一:大数据概述
一、大数据简介
1. 概念:指无法在一定时间范围内使用常规软件工具进项捕捉、管理和处理数据集合,需要新处理模式才能具有更强的决策力、洞察力和流程优化能力的海量、高增长率和多样化的信息资产。
2. 作用:解决海量数据的存储和海量数据的分析计算问题。
3. 大数据与云计算的关系:大数据必须依托云计算的分布式处理、分布式数据库和云存储、虚拟化技术,有效地处理大量的容忍经过时间内的数据。
二、大数据特征
1. Volume(容量大):数据的大小决定所考虑的数据的价值和潜在的信息。
2. Velocity(速度快):获得并处理数据的效率。是区分传统数据挖掘最显著特征。
3. Variety(多样性):数据类型的多样性。以数据库/文本的结构化数据和以网络日志,图片,音频、视频等为主的非结构化数据。
4. Value(价值):合理运用大数据,以低成本创造高价值。
5. Variability(可变性):妨碍了处理和有效地管理数据的过程。
6. Veracity(真实性):数据的质量。
7. Complexity(复杂性):数据量巨大,来源多渠道。
三、大数据应用场景
1. 物流仓储:大数据分析系统助力商家精细化运营,提升销量,节约成本。
2. 零售及商品推荐:分析用户消费习惯,给用户推荐可能喜欢的商品,为用户购买商品提供方便。
3. 旅游:深度结合大数据能力和旅游行业需求,共建旅游产业智慧管理、智慧服务和智慧营销的未来。
4. 保险:海量数据挖掘及风险预测,助力保险行业精准直销,提升精细化定价能力。
5. 金融:多维度体现用户特征,助力金融机构推荐优质用户,防范欺诈风险。
6. 房地产:大数据全面助力房地产行业,打造精准投资与营销,选出更合适的地,建更合适的楼,卖更合适的用户。
7. 人工智能:深度结合大数据能力及人工智能,提供数据资源。
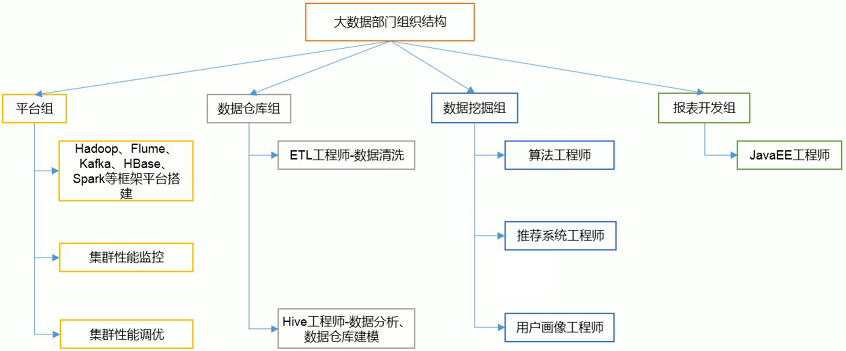
四、大数据部门组织结构
二:Hadoop 概述
一、Hadoop 简介
1. 概念:Hadoop 是由 Apache 基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力进行高速运算和存储。
2. 作用:解决海量数据的存储和海量数据的分析计算问题。
3. 优点
1. 高可靠性:Hadoop 能自动维护数据的多份复制,并且在任务失败后能自动地重新部署(redeploy)计算任务。
2. 高扩展性:Hadoop 在可用的计算机集群间分配数据并完成计算任务的,这些集群可用方便的扩展到数以千计个节点中。
3. 高效性:Hadoop 可以在节点之间动态并行的移动数据,使得速度非常快。
4. 成本低:Hadoop 通过普通廉价的机器组成服务器集群来分发以及处理数据,以至于成本很低。
3. 发展历程
1. Hadoop 起源于 Apache Nutch 项目,始于2002年,是 Apache Lucene的子项目之一。Nutch 的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
2. 2003年、2004年,Google 发表的"分布式文件系统(GFS):可用于处理海量网页的存储 " 和 “分布式计算框架(MapReduce):可用于处理海量网页的索引计算问题” 两篇论文为该问题提供了可行的解决方案。
3. 由于 NDFS 和 MapReduce 在 Nutch 引擎中有着良好的应用,所以它们于2006年2月被分离出来,成为一套完整而独立的软件,并被命名为Hadoop(大数据生态圈,包含很多软件)。
4. 到了2008年年初,Hadoop 已成为 Apache的顶级项目,包含众多子项目,被应用到包括Yahoo在内的很多互联网公司。
4. 三大发行版本
1. Apache Hadoop:免费开源,拥有全世界的开源贡献者,代码更新迭代版本比较快,但难以维护,适合学习使用。
1. 官网地址:http://hadoop.apache.org/releases.html
2. 下载地址:https://archive.apache.org/dist/hadoop/common/
2. Cloudera Hadoop:版本兼容性更好,适用于互联网企业。
1. 官网地址:https://www.cloudera.com/downloads/cdh/5-10-0.html
2. 下载地址:http://archive-primary.cloudera.com/cdh5/cdh/5/
3. Hortonworks Hadoop:核心免费开源产品软件HDP(ambari),提供一整套的web管理界面来管理集群。
1. 官网地址:https://hortonworks.com/products/data-center/hdp/
2. 下载地址:https://hortonworks.com/downloads/#data-platform
二、Hadoop 核心架构
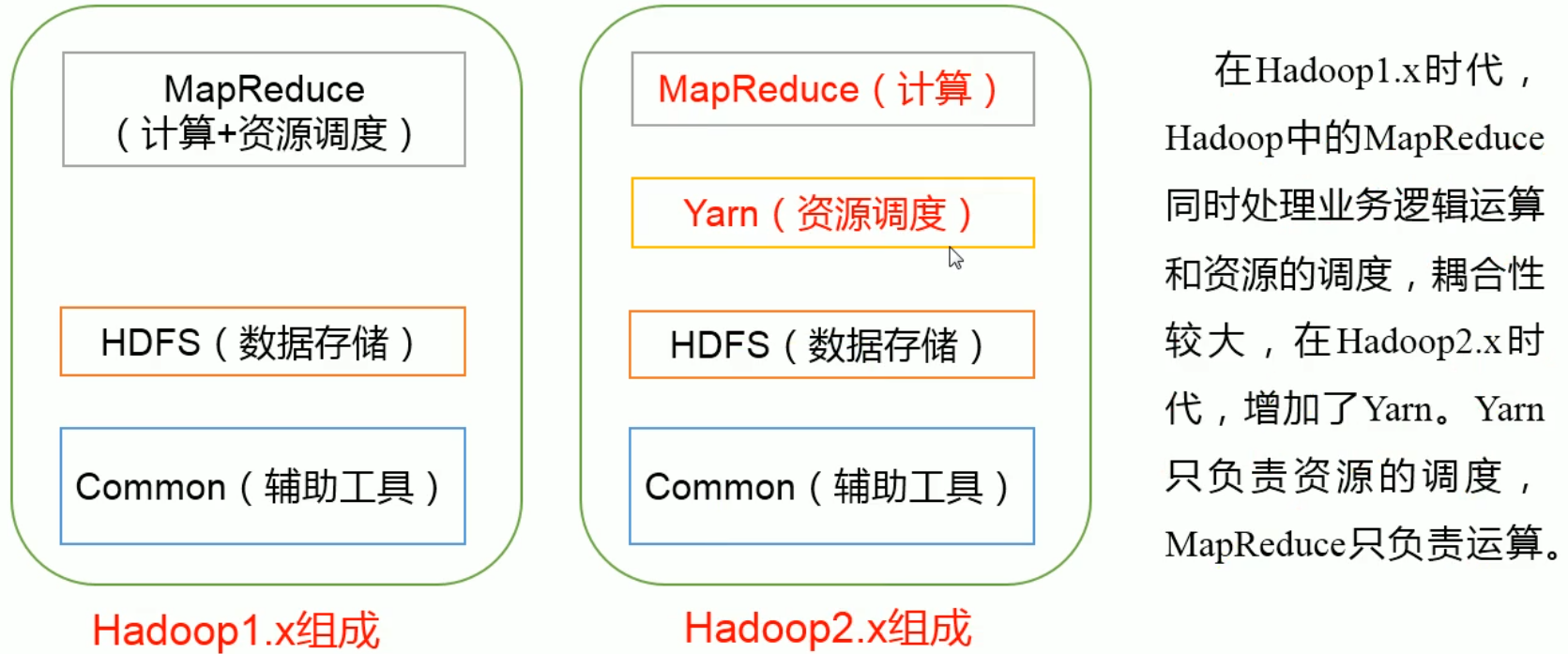
