线性表的基本特征:
- 第一个数据元素没有前驱元素;
- 最后一个数据元素没有后继元素;
- 其余每个数据元素只有一个前驱元素和一个后继元素。
线性表按物理存储结构的不同可分为顺序表(顺序存储)和链表(链式存储):
- 顺序表(存储结构连续,数组实现)
- 链表(存储结构上不连续,逻辑上连续)
顺序表是在计算机内存中以数组的形式保存的线性表,是指用一组地址连续的存储单元依次存储数据元素的线性结构。线性表采用顺序存储的方式存储就称之为顺序表。
插入删除操作如图:
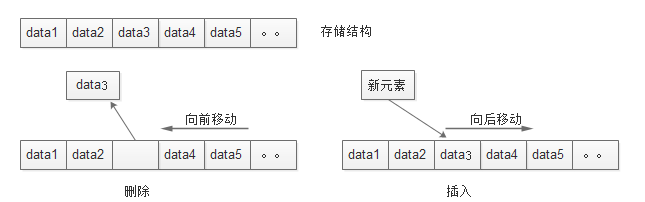
抽象数据类型(ADT)是指一个数学模型及定义在该模型上的一组操作。于Java语言中的抽象类和接口设计理念是想通的。
abstract class SequenceListAbst{ //顺序表
private static final int DEFAULT_CAPACITY=10;
private int size;
private Object[] elements; //Object数组
public SequenceListAbst(){
size=0;
elements=new Object[DEFAULT_CAPACITY];
}
//顺序表大小
public abstract int size();
//判断是否是空
public abstract boolean isEmpty();
//清空顺序表
public abstract void clear();
//在index处添加元素
public abstract void add(int index, Object element);
//删除指定索引的元素
public abstract boolean delete(int index);
//获取指定索引的元素
public abstract Object get(int index);
//遍历链表
public abstract void iterator();
}
具体的代码省略...
顺序表效率分析:
- 顺序表插入和删除一个元素,最好情况下其时间复杂度(这个元素在最后一个位置)为O(1),最坏情况下其时间复杂度为O(n)。
- 顺序表支持随机访问,读取一个元素的时间复杂度为O(1)。
顺序表的优缺点:
- 优点:支持随机访问
- 缺点:插入和删除操作需要移动大量的元素,造成存储空间的碎片。
顺序表适合元素个数变化不大,且更多是读取数据的场合。
扩展:
Java中AarrayList是系统实现的顺序表,它是一个动态数组。添加时会有扩容,删除时会有缩容。
扩容:通过无参构造的话,初始数组容量根据JDK版本不同策略不同,每次通过copeOf的方式扩容后容量为原来的1.5倍。
缩容:ArrayList不会自动缩小容积,有一个方法 trimToSize 可以缩小容积。
其他描述:
ArrayList是基于数组实现的,是一个动态数组,其容量能自动增长。
ArrayList不是线程安全的,只能用在单线程环境下。
实现了Serializable接口,因此它支持序列化,能够通过序列化传输;
实现了RandomAccess接口,支持快速随机访问,实际上就是通过下标序号进行快速访问;
实现了Cloneable接口,能被克隆。链表(LinkedList)通常由一连串节点组成,每个节点包含任意的实例数据(data fields)和一或两个用来指向上一个/或下一个节点的位置的链接("links")
链表是一种常见的基础数据结构,是一种线性表,但是并不会按线性的顺序存储数据,而是在每一个节点里存放指向下一个节点的指针(Pointer),Java中称之为引用。
使用链表结构可以克服数组链表需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。但是链表失去了数组随机读取的优点,同时链表由于增加了结点的指针域,空间开销比较大。
(1)单链表是链表中结构最简单的。一个单链表的节点(Node)分为两个部分,第一个部分(data)保存或者显示关于节点的信息,另一个部分存储下一个节点的地址。最后一个节点存储地址的部分指向空值。
单链表有带头结点和不带头结点两种结构,其结构如下
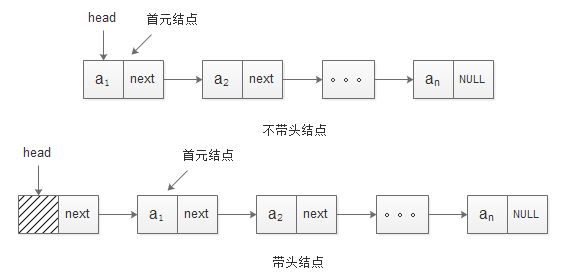
由于带头结点的链表更容易操作,这里仅实现带头结点的单链表
带头结点的链表插入与删除示意图:
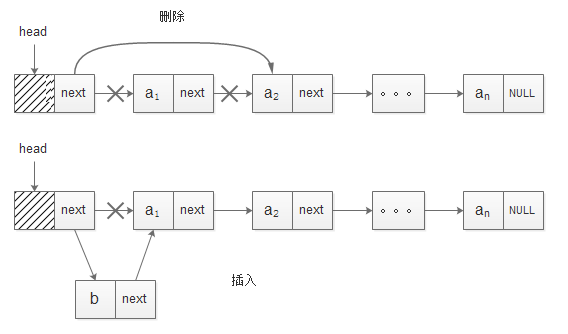
抽象数据类型(ADT)是指一个数学模型及定义在该模型上的一组操作。于Java语言中的抽象类和接口设计理念是想通的。
abstract class SingleLinkedListAbst{ //单链表
protected int size; //链表节点的个数
protected Node head; //头节点
//链表的每个节点类
protected class Node{ //内部类
protected Object data; //每个节点的数据
protected Node next; //每个节点指向下一个节点的引用
public Node(Object data){
this.data=data;
}
}
//单链表的大小
public abstract int size();
//判断链表是否为空
public abstract boolean isEmpty();
//在链表index处添加元素
public abstract void add(int index, Object element);
