加计数
再取第二个单项,同样,将其作为第一个单项的子节点,或对已有节点增加计数
以此类推创建其他节点
创建 header 链接所有相同元素节点
从 FP 树寻找频繁项集
初始化前缀频繁项为空集
挖掘树
按元素总次数从少到多的顺序遍历头指针表
前缀频繁项 + 当前头指针表元素,作为新挖掘出的频繁项集
新的频繁项集同时也作为新的前缀频繁项
取出所有从该元素的父节点到根节点的完整路径
这些完整路径作为新的记录,记录出现次数为路径上该元素的次数
以上图的元素 s 为例,相当于取出了 2 条新记录
{y,x,z} : 2
{x} : 1
为这些新元素再构建 FP 树
以新的前缀频繁项对新的 FP 树递归进行挖掘
代码
# coding=utf-8
class treeNode:
"""
FP 树的节点
name - 元素
count - 出现次数
nodeLink - 链接相同元素节点
parent - 链接父节点
children - 链接子节点 (可以有多个)
"""
def __init__(self, nameValue, numOccur, parentNode):
self.name = nameValue
self.count = numOccur
self.nodeLink = None
self.parent = parentNode
self.children = {}
def inc(self, numOccur):
self.count += numOccur
def createTree(dataSet, minSup=1):
"""
创建 FP 树
dataSet - 字典,每个 key 是一条记录,比如 frozenset(['x','y']),对应的 value 是该条记录出现的次数
minSup - 最小可信度
"""
headerTable = {}
# 每条记录
for trans in dataSet:
# 每个元素
for item in trans:
# 计算每个元素出现的次数
headerTable[item] = headerTable.get(item, 0) + dataSet[trans]
for k in headerTable.keys():
# 只取至少出现 minSup 次的元素
if headerTable[k] < minSup:
del (headerTable[k])
# 得到单个元素的频繁项
freqItemSet = set(headerTable.keys())
if len(freqItemSet) == 0:
# 所有元素都不是频繁项
return None, None
for k in headerTable:
# headerTable 记录每个元素出现的次数、第一个链接节点(初始化为 None)
headerTable[k] = [headerTable[k], None]
# 创建树的根节点
retTree = treeNode('Null Set', 1, None)
# 第二次遍历,使用 items() 函数得到每个记录,以及该记录出现的次数
for tranSet, count in dataSet.items():
localD = {}
# 遍历记录的每个元素
for item in tranSet:
# 该元素是频繁项,记下该条记录出现的次数
if item in freqItemSet:
localD[item] = headerTable[item][0]
# 该记录至少有一个频繁项
if len(localD) > 0:
# 将该记录的频繁元素按出现次数降序排序
orderedItems = [v[0] for v in sorted(localD.items(), key=lambda p: p[1], reverse=True)]
# 更新节点或添加节点
updateTree(orderedItems, retTree, headerTable, count)
# 返回 FP 树、元素表
return retTree, headerTable
def updateTree(items, inTree, headerTable, count):
# items[0] 是出现次数最多的元素
if items[0] in inTree.children:
# 子节点存在,增加计数
inTree.children[items[0]].inc(count)
else:
# 子节点不存在,创建节点
inTree.children[items[0]] = treeNode(items[0], count, inTree)
if headerTable[items[0]][1] is None:
# 表头该元素的链接节点为空,链接到该元素
headerTable[items[0]][1] = inTree.children[items[0]]
else:
# 表头该元素的链接节点不为空,将该元素添加到链接的最后面
updateHeader(headerTable[items[0]][1], inTree.children[items[0]])
if len(items) > 1:
# 对剩下的元素进行迭代
updateTree(items[1::], inTree.children[items[0]], headerTable, count)
def updateHeader(nodeToTest, targetNode):
while nodeToTest.nodeLink is not None:
nodeToTest = nodeToTest.nodeLink
nodeToTest.nodeLink = targetNode
def mineTree(inTree, headerTable, minSup, preFix, freqItemList):
"""
通过 FP 树发现频繁项集
inTree - createTree 的返回值 (这里没显式用到,而是通过 headerTable 隐式用到)
headerTable 是 createTree 的返回值
minSup - 要求最少要出现的次数
preFix - 前缀频繁项,该函数在此基础上构建更大的频繁项,第一次进来为空集
freqItemList - 存储所有的频繁项
"""
bigL = [v[0] for v in sorted(headerTable.items(), key=lambda p: p[1])]
# 迭代每个元素,从次数少的开始,既树的低层往上走
for basePat in bigL:
# 在前缀频繁项的基础上添加元素,得到新的更大的频繁项
newFreqSet = preFix.copy()
newFreqSet.add(basePat)
# 添加频繁项
freqItemList.append(newFreqSet)
# 该元素的每个路径,从该元素的父节点到根节点,产生新的记录集合
condPattBases = findPrefixPath(basePat, headerTable[basePat][1])
# 通过新的记录集合产生新的 FP 树
myCondTree, myHead = createTree(condPattBases, minSup)
if myHead is not None:
# 新的频繁项作前缀,通过新 FP 树,继续迭代
mineTree(myCondTree, myHead, minSup, newFreqSet, freqItemList)
def findPrefixPath(basePat, treeNode):
"""
basePat - 元素
treeNode - 元素的第一个链接节点
"""
condPats = {}
while treeNode is not None:
prefixPath = []
# 从该元素到根节点,组成一个新的项集
ascendTree(treeNode, prefixPath)
if len(prefixPath) > 1:
# 产生键值对 (新项集:新项集出现次数)
# 新项集不包括该元素 basePat
# 新项集的次数取 basePat 在该路径上的次数
condPats[frozenset(prefixPath[1:])] = treeNode.count
# 该元素的下一个链接节点
treeNode = treeNode.nodeLink
return condPats
def ascendTree(leafNode, prefixPath):
if leafNode.parent != None:
prefixPath.append(leafNode.name)
ascendTree(leafNode.parent, prefixPath)