-
数据分析实战——37丨数据采集实战:如何自动化运营微博?
- 使用 Python 自动化运营微博,达成以下的 3 个学习目标:
- 1、掌握 Selenium 自动化测试工具,以及元素定位的方法;
- 2、学会编写微博自动化功能模块:加关注,写评论,发微博;
- 3、对微博自动化做自我总结
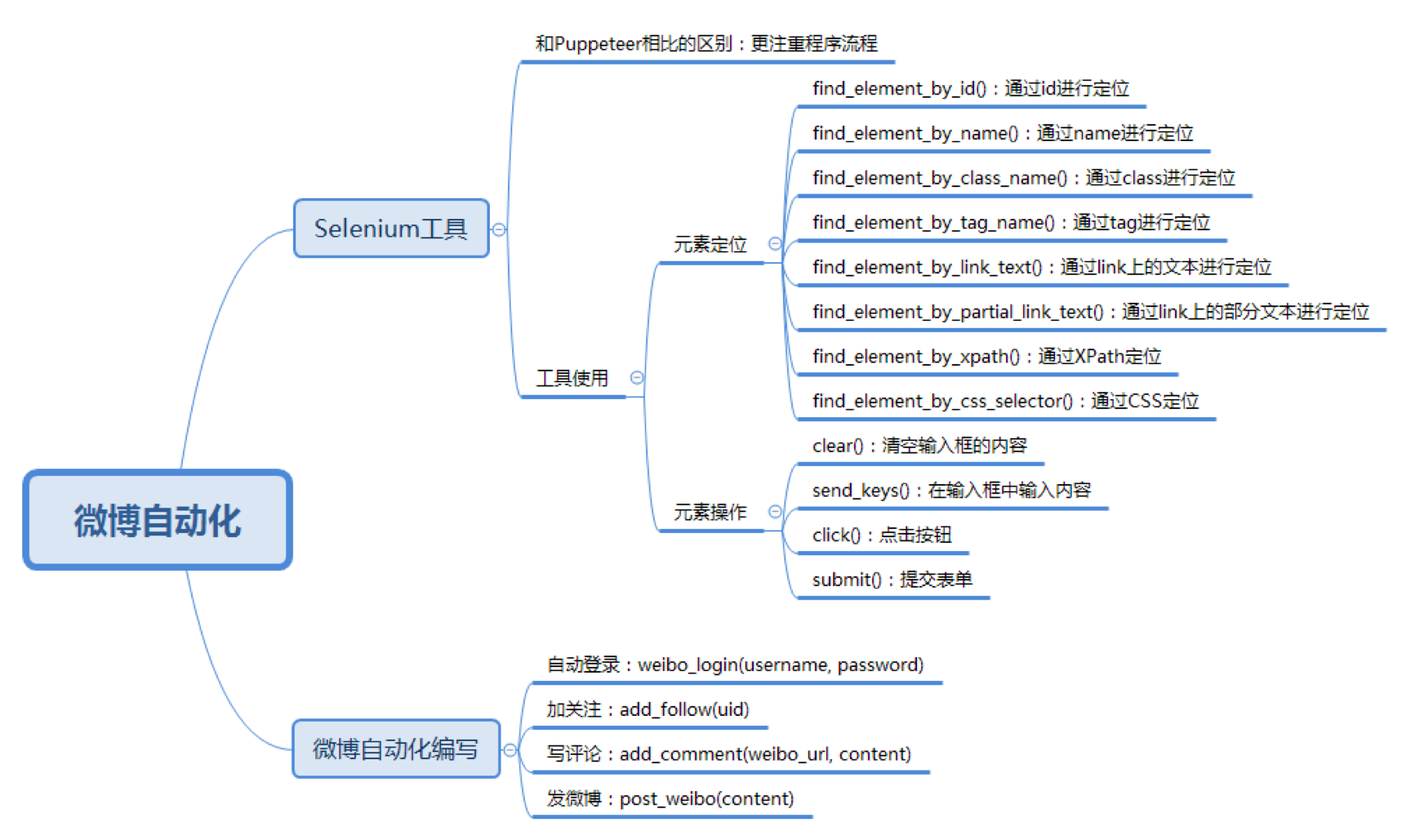
- Selenium 自动化测试工具
- 当我们做 Web 自动化测试的时候,可以选用 Selenium 或者 Puppeteer 工具
- Selenium 更关注程序执行的流程本身,比如找到指定的元素,设置相应的值,然后点击操作
- 而 Puppeteer 是浏览者的视角,比如光标移动到某个元素上,键盘输入某个内容等
- 步骤包含2部分
- 完成微博的自动化登录
- from selenium import webdriver
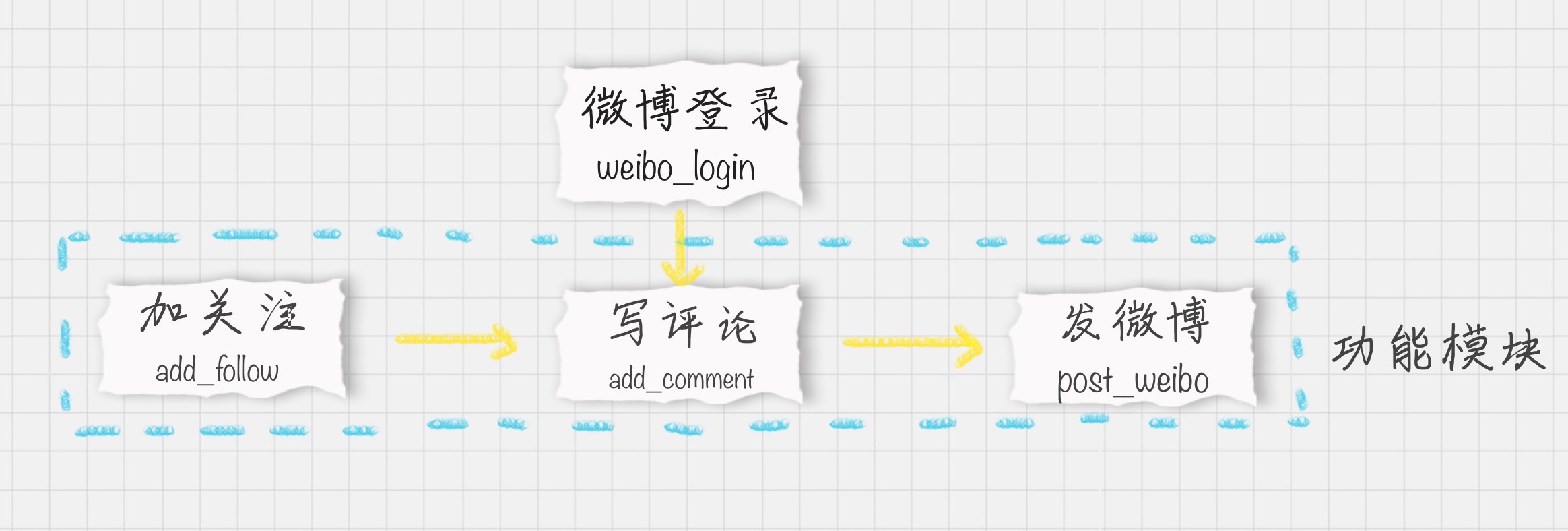
- 微博自动化运营:加关注,写评论,发微博
-
- 加关注
- 第一点是如何找到用户的 UID
- 第二个需要注意的是使用 XPath 定位元素定位
- 写评论
- 如何找到某条微博的链接呢?你可以在某个用户微博页面中点击时间的链接,这样就可以获取这条微博的链接
- 发微博
- 我们可以观察到点击微博页面的右上角的按钮后,会弹出一个发微博的文本框,设置好内容,点击发送即可
- 微博自动化运营只是自动化运营的开始,实际上在微信上我们也可以做同样的操作。比如监听微信群的消息,自动发微信等。实际要考虑的问题比微博的要复杂
- 总结
- 同时我们使用了 implicitly_wait 函数以及 time.sleep() 函数
- 让浏览器和程序等待一段时间,完成数据加载之后再进行后续的操作
- 这样就避免了数据没有加载完,导致获取不到指定元素的情况
-
-
相关阅读:
《linux 必读》
ldd ldconfig
rpm 数据库
/bin, /sbin & /usr/bin, /usr/sbin & /usr/local/bin, /usr/local/sbin & glibc
POSIX
CentOS 下载地址
insert into TABLE by SELECT ...
httpd 处理模型
http 状态码
IP地址 0.0.0.0 是什么意思?
-
原文地址:https://www.cnblogs.com/minimalist/p/12834982.html
Copyright © 2020-2023
润新知