1. Prometheus告警简介
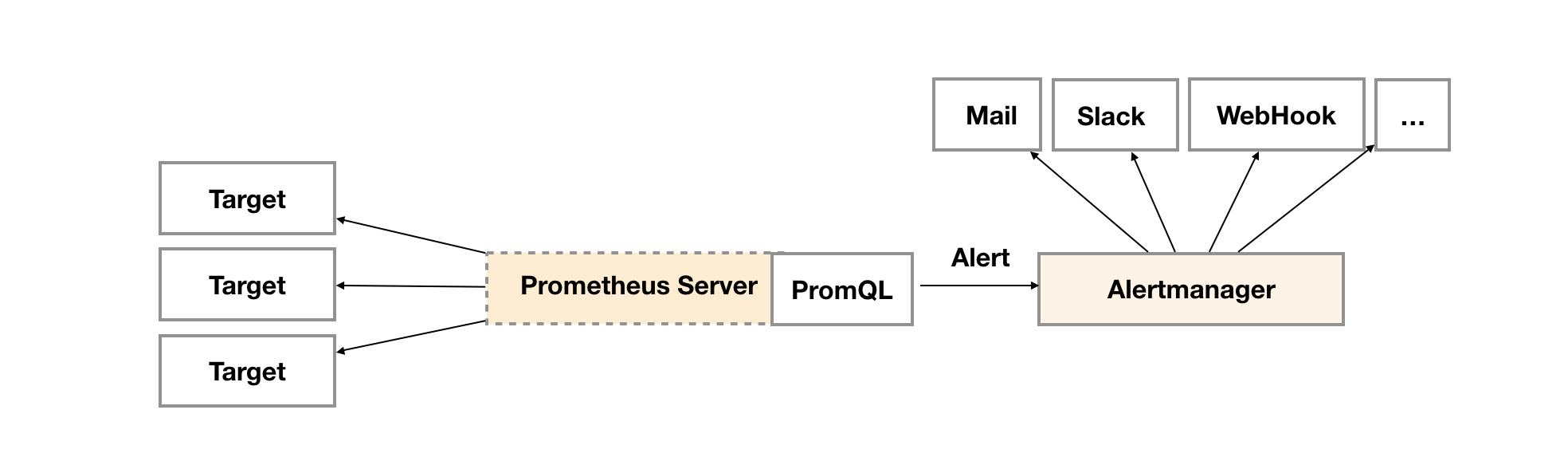
告警能力在Prometheus的架构中被划分成两个独立的部分。如下所示,通过在Prometheus中定义AlertRule(告警规则),Prometheus会周期性的对告警规则进行计算,如果满足告警触发条件就会向Alertmanager发送告警信息。
在Prometheus中一条告警规则主要由以下几部分组成:
- 告警名称:用户需要为告警规则命名,当然对于命名而言,需要能够直接表达出该告警的主要内容
- 告警规则:告警规则实际上主要由PromQL进行定义,其实际意义是当表达式(PromQL)查询结果持续多长时间(During)后出发告警
在Prometheus中,还可以通过Group(告警组)对一组相关的告警进行统一定义。当然这些定义都是通过YAML文件来统一管理的。
Alertmanager作为一个独立的组件,负责接收并处理来自Prometheus Server(也可以是其它的客户端程序)的告警信息。Alertmanager可以对这些告警信息进行进一步的处理,比如当接收到大量重复告警时能够消除重复的告警信息,同时对告警信息进行分组并且路由到正确的通知方,Prometheus内置了对邮件,Slack等多种通知方式的支持,同时还支持与Webhook的集成,以支持更多定制化的场景。
例如,目前Alertmanager还不支持钉钉,那用户完全可以通过Webhook与钉钉机器人进行集成,从而通过钉钉接收告警信息。同时AlertManager还提供了静默和告警抑制机制来对告警通知行为进行优化。
Alertmanager特性
告警能力在Prometheus的架构中被划分成两个独立的部分。如下所示,通过在Prometheus中定义AlertRule(告警规则),Prometheus会周期性的对告警规则进行计算,如果满足告警触发条件就会向Alertmanager发送告警信息。

分组
分组机制可以将详细的告警信息合并成一个通知。在某些情况下,比如由于系统宕机导致大量的告警被同时触发,在这种情况下分组机制可以将这些被触发的告警合并为一个告警通知,避免一次性接受大量的告警通知,而无法对问题进行快速定位。
例如,当集群中有数百个正在运行的服务实例,并且为每一个实例设置了告警规则。假如此时发生了网络故障,可能导致大量的服务实例无法连接到数据库,结果就会有数百个告警被发送到Alertmanager。
而作为用户,可能只希望能够在一个通知中中就能查看哪些服务实例收到影响。这时可以按照服务所在集群或者告警名称对告警进行分组,而将这些告警内聚在一起成为一个通知。
告警分组,告警时间,以及告警的接受方式可以通过Alertmanager的配置文件进行配置。
抑制
