crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址
有多网站,当你浏览器访问时看到的信息,在html源文件里却找不到,由得信息还是滚动条滚动到对应的位置后才显示信息,那么这种一般都是 js 的 Ajax 动态请求生成的信息
我们以百度新闻为列:
1、分析网站
首先我们浏览器打开百度新闻,在网页中间部分找一条新闻信息

然后查看源码,看看在源码里是否有这条新闻,可以看到源文件里没有这条信息,这种情况爬虫是无法爬取到信息的
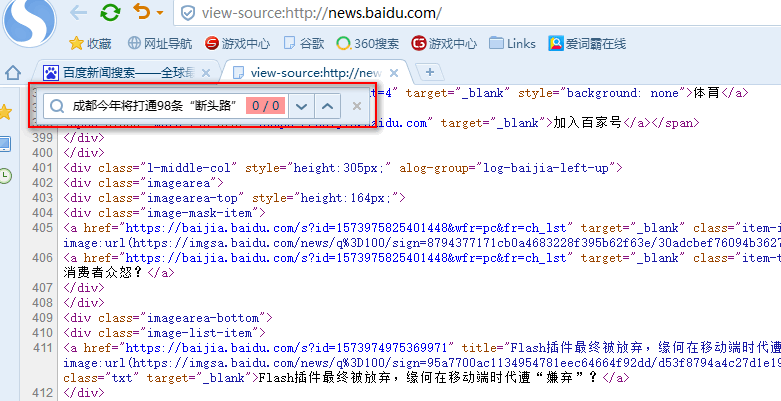
那么我们就需要抓包分析了,启动抓包软件和抓包浏览器,前后有说过软件了,就不在说了,此时我们经过抓包看到这条信息是通过Ajax动态生成的JSON数据,也就是说,当html页面加载完成后才生成的,所有我们在源文件里无法找到,当然爬虫也找不到
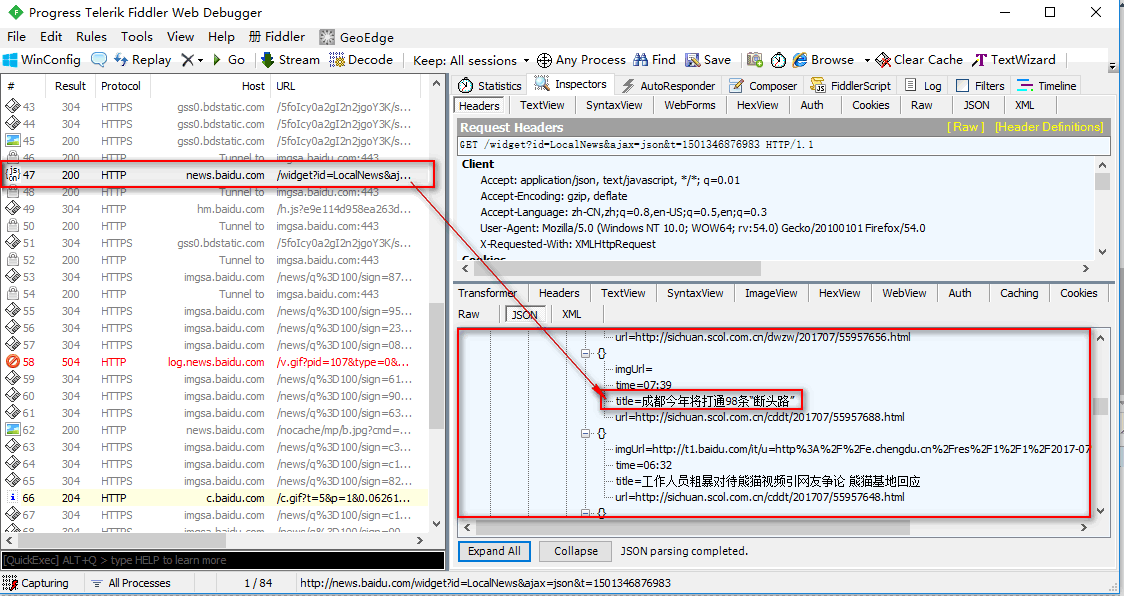
我们首先将这个JSON数据网址拿出来,到浏览器看看,我们需要的数据是不是全部在里面,此时我们看到这次请求里只有 17条信息,显然我们需要的信息不是完全在里面,还得继续看看其他js包
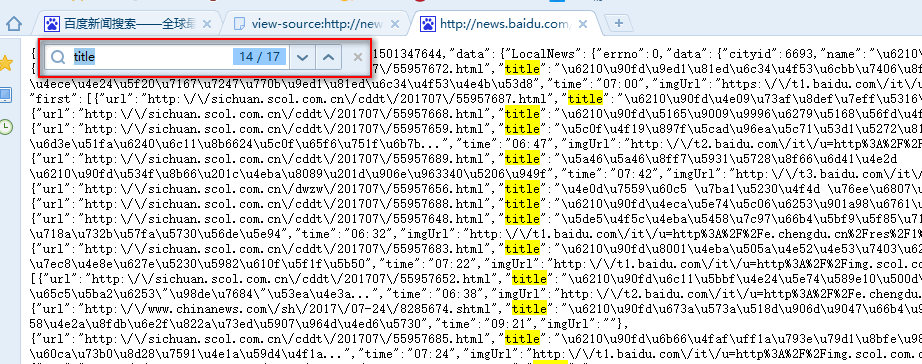
我们将抓包浏览器滚动条拉到底,以便触发所有js请求,然后在继续找js包,我们将所有js包都找完了再也没看到新闻信息的包了
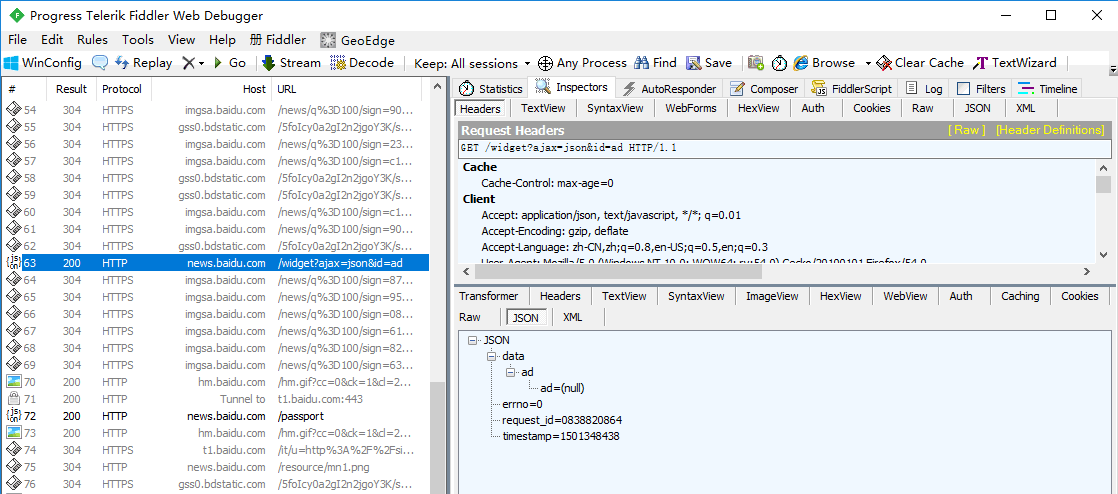
那信息就不在js包里了,我们回头在看看其他类型的请求,此时我们看到很多get请求响应的是我们需要的新闻信息,说明只有第一次那个Ajax请求返回的JSON数据,后面的Ajax请求返回的都是html类型的字符串数据,
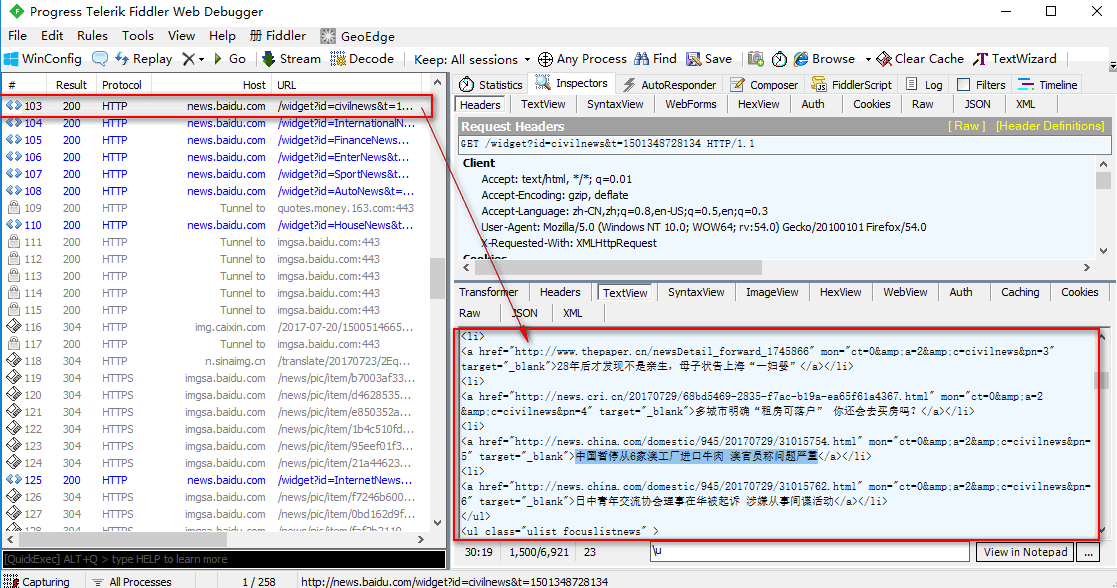
我们将Ajax请求返回的JSON数据的网址和Ajax请求返回html类型的字符串数据网址,拿来做一下比较看看是否能找到一定规律,
此时我们可以看到,JSON数据的网址和html类型的字符串数据网址是一个请求地址,