1. 历史版本及组成
2. HDFS(Hadoop Distributed File System 分布式文件系统) 架构概述
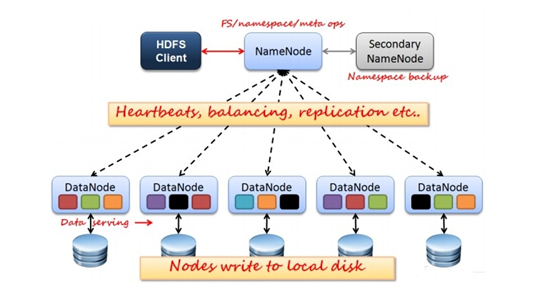
1. NameNode:管理集群当中的各种元数据,如文件名,文件属性(生成时间,副本数等)以及每个文件的块列表和块所在的DataNode等。
2. DataNode:存储集群中的各种块数据到本地文件系统并校验块数据。
3. Secondary NameNode:监控HDFS状态的辅助后台后台程序,每个一段时间获取HDFS元数据快照。
3. Yarn(Yet Another Resource Negotiator 资源管理调度系统) 架构概述

4. MapReduce(分布式运算框架) 架构概述
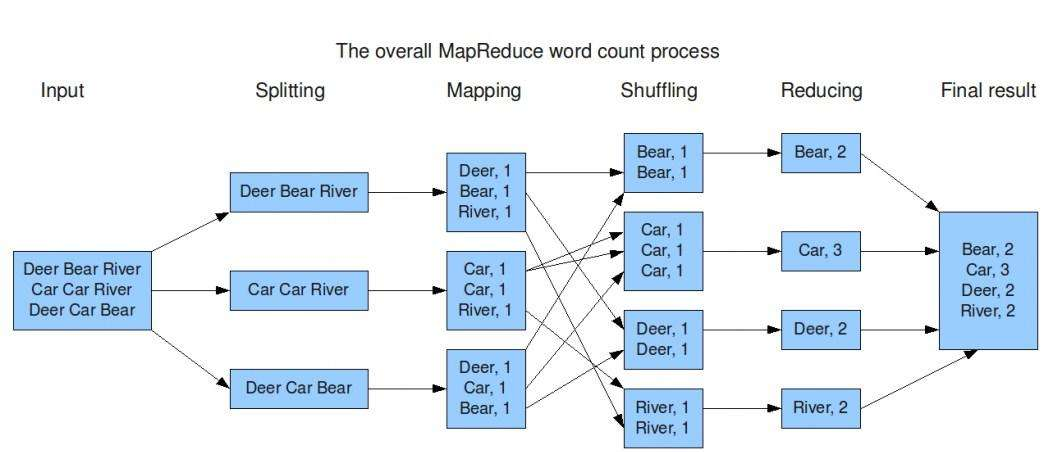
三、Hadoop 生态圈
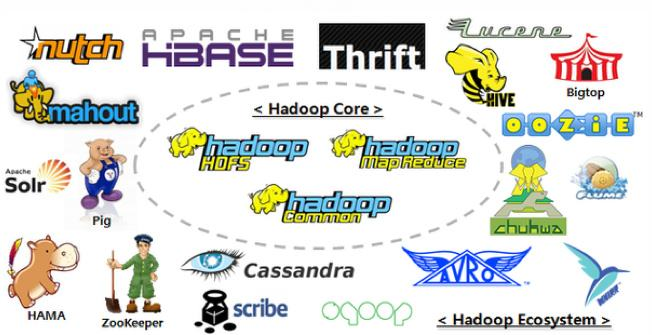
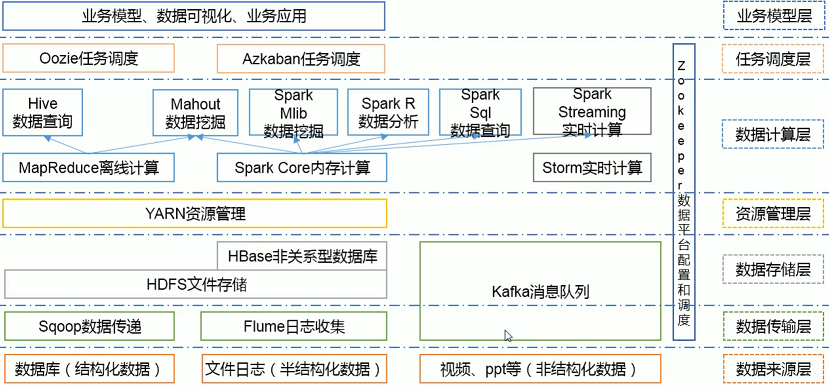
1. HDFS:Hadoop 分布式文件系统(Hadoop Distributed File System),建立在集群之上,适合PB级大量数据的存储,扩展性强,容错性高。
2. MapReduce:Hadoop 的计算框架,由 Map 和 Reduce 两部分组成,由Map生成计算的任务,分配到各个节点上,Reduce执行计算。
3. HBase:源自谷歌的 BigTable,是一个分布式的、面向列存储的开源数据库,性能高,可靠性高,扩展性强。
4. Hive:Hadoop 的数据仓库工具,将个结构化的数据文件映射为一张数据库表,通过类 SQL 语句快速实现简单的 MapReduce 统计,十分适合数据仓库统计。
5. Sqoop:Hadoop 的数据同步工具,将关系型数据库(MySQL、Oracle等)中的数据表和 HDFS 中的文件进性相互导入导出。
6. Flume:Hadoop 的日志收集工具,一个分布式、可靠的、高可用的海量日志聚合系统,用于日志数据收集、处理和传输。
7. Zookeeper:Hadoop 的分布式协作服务,主要作用于统一命名、状态同步、集群管理、配置同步,简化分布式应用协调及其管理难度,提供高性能的分布式服务。
8. Mahout:Hadoop 的机器学习和数据挖掘算法库,实现了大量数据挖掘算法,解决了并行挖掘的问题。
9. Spark:Hadoop 的内存计算框架,为大规模数据处理而设计的快速通用的计算引擎。
10. Pig:Hadoop的大规模数据分析工具,类似于Hive,它提供了 Plight 语言将类 SQL 的数据分析请求转化为一系列经过优化的 MapReduce 运算。
11. Ambari:一种基于Web的工具,支持Hadoop集群的供应、管理和监控等统一部署。
四、Hadoop 实际应用
1. Hadoop+HBase建立NoSQL分布式数据库应用
2. Flume+Hadoop+Hive建立离线日志分析系统
3. Flume+Logstash+Kafka+Spark Streaming进行实时日志处理分析
4. 在线旅游、移动数据、电子商务、IT安全、医疗保健、图像处理等

三:Hadoop 安装部署(3.1.3版本)
一、伪分布式模式(单节点)
1. 安装并配置 JDK 及 Hadoop
1 # 安装并配置 JDK 2 [root@master ~]# tar -zxvf jdk-8u251-linux-x64.tar.gz -C /usr/local/ 3 ...... 4 [root@master ~]# vi /etc/profile 5 # JAVA_HOME 6 export JAVA_HOME=/usr/local/jdk1.8.0_251 7 export PATH=$PATH:$JAVA_HOME/bin 8 9 # 安装并配置 Hadoop 10 [root@master ~]# tar -zxvf hadoop-3.1.3.tar.gz -C /usr/local/ 11 ...... 12 [root@master ~]# vi /etc/profile 13 # HADOOP_HOME 14 export HADOOP_HOME=/usr/local/hadoop-3.1.3/ 15 export PATH=$PATH:$HADOOP_HOME/bin 16 export PATH=$PATH:$HADOOP_HOME/sbin 17 18 # 生效配置文件并校验 19 [root@master ~]# source /etc/profile 20 [root@master ~]# java -version 21 java version "1.8.0_251" 22 Java(TM) SE Runtime Environment (build 1.8.0_251-b08) 23 Java