awk
命令格式:
awk ‘BEGIN{commands} pattern {commands} END{commands}’file
工作方式:
1.执行BEGIN{commands}语句块中语句,可选的语句块
2.从文件或者stdin中读取一行,然后执行{commands},重复这个过程,直到文件全部被读取完
3.当读至输入流末尾是,执行END{commands}语句块
特殊变量:
FILENAME:awk浏览的文件名
NR:记录数量,执行过程中对应于当前行号
NF:字段数量,执行过程中对应于当前行的字段数
FS:设置分隔符,命令行 -F
$0:执行过程中当前行的文本内容
$1:第一个字段的文本内容
$2:第二个字段的文本内容,以此类推
print&printf打印输出的函数
print的参数是以逗号进行分隔时,参数打印时则以空格作为定界符,awk的print语句中,双引号是被当做拼接操作符使用的
printf函数,其用法和c语言中printf基本相似,可以格式化字符串,输出复杂时,printf更加好用,代码更易懂。
流程控制语句
if(condition)else{}
while(){}
do{}while()
for(;;)等
内建字符串控制函数:
1.length(string):返回字符串的长度
2.index(string,search_string):返回search_string在字符串中出现的位置
3.substr(string,start_pos,end-pos):在字符串中从start-pos开始到end-pos位置,生成子串
4.split(string,array,delimiter):用delimiter生成一个字符串列表,并将该列表存入数组,delimiter默认使用当前FS值。
5.sub(regex,replace_str,string):将正则表达式匹配到的第一处内容替换成replace_str
6.gsub(regex,replace_str,string):替换正则表达式匹配到所有的内容
7.match(regex,string):检测正则表达式是否能够匹配字符串
应用:
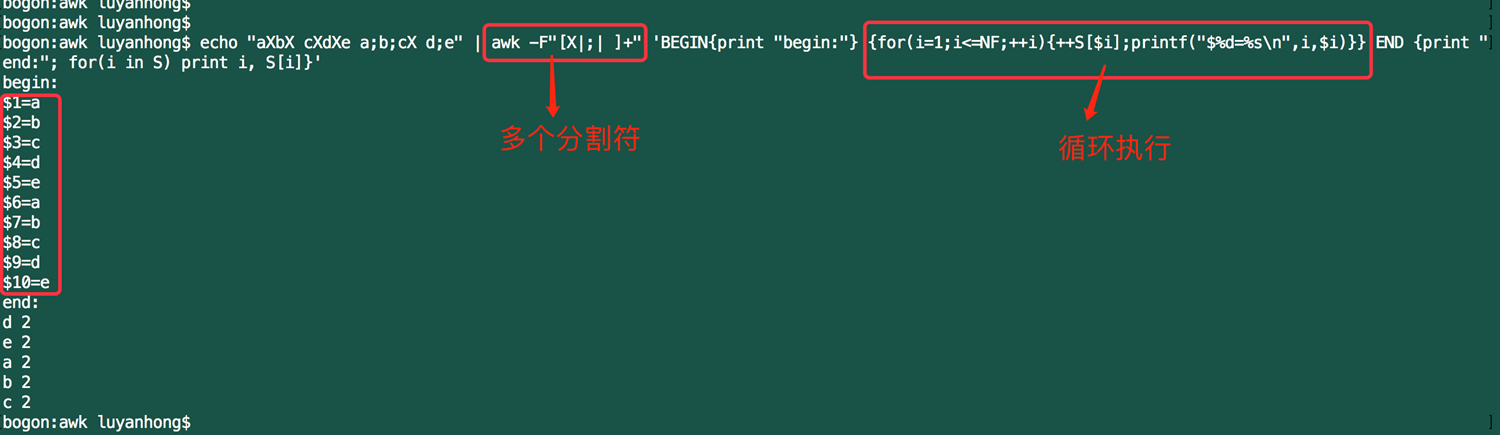
1.从文件或者stdin中读取一行,循环执行{commands},直到读完
echo "aXbX cXdXe a;b;cX d;e" | awk -F"[X|;| ]+" 'BEGIN{print "begin:"} {for(i=1;i<=NF;++i){++S[$i];printf("$%d=%s ",i,$i)}} END {print "end:"; for(i in S) print i, S[i]}'
2.split函数
