郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

ICLR, (2020)
ABSTRACT
在从专家演示中进行模仿学习时,分布匹配是一种流行的方法,其中一个在估计分布比率之间交替,然后在标准强化学习(RL)算法中使用这些比率作为奖励。传统上,分配比率的估计需要同策(on-policy)数据,这导致以前的工作要么数据效率过高,要么以一种可以彻底改变其最佳值的方式改变原始目标。在这项工作中,我们展示了如何以有原则的方式转换原始分配比率估计目标以产生完全异策(off-policy)的目标。除了它提供的数据效率之外,我们还能够证明这个目标也使得使用单独的RL优化变得不必要。相反,可以直接从该目标中学习模仿策略,而无需使用显式奖励。我们将生成的算法称为ValueDICE,并在一套流行的模仿学习基准上对其进行评估,发现它可以实现最先进的样本效率和性能。1
1 可以复现我们结果的代码可以从https://github.com/google-research/google-research/tree/master/value_dice中获得。
1 INTRODUCTION
强化学习(RL)通常被定义为基于来自试错经验的奖励反馈来学习行为策略。因此,许多成功的RL演示通常依赖于精心设计的奖励以及旨在鼓励预期行为的各种奖励和惩罚(Nachum et al., 2019a; Andrychowicz et al., 2018)。相比之下,许多现实世界的行为更容易展示,而不是设计明确的奖励。这种认识是模仿学习的核心(Ho & Ermon, 2016; Ng et al.; Pomerleau, 1989),其中一个目标是从一组专家演示中学习行为策略——记录的接近最优策略与环境相互作用的经验数据——没有明确的奖励知识。
通过对抗性学习或对抗性模仿学习(AIL)进行分布匹配,最近已成为模仿学习的一种流行方法(Ho & Ermon, 2016; Fu et al., 2017; Ke et al., 2019; Kostrikov et al., 2019)。这些方法将专家演示中提供的状态和动作解释为来自目标分布的有限样本。然后,模仿学习可以被定义为学习一种行为策略,该行为策略可以最小化该目标分布与由行为策略与环境交互引起的状态-动作分布之间的差异。正如Ho & Ermon (2016)得出的,这种散度最小化可以通过迭代执行两个交替步骤来实现,这让人想起GAN算法(Goodfellow et al., 2014)。首先,估计目标分布和行为策略之间的状态和动作的密度比。然后,这些密度比率被用作标准RL算法的奖励,并更新行为策略以最大化这些累积奖励(数据分布比率)。
当前分布匹配方法的主要限制是估计分布密度比(每次迭代的第一步)通常需要来自行为策略分布的样本。这意味着每次迭代——行为策略的每次更新——都需要与环境进行新的交互,从而排除了在与环境交互昂贵且有限的环境中使用这些算法。几篇论文试图通过设计异策模仿学习算法来放宽这种同策要求并解决样本效率低下的问题,该算法可以利用过去记录的数据,通常以回放缓存的形式(Kostrikov et al., 2019; Sasaki et al., 2019)。然而,这些方法通过改变原始散度最小化目标来测量目标专家分布和回放缓存分布之间的散度来实现这一点。因此,不能保证学到的策略将恢复所需的目标分布。