HotSpot(TM) 64-Bit Server VM (build 25.251-b08, mixed mode) 24 25 [root@master ~]# hadoop version 26 Hadoop 3.1.3 27 Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r ba631c436b806728f8ec2f54ab1e289526c90579 28 Compiled by ztang on 2019-09-12T02:47Z 29 Compiled with protoc 2.5.0 30 From source with checksum ec785077c385118ac91aadde5ec9799 31 This command was run using /usr/local/hadoop-3.1.3/share/hadoop/common/hadoop-common-3.1.3.jar
2. 部署HDFS(端口:9870)
1 # 配置集群 2 ### 配置:hadoop-env.sh 3 [root@master ~]# vi /usr/local/hadoop-3.1.3/etc/hadoop/hadoop-env.sh 4 export JAVA_HOME=/usr/local/jdk1.8.0_251 5 6 ### 配置:core-site.xml 7 [root@master ~]# vi +20 /usr/local/hadoop-3.1.3/etc/hadoop/core-site.xml 8 <configuration> 9 <!-- 指定HDFS中NameNode的地址 --> 10 <property> 11 <name>fs.defaultFS</name> 12 <value>hdfs://master:9000</value> 13 </property> 14 15 <!-- 指定Hadoop运行时产生文件的存储目录 --> 16 <property> 17 <name>hadoop.tmp.dir</name> 18 <value>file:/usr/local/hadoop-3.1.3/data/tmp/</value> 19 </property> 20 </configuration> 21 22 ### 配置:hdfs-site.xml 23 [root@master ~]# vi +20 /usr/local/hadoop-3.1.3/etc/hadoop/hdfs-site.xml 24 <configuration> 25 <!-- 指定HDFS副本的数量 --> 26 <property> 27 <name>dfs.replication</name> 28 <value>1</value> 29 </property> 30 31 <!-- 指定 NameNode 存储地址 --> 32 <property> 33 <name>dfs.namenode.name.dir</name> 34 <value>file:/usr/local/hadoop-3.1.3/tmp/dfs/name</value> 35 </property> 36 37 <!-- 指定 DataNode 存储地址 --> 38 <property> 39 <name>dfs.datanode.data.dir</name> 40 <value>file:/usr/local/hadoop-3.1.3/tmp/dfs/data</value> 41 </property> 42 </configuration> 43 44 # 启动集群 45 [root@master ~]# hdfs --daemon start namenode 46 [root@master ~]# hdfs --daemon start datanode 47 [root@master ~]# jps 48 11202 NameNode 49 11322 DataNode 50 11646 Jps 51 52 # 访问集群web界面(3.1.3版本新端口) 53 [root@master ~]# curl http://master:9870 54 <!-- 55 Licensed to the Apache Software Foundation (ASF) under one or more 56 contributor license agreements. See the NOTICE file distributed with 57 this work for additional information regarding copyright ownership. 