只是请求时传递的参数不一样而已,那么说明无论返回的什么类型的数据,都是在一个请求地址处理的,只是根据不同的传参返回不同类型的数据而已
http://news.baidu.com/widget?id=LocalNews&ajax=json&t=1501348444467 JSON数据的网址 http://news.baidu.com/widget?id=civilnews&t=1501348728134 html类型的字符串数据网址 http://news.baidu.com/widget?id=InternationalNews&t=1501348728196 html类型的字符串数据网址
我们可以将html类型的字符串数据网址加上JSON数据的网址参数,那是否会返回JSON数据类型?试一试,果然成功了
http://news.baidu.com/widget?id=civilnews&ajax=json 将html类型的字符串数据网址加上JSON数据的网址参数 http://news.baidu.com/widget?id=InternationalNews&ajax=json 将html类型的字符串数据网址加上JSON数据的网址参数
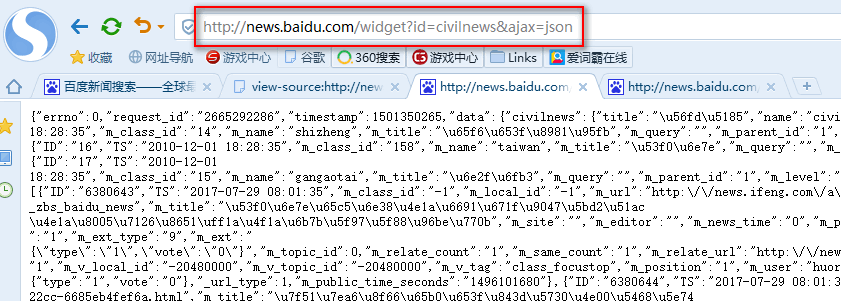
这下就好办了,找到所有的html类型的字符串数据网址,按照上面的方法将其转换成JSON数据的网址,然后循环的去访问转换后的JSON数据的网址,就可以拿到所有新闻的url地址了
crapy实现

# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request,FormRequest
import re
import json
from adc.items import AdcItem
from scrapy.selector import Selector
class PachSpider(scrapy.Spider): #定义爬虫类,必须继承scrapy.Spider
name = 'pach' #设置爬虫名称
allowed_domains = ['news.baidu.com'] #爬取域名
start_urls = ['http://news.baidu.com/widget?id=civilnews&ajax=json']