//删除指定索引的元素
public abstract boolean delete(int index);
//判断元素是否存在
public abstract boolean exist(Object obj);
//查找元素,根据索引index返回节点Node
public abstract Node get(int index);
//遍历链表
public abstract void print();
}
具体的代码:
class SingleLinkedList extends SingleLinkedListAbst{ //实现单链表
public SingleLinkedList(){ //构造方法初始化一个头结点
head=new Node("head");
head.next=null;
size=0;
}
@Override
public int size() {
return size;
}
@Override
public boolean isEmpty() {
return size==0;
}
@Override
public void add(int index, Object element) {
if(index<0 || index>size){
throw new IndexOutOfBoundsException("参数输入错误:"+index);
}
//找到索引index结点之前的结点
Node before=head;
int temp=index;
while(temp-->0){
before=before.next;
}
//构造新的待插入结点
Node newNode=new Node(element);
//若索引index处的结点不存在,就在最后插入
if(index==(size+1)){
before=newNode;
newNode.next=null;
size++;
return;
}
//插入结点(断开旧引用,构造新的引用)
Node after=before.next;
before.next=newNode;
newNode.next=after;
size++;
}
@Override
public boolean delete(int index) {
// TODO Auto-generated method stub
return false;
}
@Override
public boolean exist(Object obj) {
// TODO Auto-generated method stub
return false;
}
@Override
public Node get(int index) {
// TODO Auto-generated method stub
return null;
}
@Override
public void print() {
Node currentNode=head.next;
if(currentNode==null){
return;
}
int temp=size;
while(temp--!=0){ //循环
System.out.println((String)currentNode.data);
currentNode=currentNode.next;
}
}
}
此处由于时间原因作者只写了一部分,如是想提升能力的读者必然是全部写完。
单链表效率分析:
在单链表上插入和删除数据时,首先需要找出插入或删除元素的位置。对于单链表其查找操作的时间复杂度为 O(n),所以
-
链表插入和删除操作的时间复杂度均为 O(n)
-
链表读取操作的时间复杂度为 O(n)
单链表优缺点:
- 优点:不需要预先给出数据元素的最大个数,单链表插入和删除操作不需要移动数据元素
- 缺点:不支持随机读取,读取操作的时间复杂度为 O(n)
(2)单向循环链表
将单链表中终端结点的指针指向头结点,使整个单链表形成一个环,这种头尾相接的单链表称为单循环链表,简称循环链表。
对于循环链表,为了使空链表与非空链表处理一致,通常设一个头结点。如图:
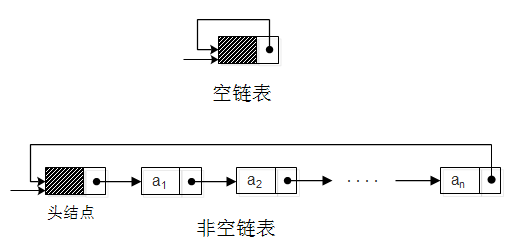
循环链表和单链表的主要差异在于链表结束的判断条件不同,单链表为current.next是否为空,而循环链表为current.next不等于头结点。对于循环链表的增删改查操作与单链表基本相同,仅仅需要将链表结束的条件变成current.next != head即可。
(3)双向链表
双向链表是在单链表的每个结点中,再设置一个指向其前驱结点的指针域。使得两个指针域一个指向其前驱结点,一个指向其后继结点。
对于双向链表,其空和非空结构如下图:

双向链表是单链表扩展出来的结构,它可以反向遍历、查找元素,它的很多操作和单链表相同,比如求长度size()、查找元素get()。这些操作只涉及一个方向的指针即可。插入和删除操作时,需要更改两个指针变量。
插入操作:注意操作顺序
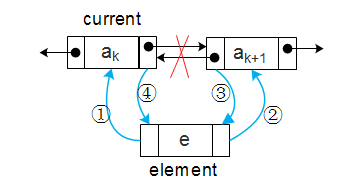
双向链表相对于单链表来说占用了更多的空间,但由于其良好的对称性,使得能够方便的访问某个结点的前后结点,提高了算法的时间性能。是用空间换时间的一个典型应用。
很多代码的实现没有写完,如是想提升能力的读者必然是全部写完(附:对于数据结构初学者(已熟练驾驭编程语言本身),链表的编写必然是熬三天三夜才能搞清楚脉络的)。
温馨提示:看的懂和能写出来绝对是两回事!