58 The ASF licenses this file to You under the Apache License, Version 2.0 59 (the "License"); you may not use this file except in compliance with 60 the License. You may obtain a copy of the License at 61 62 http://www.apache.org/licenses/LICENSE-2.0 63 64 Unless required by applicable law or agreed to in writing, software 65 distributed under the License is distributed on an "AS IS" BASIS, 66 WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. 67 See the License for the specific language governing permissions and 68 limitations under the License. 69 --> 70 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" 71 "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> 72 <html xmlns="http://www.w3.org/1999/xhtml"> 73 <head> 74 <meta http-equiv="REFRESH" content="0;url=dfshealth.html" /> 75 <title>Hadoop Administration</title> 76 </head> 77 </html>

3. 部署YARN(端口:8088)
1 # 配置 2 ### 配置:mapred-site.xml(MR) 3 [root@master ~]# vi +20 /usr/local/hadoop-3.1.3/etc/hadoop/mapred-site.xml 4 <configuration> 5 <!-- 指定 MR 在 YARN上运行 --> 6 <property> 7 <name>mapreduce.framework.name</name> 8 <value>yarn</value> 9 </property> 10 11 <!-- 指定 MR 应用程序路径 --> 12 <property> 13 <name>mapreduce.application.classpath</name> 14 <value>$HADOOP_HOME/share/hadoop/mapreduce/*:$HADOOP_HOME/share/hadoop/mapreduce/lib/*</value> 15 </property> 16 </configuration> 17 18 19 ### 配置:yarn-site.xml 20 [root@master ~]# vi +16 /usr/local/hadoop-3.1.3/etc/hadoop/yarn-site.xml 21 <configuration> 22 <!-- 指定 Reducer 获取数据的方式 --> 23 <property> 24 <name>yarn.nodemanager.aux-services</name> 25 <value>mapreduce_shuffle</value> 26 </property> 27 28 <!-- 指定 YARN 的 ResourceManager 的地址 --> 29 <property> 30 <name>yarn.resourcemanager.hostname</name> 31 <value>master</value> 32 </property> 33 34 <!-- 指定 NodeManagers 继承的环境属性 --> 35 <property> 36 <name>yarn.nodemanager.env-whitelist</name> 37 <value>JAVA_HOME,HADOOP_HOME</value> 38 </property> 39 </configuration> 40 41 # 启动集群 42 [root@master ~]# yarn --daemon start resourcemanager 43 [root@master ~]# yarn --daemon start nodemanager 44 [root@master ~]# jps 45 12691 DataNode 46 20278 Jps 47 20136 NodeManager 48 12585 NameNode 49 19837 ResourceManager 50 51 # 查看 52 [root@master ~]# curl http://master:8088/cluster 53 ......