抑制是指当某一告警发出后,可以停止重复发送由此告警引发的其它告警的机制。
例如,当集群不可访问时触发了一次告警,通过配置Alertmanager可以忽略与该集群有关的其它所有告警。这样可以避免接收到大量与实际问题无关的告警通知。
抑制机制同样通过Alertmanager的配置文件进行设置。
静默
静默提供了一个简单的机制可以快速根据标签对告警进行静默处理。如果接收到的告警符合静默的配置,Alertmanager则不会发送告警通知。
静默设置需要在Alertmanager的Werb页面上进行设置。
Prometheus中的告警规则允许你基于PromQL表达式定义告警触发条件,Prometheus后端对这些触发规则进行周期性计算,当满足触发条件后则会触发告警通知。默认情况下,用户可以通过Prometheus的Web界面查看这些告警规则以及告警的触发状态。当Promthues与Alertmanager关联之后,可以将告警发送到外部服务如Alertmanager中并通过Alertmanager可以对这些告警进行进一步的处理。
一条典型的告警规则如下所示:
groups:
- name: example
rules:
- alert: HighErrorRate
expr: job:request_latency_seconds:mean5m{job="myjob"} > 0.5
for: 10m
labels:
severity: page
annotations:
summary: High request latency
description: description info
3. 安装Alertmanager
cd /opt/ export VER="0.20.0" wget https://github.com/prometheus/alertmanager/releases/download/v${VER}/alertmanager-${VER}.linux-amd64.tar.gz groupadd prometheus useradd -g prometheus prometheus -d /opt/alertmanager tar -xvf alertmanager-${VER}.linux-amd64.tar.gz cd /opt/ mv alertmanager-${VER}.linux-amd64 /opt/alertmanager chown -R prometheus.prometheus /opt/prometheus
配置 Alertmanager
alertmanager 的 webhook 集成了钉钉报警,钉钉机器人对文件格式有严格要求,所以必须通过特定的格式转换,才能发送给你钉钉的机器人。有人已经t贴心的为大家写了转换插件,那我们也就直接拿来用吧!