在这项工作中,我们介绍了一种模仿学习算法,该算法一方面像原始AIL方法一样执行散度最小化,另一方面完全异策。我们首先提供了最小散度目标的新公式,该公式避免使用任何明确的同策期望。虽然这个目标可以以传统方式用于估计数据分布比率,然后输入到RL算法中,但我们进一步展示了派生目标的特定形式如何使利用单独的RL优化变得不必要。相反,可以直接计算关于行为策略的最小散度目标的梯度。通过这种方式,可以学习模仿行为策略,以在不使用显式奖励的情况下最小化散度。我们将这种流线型模仿学习算法称为ValueDICE。除了比标准模仿学习方法更简单之外,我们还展示了我们提出的算法能够在一套模仿学习基准上实现最先进的性能。
2 BACKGROUND

2.1 BEHAVIORAL CLONING (BC)
监督行为克隆(BC)是一种流行的模仿学习方法。给定一组专家演示,使用回归或密度估计拟合状态观察到动作的映射。在最简单的情况下,只需训练行为策略 π 以最小化观察到的专家行为的负对数似然:
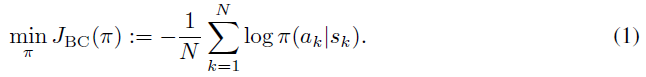
与逆强化学习(IRL)算法(例如GAIL (Ho & Ermon, 2016))不同,BC不会与学习环境执行任何额外的策略交互,因此不会遇到相同的策略样本复杂性问题。然而,行为克隆受到分布漂移的影响(Ross et al., 2011);即,如果它从专家行为偏离到专家演示中没有看到的状态,则无法学习如何恢复。
2.2 DISTRIBUTION MATCHING

这些先验分布匹配方法具有两个限制,我们将通过我们提出的 ValueDICE 算法解决这些限制:
- On-policy. 可以说,这些先前方法的主要限制是它们需要访问来自dπ的同策样本。虽然异策RL可用于学习 π,但优化鉴别器 h 需要有同策样本(公式5中的第二个期望)。因此,在实践中,GAIL需要大量的环境交互,使其无法在许多实际应用中使用。解决此问题的尝试,例如Discriminator Actor-Critic (DAC)(Kostrikov et al., 2019),通常通过临时方法进行;例如,将公式5中的同策期望
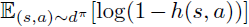 更改为对回放缓存的期望
更改为对回放缓存的期望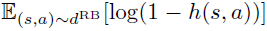 。虽然DAC取得了很好的经验结果,但它并不能保证 π 与πexp的分布匹配,尤其是当dRB远离dπ时。
。虽然DAC取得了很好的经验结果,但它并不能保证 π 与πexp的分布匹配,尤其是当dRB远离dπ时。 - Separate RL optimization. 先前的方法需要迭代地采取交替步骤:首先使用类似GAN的目标估计数据分布比率,然后将这些输入到RL优化中并重复。使用单独的RL算法会给这些方法的任何实现带来复杂性,需要做出许多额外的设计选择,并且需要学习更多的函数逼近器(例如,价值函数)。我们引入的ValueDICE将被证明不需要单独的RL优化。
3 OFF-POLICY FORMULATION OF THE KL-DIVERGENCE



4 VALUEDICE: IMITATION LEARNING WITH IMPLICIT REWARDS