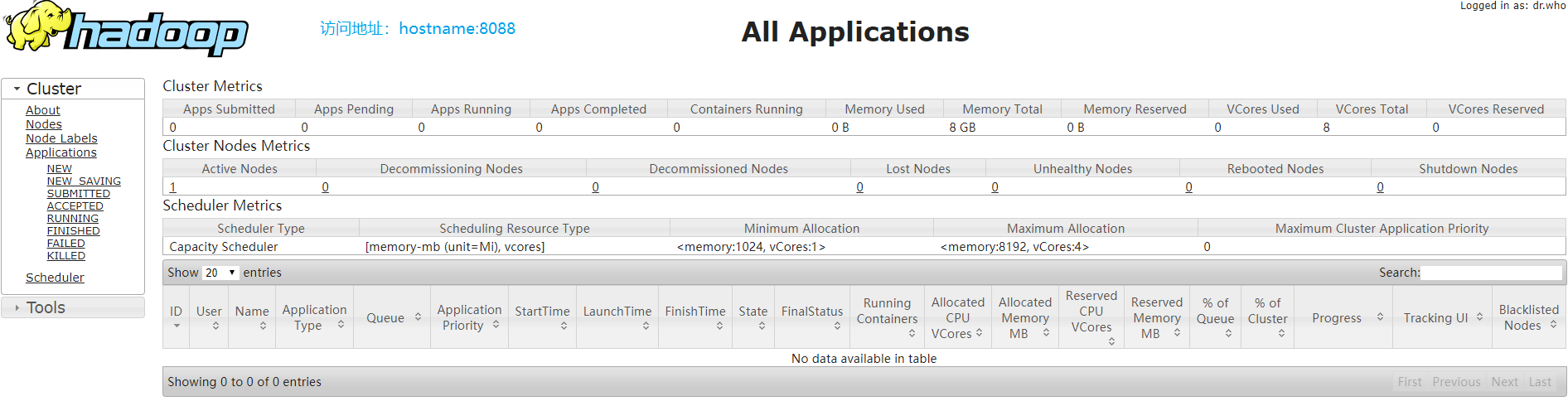
4. 配置历史服务器和日志聚集(端口:19888)
1 # 配置历史服务器 2 [root@master ~]# vi /usr/local/hadoop-3.1.3/etc/hadoop/mapred-site.xml 3 <configuration> 4 <!-- 历史服务器端地址 --> 5 <property> 6 <name>mapreduce.jobhistory.address</name> 7 <value>master:10020</value> 8 </property> 9 10 <!-- 历史服务器web端地址 --> 11 <property> 12 <name>mapreduce.jobhistory.webapp.address</name> 13 <value>master:19888</value> 14 </property> 15 </configuration> 16 17 # 配置日志聚集 18 [root@master ~]# vi /usr/local/hadoop-3.1.3/etc/hadoop/yarn-site.xml 19 <configuration> 20 <!-- 日志聚集功能使能 --> 21 <property> 22 <name>yarn.log-aggregation-enable</name> 23 <value>true</value> 24 </property> 25 26 <!-- 日志保留时间设置7天 --> 27 <property> 28 <name>yarn.log-aggregation.retain-seconds</name> 29 <value>604800</value> 30 </property> 31 </configuration> 32 33 # 启动 34 [root@master ~]# yarn --daemon stop resourcemanager 35 [root@master ~]# yarn --daemon stop nodemanager 36 [root@master ~]# yarn --daemon start resourcemanager 37 [root@master ~]# yarn --daemon start nodemanager 38 [root@master ~]# mapred --daemon start historyserver 39 [root@master ~]# jps 40 12691 DataNode 41 20136 NodeManager 42 20824 Jps 43 12585 NameNode 44 20780 JobHistoryServer 45 19837 ResourceManager
二、完全分布式模式(集群)
1. 配置 xsync 集群分发脚本(关闭防火墙)
1 # 配置主机地址映射 2 [root@master ~]# cat /etc/hosts 3 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 5 10.0.0.18 master 6 10.0.0.15 slaver1 7 10.0.0.16 slaver2 8 9 # 配置 xsync 脚本 10 [root@master ~]# vi /usr/local/bin/xsync 11 #! /bin/bash 12 13 # 1、获取输入参数个数,如果没有参数,直接退出 14 pcount=$# 15 if((pcount==0)); then 16 echo no args; 17 exit; 18 fi 19 20 #2、获取文件名称 21 p1=$1 22 fname=`basename $p1` 23 echo fname=$fname 24 25 # 3、获取上级目录到绝对路径 26 pdir=`cd -P $(dirname $p1); pwd` 27 echo pdir=$pdir 28 29 # 4、获取当前用户名称 30 user=`whoami` 31 32 # 5、循环 33 for((host=1; host<5; host++)); do 34 echo ------------------- slaver$host -------------- 35 rsync -rvl $pdir/$fname $user@slaver$host:$pdir 36 done 37 38 # 修改执行权限 39 [root@master ~]# chmod 777 /usr/local/bin/xsync 40 41 # 使用 42 [root@master ~]# xsync /usr/local/jdk1.8.0_251/ 43 [root@master ~]# xsync /usr/local/hadoop-3.1.3/ 44 [root@master ~]# xsync /etc/profile
2. 配置无密登录及时钟同步
1 # 生成公钥和私钥 2 [root@master ~]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa 3 Generating public/private dsa key pair. 4 Your identification has been saved in /root/.ssh/id_dsa. 5 Your public key has been saved in /root/.ssh/id_dsa.pub. 6 The key fingerprint is: 7 0c:7d:46:22:0e:d3:b0:1f:31:32:b6:5d:2a:a7:ff:85 root@master 8 The key's randomart image is: 9 +--[ DSA 1024]----+ 10 | Bo+ o . | 11 | . X.B o | 12 | + B . o | 13 | = + o | 14 | . . S | 15 | . . | 16 | . E . | 17 | . . | 18 | . | 19 +-----------------+ 20 [root@master ~]# cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys 21 [root@master ~]# chmod 0600 ~/.ssh/authorized_keys 22 23 # 将公钥拷贝到要免密登录的目标机器 24 [root@master ~]# ssh-copy-id slaver1 25 The authenticity of host 'slaver1 (192.168.200.55)' can't be established. 26 ECDSA key fingerprint is 37:48:34:56:ad:65:08:c1:0b:53:35:ce:fc:4f:c0:3e. 27 Are you sure you want to continue connecting (yes/no)? yes 28 /usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed 29 /usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys 30 root@slaver1's password: 31 32 Number of key(s) added: 1 33 34 Now try logging into the machine, with: "ssh 'slaver1'" 35 and check to make sure that only the key(s) you wanted were added. 36 37 # 测试无密登录 38 [root@master ~]# ssh slaver1 39 Last login: Thu Dec 15 14:34:49 2016 40 41 ######################### 42 # Welcome to XianDian # 43 ######################### 44 45 [root@slaver1~]# 46 47 # 配置 ntp 时钟同步服务器 48 ## 主节点(master) 49 ### 安装 ntp 服务 50 [root@master ~]# yum install -y ntp 51 ... 52 53 ### 修改ntp 配置文件(删除server和restrict 开头的) 54 [root@master ~]# vi /etc/ntp.conf 55 server 127.127.1.0 56 fudge 127.127.1.0 stratum 10 57 58 ## 其他节点进行同步 59 ### 安装同步客户端 60 [root@master ~]# yum install -y ntpdate 61 ### 同步 (-0.xxx以内) 62 [root@slaver1 ~]# ntpdate master 63 3 Jun 11:51:59 ntpdate[1121]: adjust time server 172.16.21.212 offset -0.000439 sec