( https://github.com/timonwong/prometheus-webhook-dingtalk.git )
vim /opt/alertmanager/alertmanager.yml # 配置如下 global: resolve_timeout: 5m route: group_by: ['alertname'] group_wait: 10s group_interval: 10s repeat_interval: 1h receiver: 'ops_notify' routes: - receiver: ops_notify group_wait: 10s match_re: alertname: '实例存活告警|磁盘使用率告警' - receiver: info_notify group_wait: 10s match_re: alertname: '内存使用率告警|CPU使用率告警' receivers: - name: 'ops_notify' webhook_configs: - url: 'http://localhost:8060/dingtalk/ops_dingding/send' send_resolved: true - name: info_notify webhook_configs: - url: http://localhost:8060/dingtalk/info_dingding/send send_resolved: true inhibit_rules: - source_match: severity: 'critical' target_match: severity: 'warning' equal: ['alertname', 'dev', 'instance']
启动 Alertmanager
vim /usr/lib/systemd/system/alertmanager.service [Unit] Description=Prometheus: the alerting system Documentation=http://prometheus.io/docs/ After=prometheus.service [Service] ExecStart=/opt/alertmanager/alertmanager --config.file=/opt/alertmanager/alertmanager.yml Restart=always StartLimitInterval=0 RestartSec=10 [Install] WantedBy=multi-user.target
配置开机启动
systemctl daemon-reload
systemctl enable alertmanager.service
systemctl stop alertmanager.service
systemctl restart alertmanager.service
systemctl status alertmanager.service
将钉钉接入 Prometheus AlertManager WebHook
如何获取钉钉机器人, 参考文档: https://jingyan.baidu.com/article/d3b74d640c50cc1f77e6092d.html
测试钉钉告警机器人:
curl -H "Content-Type: application/json" -d '{"msgtype":"text","text":{"content":"prometheu
s alert test"}}' 这里是你的钉钉机器人地址(如: https://oapi.dingtalk.com/robot/send?access_token=省略一串字符:-))
{"errcode":0,"errmsg":"ok"}
部署钉钉告警插件
cd /opt/ export VER="0.3.0" wget https://github.com/timonwong/prometheus-webhook-dingtalk/releases/download/v${VER}/prometheus-webhook-dingtalk-${VER}.linux-amd64.tar.gz tar -zxf prometheus-webhook-dingtalk-${VER}.linux-amd64.tar.gz mv prometheus-webhook-dingtalk-${VER}.linux-amd64 /opt/alertmanager/prometheus-webhook-dingtalk #使用方法:prometheus-webhook-dingtalk --ding.profile=钉钉接收群组的值=webhook的值 vim /usr/lib/systemd/system/prometheus-webhook-dingtalk.service [Unit] Description=prometheus-webhook-dingtalk After=network-online.target [Service] Restart=on-failure ExecStart=/opt/alertmanager/prometheus-webhook-dingtalk/prometheus-webhook-dingtalk --ding.profile=ops_dingding=https://oapi.dingtalk.com/robot/send?access_token=省略一串字符 --ding.profile=info_dingding=https://oapi.dingtalk.com/robot/send?access_token=同样省略了一串字符 [Install] WantedBy=multi-user.target
配置开机启动
systemctl daemon-reload
systemctl enable prometheus-webhook-dingtalk
systemctl restart prometheus-webhook-dingtalk
systemctl status prometheus-webhook-dingtalk
4. 整合到prometheus
在prometheus主配置文件中添加/修改:
alerting:
alertmanagers:
- static_configs:
- targets:
- localhost:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
- "/opt/prometheus/rules/node_down.yml" # 实例存活报警规则文件
- "/opt/prometheus/rules/memory_over.yml" # 内存报警规则文件
- "/opt/prometheus/rules/disk_over.yml" # 磁盘报警规则文件
- "/opt/prometheus/rules/cpu_over.yml" # cpu报警规则文件
告警规则文件如下:
node_down.yml
groups:
- name: 实例存活告警规则
rules:
- alert: 实例存活告警
expr: up == 0
for: 1m
labels:
user: prometheus
severity: warning
annotations:
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minutes."
memory_over.yml
groups:
- name: 内存报警规则
rules:
- alert: 内存使用率告警
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes )) / node_memory_MemTotal_bytes * 100 > 80
for: 1m
labels:
user: prometheus
severity: warning
annotations:
description: "服务器: 内存使用超过80%!(当前值: {{ $value }}%)"
cpu_over.yml
groups:
- name: CPU报警规则
rules:
- alert: CPU使用率告警
expr: 100 - (avg by (instance)(irate(node_cpu_seconds_total{mode="idle"}[1m]) )) * 100 > 90
for: 1m
labels:
user: prometheus
severity: warning
annotations:
description: "服务器: CPU使用超过90%!(当前值: {{ $value }}%)"
说明: 以上文档匆匆整理, 如有疑问, 请留言一起探讨.