虽然分布匹配的标准是对估计分布比率和学习策略进行单独的优化,但在我们的例子中,这可以得到缓解。事实上,看看我们在公式12中的KL公式,我们看到这个目标相对于 π 的梯度可以很容易地计算出来。具体来说,我们可以将对于 π 的分布匹配目标表示为最大最小优化:

5 SOME PRACTICAL CONSIDERATIONS
为了在实际场景中使用ValueDICE目标(公式13),其中一个无法访问dexp或p0(·),而只能访问有限的有限样本,我们进行了一些修改。
5.1 EMPIRICAL EXPECTATIONS
公式13中的目标包含三个期望:
- 对dexp(目标的第一项)的期望。请注意,这个期望在它之外有一个对数,这会使这个期望的梯度的任何小批量近似都有偏差。
- 对p0(·)的期望(目标的第二项)。该项是线性的,因此非常适合小批量优化。
- 对用于计算Bπv(s,a)的环境转换p(·|s,a)的期望。这个期望应用了一个对数期望指数,所以它的小批量近似梯度通常会有偏差。
对于第一个期望,以前的工作已经提出了一些补救措施来减少小批量梯度的偏差,例如保持各种数量的移动平均值(Belghazi et al., 2018)。在我们考虑的设置中,我们发现这对性能的影响可以忽略不计。事实上,简单地使用有偏差的小批量梯度就足以获得良好的性能,因此我们将其用于我们的实验。
对于第二个期望,我们使用无偏的标准小批量梯度。虽然初始状态分布通常不用于模仿学习,但很容易记录观察到的初始状态,因此可以从p0获得经验样本。此外,如第5.3节所述,可以修改目标中使用的初始状态分布而不会产生不利影响。
最后,对于第三个期望,以前的工作建议使用Fenchel共轭来消除偏差(Nachum et al., 2019b)。在我们的案例中,我们发现这是不必要的,而是使用基于单个样本s' ~ p(·|s,a)的有偏估计。这种幼稚的方法足以在我们考虑的基准域上实现良好的性能。
总之,目标的经验形式由下式给出,
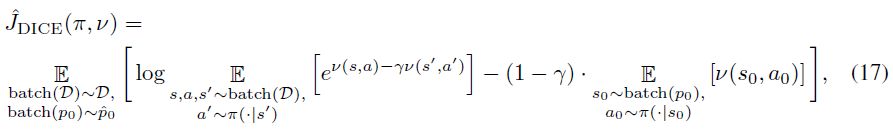
其中batch(D)是来自 D 的mini-batch,而batch(p0)是来自记录的初始状态![]() 的mini-batch。
的mini-batch。
5.2 REPLAY BUFFER REGULARIZATION
最初的ValueDICE目标仅使用专家样本和初始状态分布。在实践中,专家样本的数量可能很少并且缺乏多样性,从而阻碍了学习。为了增加用于训练的样本的多样性,我们考虑了一个替代目标,该目标具有基于回放缓存中经验的可控正则化:

5.3 INITIAL STATE SAMPLING
回想一下那个dexp, dπ传统上指的是折扣状态-动作分布。也就是说,从它们中采样等价于首先采样轨迹(s0, a0, s1, a1, ... , sT),然后从几何分布Geom(1 - γ)中采样时间索引 t (适当处理超过 T 的样本)。这意味着远离轨迹的样本对目标的贡献不大。为了解决这个问题,我们建议将轨迹中的每个状态视为"初始状态"。也就是说,我们将单个环境轨迹(s0, a0, s1, a1, ... , sT)视为 T 个不同的虚拟轨迹![]() 。我们将它应用于dexp和dπ,因此它不仅增加了来自dexp的样本的多样性,而且还扩展了初始状态分布p0(·)以包含轨迹中的每个状态。我们注意到,这不会影响目标相对于 π 的最优性,因为在马尔可夫环境中,专家策略应该专业,无论其开始的状态如何(Puterman, 2014)。