3. 配置集群
1 # 配置集群群起:workers(添加从节点) 2 [root@master ~]# vi /usr/local/hadoop-3.1.3/etc/hadoop/workers 3 slaver1 4 slaver2 5 6 # 配置环境变量:hadoop-env.sh 7 [root@master ~]# vi /usr/local/hadoop-3.1.3/etc/hadoop/hadoop-env.sh 8 export JAVA_HOME=/usr/local/jdk1.8.0_251 9 export HADOOP_HOME=/usr/local/hadoop-3.1.3 10 export HDFS_NAMENODE_USER=root 11 export HDFS_DATANODE_USER=root 12 export HDFS_SECONDARYNAMENODE_USER=root 13 export YARN_RESOURCEMANAGER_USER=root 14 export YARN_NODEMANAGER_USER=root 15 16 # 核心配置文件:core-site.xml (运行环境) 17 [root@master ~]# vi /usr/local/hadoop-3.1.3/etc/hadoop/core-site.xml 18 <configuration> 19 <!-- 指定HDFS中NameNode的地址 --> 20 <property> 21 <name>fs.defaultFS</name> 22 <value>hdfs://master:9000</value> 23 </property> 24 25 <!-- 指定Hadoop运行时产生文件的存储目录 --> 26 <property> 27 <name>hadoop.tmp.dir</name> 28 <value>/usr/local/hadoop-3.1.3/data/tmp/</value> 29 </property> 30 </configuration> 31 32 # HDFS配置文件:hdfs-site.xml 33 [root@master ~]# vi /usr/local/hadoop-3.1.3/etc/hadoop/hdfs-site.xml 34 <configuration> 35 <!-- 指定 NameNode 存储地址 --> 36 <property> 37 <name>dfs.name.dir</name> 38 <value>/usr/local/hadoop-3.1.3/data/tmp/dfs/name</value> 39 </property> 40 41 <!-- 指定 DataNode 存储地址 --> 42 <property> 43 <name>dfs.data.dir</name> 44 <value>/usr/local/hadoop-3.1.3/data/tmp/dfs/data</value> 45 </property> 46 47 <!-- 指定 Hadoop 主节点主机配置 --> 48 <property> 49 <name>dfs.namenode.http-address</name> 50 <value>master:50070</value> 51 </property> 52 53 <!-- 指定 Hadoop 辅助名称节点主机配置 --> 54 <property> 55 <name>dfs.namenode.secondary.http-address</name> 56 <value>slaver2:50090</value> 57 </property> 58 59 <!-- 指定HDFS副本的数量 --> 60 <property> 61 <name>dfs.replication</name> 62 <value>3</value> 63 </property> 64 65 <!-- 关闭用户操作权限验证 --> 66 <property> 67 <name>dfs.permissions</name> 68 <value>false</value> 69 <description>need not permissions</description> 70 </property> 71 </configuration> 72 73 # YARN配置文件:yarn-site.xml 74 [root@master ~]# vi /usr/local/hadoop-3.1.3/etc/hadoop/yarn-site.xml 75 <configuration> 76 <!-- 指定 Reducer 获取数据的方式 --> 77 <property> 78 <name>yarn.nodemanager.aux-services</name> 79 <value>mapreduce_shuffle</value> 80 </property> 81 82 <!-- 指定 ResourceManager 的地址 --> 83 <property> 84 <name>yarn.resourcemanager.hostname</name> 85 <value>master</value> 86 </property> 87 88 <!-- 指定 NodeManagers 继承的环境属性 --> 89 <property> 90 <name>yarn.nodemanager.env-whitelist</name> 91 <value>JAVA_HOME,HADOOP_HOME</value> 92 </property> 93 94 <!-- 配置 YARN 的资源调度(执行hadoop classpath) --> 95 <property> 96 <name>yarn.application.classpath</name> 97 <value>/usr/local/hadoop-3.1.3/etc/hadoop:/usr/local/hadoop-3.1.3/share/hadoop/common/lib/*:此处省略很之值</value> 98 </property> 99 </configuration> 100 101 # MapReduce配置文件:mapred-site.xml 102 [root@master ~]# vi /usr/local/hadoop-3.1.3/etc/hadoop/mapred-site.xml 103 <configuration> 104 <!-- 指定 MR 在 YARN上运行 --> 105 <property> 106 <name>mapreduce.framework.name</name> 107 <value>yarn</value> 108 </property> 109 110 <!-- 指定 MR 应用程序路径 --> 111 <property> 112 <name>mapreduce.application.classpath</name> 113 <value>$HADOOP_HOME/share/hadoop/mapreduce/*,$HADOOP_HOME/share/hadoop/mapreduce/lib/*</value> 114 </property> 115 </configuration> 116 117 # 分发集群配置文件 118 [root@master ~]# xsync /usr/local/hadoop-3.1.3/etc/ 119 ...... 120 121 # 启动 122 [root@master ~]# start-all.sh # 一次性启动 123 # [root@master ~]# start-dfs.sh 124 # [root@master ~]# start-yarn.sh # resourcemanager部署节点启动 125 [root@master ~]# jps 126 6675 ResourceManager 127 7004 NodeManager 128 6127 NameNode 129 6303 DataNode 130 7471 Jps 131 [root@slaver1 ~]# jps 132 20178 Jps 133 19383 DataNode 134 19563 NodeManager 135 [root@slaver2 ~]# jps 136 17541 SecondaryNameNode 137 16952 DataNode 138 17128 NodeManager 139 17982 Jps