qishiurl = [ #的到所有页面id
'InternationalNews',
'FinanceNews',
'EnterNews',
'SportNews',
'AutoNews',
'HouseNews',
'InternetNews',
'InternetPlusNews',
'TechNews',
'EduNews',
'GameNews',
'DiscoveryNews',
'HealthNews',
'LadyNews',
'SocialNews',
'MilitaryNews',
'PicWall'
]
urllieb = []
for i in range(0,len(qishiurl)): #构造出所有idURL
kaishi_url = 'http://news.baidu.com/widget?id=' + qishiurl[i] + '&ajax=json'
urllieb.append(kaishi_url)
# print(urllieb)
def parse(self, response): #选项所有连接
for j in range(0, len(self.urllieb)):
a = '正在处理第%s个栏目:url地址是:%s' % (j, self.urllieb[j])
yield scrapy.Request(url=self.urllieb[j], callback=self.enxt) #每次循环到的url 添加爬虫
def enxt(self, response):
neir = response.body.decode("utf-8")
pat2 = '"m_url":"(.*?)"'
url = re.compile(pat2, re.S).findall(neir) #通过正则获取爬取页面 的URL
for k in range(0,len(url)):
zf_url = url[k]
url_zf = re.sub("\/", "/", zf_url)
pduan = url_zf.find('http://')
if pduan == 0:
print(url_zf) #输出获取到的所有url