。我们将它应用于dexp和dπ,因此它不仅增加了来自dexp的样本的多样性,而且还扩展了初始状态分布p0(·)以包含轨迹中的每个状态。我们注意到,这不会影响目标相对于 π 的最优性,因为在马尔可夫环境中,专家策略应该专业,无论其开始的状态如何(Puterman, 2014)。
6 RELATED WORK
近年来,对抗性模仿学习的发展主要集中在同策算法上。在Ho & Ermon (2016)提出GAIL通过对抗训练进行模仿学习之后,引入了许多扩展。AIL框架的许多应用(Li et al., 2017; Hausman et al., 2017; Fu et al., 2017)保持与GAIL相同的分配比率估计形式,这需要策略样本。相比之下,我们的工作提出了相同目标的异策表述。
尽管有几项工作试图将AIL框架应用于异策设置,但这些以前的方法与我们自己的方法明显不同。例如,Kostrikov et al. (2019)提出使用来自回放缓存的样本而不是来自策略的样本来训练类似GAN的AIL目标中的鉴别器。这改变了分配比率估计以衡量专家和回放之间的差异。尽管我们引入了一个可控参数,用于将回放缓存中的样本合并到数据分布目标中,但我们注意到在实践中我们使用了非常小的α = 0.1。此外,通过在目标的两个方面而不是仅一个方面使用回放缓存中的样本,专家策略的全局最优性不会受到影响。
我们推导出的KL散度的异策公式是由DualDICE中的类似技术推动的(Nachum et al., 2019b)。尽管如此,我们对这些技术的使用提供了一些新颖性。首先,Nachum et al. (2019b)假设一个固定的策略,仅使用散度公式进行数据分布估计(用于异策评估)。我们使用公式来学习策略以直接最小化散度。此外,以前的工作仅将这些推导应用于KL散度的 f 散度形式,而我们是第一个使用Donsker-Varadhan形式的。有趣的是,在我们最初的实验中,我们发现使用 f 散度形式会导致性能不佳。我们注意到我们提出的目标遵循类似于REPS (Peters et al., 2010)的形式,它也使用log-average-exp项。然而,REPS中的策略和价值学习是通过双层优化执行的(即,策略是针对不同的目标学习的),这与我们的算法不同,后者针对相同的目标训练价值和策略。我们提出的ValueDICE对于能够将任意(非专家)数据合并到其学习中也很重要。
7 EXPERIMENTS
我们在各种环境中评估ValueDICE,从一个简单的合成任务开始,然后继续对一组MuJoCo基准进行评估。
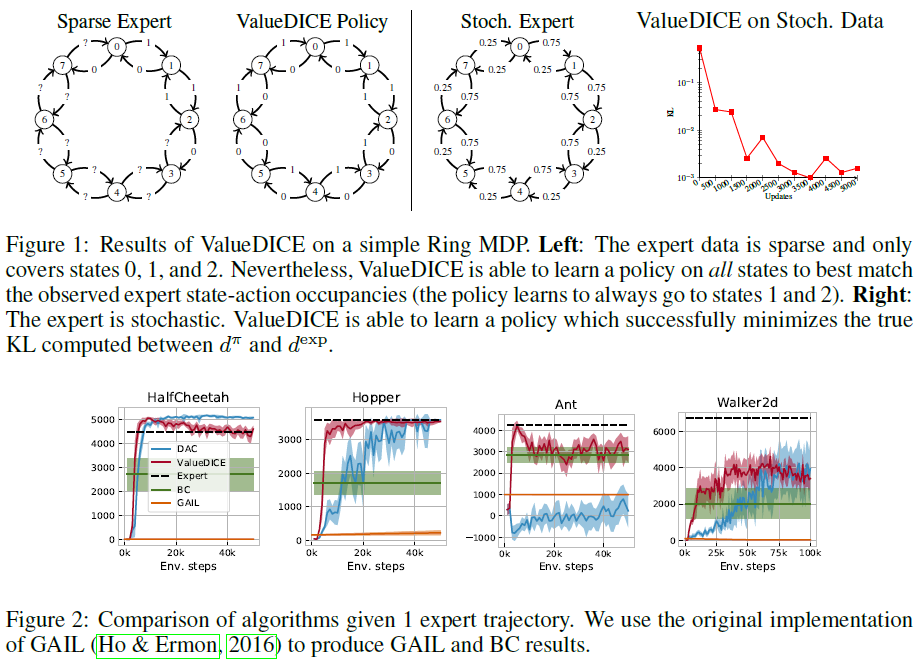
7.1 RING MDP
我们首先分析ValueDICE在简单合成MDP上的行为(图1)。MDP的状态被组织成一个环。在每个状态下,可能有两种动作:顺时针或逆时针移动。我们首先看一下ValueDICE在专家数据稀疏且不涵盖所有状态和动作的情况下的性能。具体来说,我们提供仅涵盖状态0、1和2的专家演示(参见左图1)。虽然恢复真实(未知)专家的问题定义不明确,但仍有可能找到恢复接近相同占用率的策略。实际上,这就是ValueDICE发现的策略,它在每个状态选择适当的动作以最佳地达到状态1和2(并且在这些状态下在状态1和2之间交替)。在许多实际场景中,这是期望的结果——如果模仿策略以某种方式遇到偏离专家演示的情况,我们希望它尽快返回专家行为。值得注意的是,像行为克隆这样的技术将无法学习这种最佳策略,因为它的学习仅基于观察到的专家数据。