4. 运行 wordcount 案例
1 # 将本地文件上传 2 [root@master ~]# hadoop fs -put test.txt /user/input/ 3 ...... 4 5 # 运行 wordcount 程序 6 [root@master ~]# hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /user/input/ /user/output/ 7 2020-06-04 01:44:45,440 INFO client.RMProxy: Connecting to ResourceManager at master/10.0.0.18:8032 8 2020-06-04 01:44:45,873 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1591233544175_0002 9 2020-06-04 01:44:45,935 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 10 2020-06-04 01:44:46,063 INFO input.FileInputFormat: Total input files to process : 1 11 2020-06-04 01:44:46,085 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 12 2020-06-04 01:44:46,118 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 13 2020-06-04 01:44:46,148 INFO mapreduce.JobSubmitter: number of splits:1 14 2020-06-04 01:44:46,266 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 15 2020-06-04 01:44:46,307 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1591233544175_0002 16 2020-06-04 01:44:46,307 INFO mapreduce.JobSubmitter: Executing with tokens: [] 17 2020-06-04 01:44:46,489 INFO conf.Configuration: resource-types.xml not found 18 2020-06-04 01:44:46,489 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'. 19 2020-06-04 01:44:46,549 INFO impl.YarnClientImpl: Submitted application application_1591233544175_0002 20 2020-06-04 01:44:46,577 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1591233544175_0002/ 21 2020-06-04 01:44:46,577 INFO mapreduce.Job: Running job: job_1591233544175_0002 22 2020-06-04 01:44:51,703 INFO mapreduce.Job: Job job_1591233544175_0002 running in uber mode : false 23 2020-06-04 01:44:51,705 INFO mapreduce.Job: map 0% reduce 0% 24 2020-06-04 01:44:55,790 INFO mapreduce.Job: map 100% reduce 0% 25 2020-06-04 01:45:00,934 INFO mapreduce.Job: map 100% reduce 100% 26 2020-06-04 01:45:00,956 INFO mapreduce.Job: Job job_1591233544175_0002 completed successfully 27 2020-06-04 01:45:01,079 INFO mapreduce.Job: Counters: 53 28 File System Counters 29 FILE: Number of bytes read=33 30 FILE: Number of bytes written=436328 31 FILE: Number of read operations=0 32 FILE: Number of large read operations=0 33 FILE: Number of write operations=0 34 HDFS: Number of bytes read=118 35 HDFS: Number of bytes written=19 36 HDFS: Number of read operations=8 37 HDFS: Number of large read operations=0 38 HDFS: Number of write operations=2 39 Job Counters 40 Launched map tasks=1 41 Launched reduce tasks=1 42 Data-local map tasks=1 43 Total time spent by all maps in occupied slots (ms)=1369 44 Total time spent by all reduces in occupied slots (ms)=2565 45 Total time spent by all map tasks (ms)=1369 46 Total time spent by all reduce tasks (ms)=2565 47 Total vcore-milliseconds taken by all map tasks=1369 48 Total vcore-milliseconds taken by all reduce tasks=2565 49 Total megabyte-milliseconds taken by all map tasks=1401856 50 Total megabyte-milliseconds taken by all reduce tasks=2626560 51 Map-Reduce Framework 52 Map input records=1 53 Map output records=2 54 Map output bytes=23 55 Map output materialized bytes=33 56 Input split bytes=103 57 Combine input records=2 58 Combine output