我们还与随机专家一起分析了ValueDICE的行为(图1右)。通过使用合成MDP,我们能够在训练期间测量散度DKL(dπ||dexp)。正如预期的那样,我们发现这种差异在ValueDICE训练期间减少了。
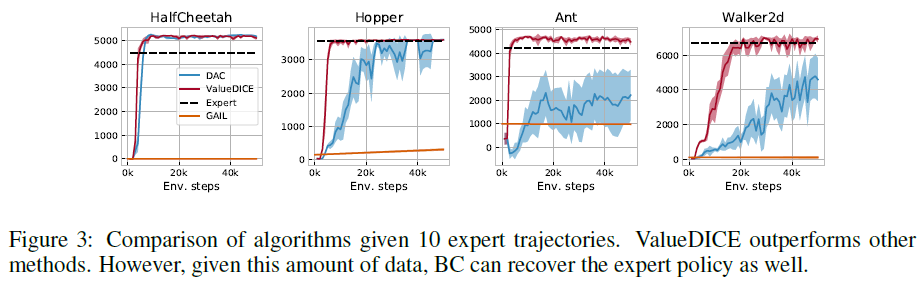
7.2 MUJOCO BENCHMARKS
我们将ValueDICE与Discriminator-Actor-Critic (DAC)(Kostrikov et al., 2019)以及 GAIL (Ho & Ermon, 2016)进行比较,其中DAC是样本高效的对抗性模仿学习的最新技术。我们使用Ho & Ermon (2016)的专家演示评估标准MuJoCo环境中的算法。我们使用10个回合绘制每1000个环境步骤的学习策略的平均回报(使用平均采样动作)。我们对10个不同的种子执行此过程并计算均值和标准差(参见图2和图3,我们在这些图上可视化了标准差的一半)。
我们首先介绍极低数据机制。在图2中,我们展示了仅给定单个专家轨迹的模仿学习算法的结果。我们发现ValueDICE在所有任务上的表现都与DAC相似或更好,但Walker2d除外,它收敛到稍差的策略。值得注意的是,在这种低数据状态下,行为克隆(BC)通常无法恢复专家策略。我们还在大量专家演示中展示了这些算法的结果(图3)。我们继续观察到ValueDICE的强劲表现以及所有任务的更快收敛。值得一提的是,在这种大数据的情况下,行为克隆同样可以恢复专家的表现。在所有这些场景中,GAIL的样本效率太低,无法取得任何进展。
8 CONCLUSION
我们介绍了ValueDICE,这是一种模仿学习算法,在标准MuJoCo任务上的表现优于最先进的算法。与其他异策模仿学习算法相比,本文介绍的算法以有原则的异策方式和强大的理论框架进行鲁棒散度最小化。据我们所知,这也是第一个省略了学习或明确定义奖励并直接在分配比率目标中学习Q函数的对抗性模仿学习算法。我们展示了ValueDICE在具有挑战性的合成表格MDP环境以及标准MuJoCo连续控制基准环境中的稳健性,并且我们展示了在低数据和高数据状态下的基线性能都有所提高。
A IMPLEMENTATION DETAILS
所有算法都使用具有2个隐藏层和256个隐藏单元的MLP架构的网络。对于判别器,critic以及v,我们使用Adam优化器,学习率为10-3,而对于actors,我们使用10-5的学习率。 对于鉴别器和 v 网络,我们使用Gulrajani et al. (2017)的梯度惩罚。我们还使用系数为10-4的正交正则化(Brock et al., 2018)对参与者网络进行正则化。此外,我们每1个环境步骤执行4次更新。我们处理环境的吸收状态类似于Kostrikov et al. (2019)。
B ALGORITHMS
在本节中,我们将介绍基于 DualDICE 的模仿学习算法的伪代码。

C ADDITIONAL EXPERIMENTS
我们还将ValueDICE与离线状态下的行为克隆进行了比较,当我们没有从学习环境中采样额外的转换时(参见图4)。即使只给出离线数据,ValueDICE也优于行为克隆。对于行为克隆,我们使用了与ValueDICE中的actor训练相同的正则化。