records=2 59 Reduce input groups=2 60 Reduce shuffle bytes=33 61 Reduce input records=2 62 Reduce output records=2 63 Spilled Records=4 64 Shuffled Maps =1 65 Failed Shuffles=0 66 Merged Map outputs=1 67 GC time elapsed (ms)=87 68 CPU time spent (ms)=830 69 Physical memory (bytes) snapshot=518791168 70 Virtual memory (bytes) snapshot=5129560064 71 Total committed heap usage (bytes)=383254528 72 Peak Map Physical memory (bytes)=294596608 73 Peak Map Virtual memory (bytes)=2557661184 74 Peak Reduce Physical memory (bytes)=224194560 75 Peak Reduce Virtual memory (bytes)=2571898880 76 Shuffle Errors 77 BAD_ID=0 78 CONNECTION=0 79 IO_ERROR=0 80 WRONG_LENGTH=0 81 WRONG_MAP=0 82 WRONG_REDUCE=0 83 File Input Format Counters 84 Bytes Read=15 85 File Output Format Counters 86 Bytes Written=19 87 88 # 查看结果 89 [root@master ~]# hadoop fs -cat /user/output/part-r-00000 90 2020-06-04 01:48:42,894 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 91 Hello 1 92 world!!! 1
四:Hadoop 源码编译
一、环境准备
1. Hadoop :hadoop-3.1.3-src.tar.gz
2. JDK:jdk-8u231-linux-x64.tar.gz (1.8及以上版本)
3. Maven:apache-maven-3.6.2-bin.tar.gz (3.5及以上版本)
4. Protobuf:protobuf-2.5.0.tar.gz (网页最下面,必须是2.5.0版本)
5. Cmake:cmake-3.13.5.tar.gz(3.13.0及以上版本)
6. Ant:apache-ant-1.10.7-bin.tar.gz(可不安装,版本1.10.8)
7. Findbugs:findbugs-3.0.1.tar.gz (可不安装,3.0.1版本)
二、安装
1 # 安装下载软件 2 [root@master ~]# tar -zxvf jdk-8u251-linux-x64.tar.gz -C /usr/local/ 3 [root@master ~]# tar -zxvf hadoop-3.1.3-src.tar.gz -C /usr/local/ 4 [root@master ~]# tar -zxvf apache-maven-3.6.3-bin.tar.gz -C /usr/local 5 [root@master ~]# tar -zxvf cmake-3.13.5.tar.gz -C /usr/local 6 [root@master ~]# tar -zxvf apache-ant-1.10.8-bin.tar.gz -C /usr/local/ 7 8 # 安装依赖软件(顺序不能乱) 9 [root@master ~]# yum install -y gcc gcc-c++ 10 [root@master ~]# yum install -y autoconf automake libtool curl 11 [root@master ~]# yum install -y lzo-devel zlib-devel openssl openssl-devel ncurses-devel 12 [root@master ~]# yum install -y lzo-devel zlib-devel openssl openssl-devel ncurses-devel 13 14 # 安装Protobuf 15 [root@master ~]# tar -zxvf protobuf-2.5.0.tar.gz 16 [root@master ~]# ./protobuf-2.5.0/configure --prefix=/usr/local/18 [root@master ~]# make && make install #时间很长,耐心等待 20 21 # 配置环境变量
[root@master ~]# source /etc/profile 22 # JAVA_HOME 23 export JAVA_HOME=/usr/local/jdk1.8.0_251 24 export PATH=$PATH:$JAVA_HOME/bin 25 26 # HADOOP_HOME 27 export HADOOP_HOME=/usr/local/hadoop-3.1.3 28 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin 29 30 # MAVEN_HOME 31 export MAVEN_HOME=/usr/local/apache-maven-3.6.3 32 export PATH=$PATH:$MAVEN_HOME/bin 33 34 # PROTOC_HOME 35 export PROTOC_HOME= 36 37 # ANT_HOME 38 export ANT_HOME=/usr/local/apache-ant-1.10.8 39 export PATH=$PATH:$ANT_HOME/bin 40 41 # 生效配置文件并测试 42 [root@master ~]# source /etc/profile 43 [root@master ~]# java -version 44 java version "1.8.0_251" 45 Java(TM) SE Runtime Environment (build 1.8.0_251-b08) 46 Java HotSpot(TM) 64-Bit Server VM (build 25.251-b08, mixed mode) 47 [root@master ~]# mvn -v 48 Apache Maven 3.6.3 (cecedd343002696d0abb50b32b541b8a6ba2883f) 49 Maven home: /usr/local/apache-maven-3.6.3 50 Java version: 1.8.0_251, vendor: Oracle Corporation, runtime: /usr/local/jdk1.8.0_251/jre 51 Default locale: en_US, platform encoding: UTF-8 52 OS name: "linux", version: "3.10.0-229.el7.x86_64", arch: "amd64", family: "unix" 53 [root@master ~]# protoc --version 54 libprotoc 2.5.0 55 [root@master ~]# ant -version 56 Apache Ant(TM) version 1.10.8 compiled on May 10 2020
57
58 # 进入 hadoop 源码包执行 Maven 命令(第一次编译需要很长时间,一般在一到二个小时)
59 [root@master hadoop-3.1.3-src]# mvn clean package -DskipTests -Pdist,native -Dtar
60 ......
61 # 编译好的源码包在hadoop-3.1.3-src/hadoop-dist/target里面
62