郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

AAAI, pp.11270-11277, (2020)
Abstract
在过去的十年中,深度神经网络(DNN)在各种应用中都表现出了卓越的性能。随着我们试图解决更高级的问题,对计算和电力资源的需求不断增加已成为必然。 脉冲神经网络(SNN)作为第三代神经网络,由于其事件驱动和低功耗的特性而引起了广泛的兴趣。然而,SNN难以训练,主要是由于它们复杂的神经元动力学和不可微分的脉冲操作。此外,它们的应用仅限于相对简单的任务,例如图像分类。在这项研究中,我们研究了SNN在更具挑战性的回归问题(即目标检测)中的性能下降。通过我们的深入分析,我们介绍了两种新颖的方法:通道归一化和具有不平衡阈值的符号神经元,这两种方法都为深度SNN提供了快速准确的信息传输。因此,我们提出了第一个基于脉冲的目标检测模型,称为Spiking-YOLO。我们的实验表明,Spiking-YOLO在非平凡数据集、PASCAL VOC和MS COCO上取得了与Tiny YOLO相当(高达98%)的显著结果。此外,神经形态芯片上的Spiking-YOLO消耗的能量大约比Tiny YOLO少280倍,收敛速度比以前的SNN转换方法快2.3到4倍。
Introduction
最近深度神经网络(DNN)成功背后的主要原因之一可归因于高性能计算系统的发展和用于模型训练的大量数据的可用性。然而,解决实际应用中更有趣和更高级的问题需要更复杂的模型和训练数据,这会导致计算开销和功耗显著增加。为了克服这些挑战,许多研究人员尝试使用剪枝(Guo, Yao, and Chen 2016; He, Zhang and Sun 2017)、压缩(Han, Mao, and Dally 2016; Kim et al. 2015)和量化(Gong et al. 2014; Park et al. 2018)来设计计算和节能的DNN,其中一些已经显示出有希望的结果。尽管做出了这些努力,但随着更深且更复杂的神经网络实现更高的准确性,对计算和电力资源的需求将会增加(Tan and Le 2019)。
脉冲神经网络(SNN)是第三代神经网络,通过使用脉冲神经元作为计算单元来模拟信息在人脑中的编码和处理方式(Maass 1997)。与传统的神经网络不同,SNN通过由一系列脉冲(离散)组成的脉冲序列的精确计时(时间)而不是实际值(连续)来传输信息。也就是说,SNN在信息传输中像在生物神经系统中一样利用时间方面(Mainen and Sejnowski 1995),从而提供了稀疏但强大的计算能力(Mostafa et al. 2017; Bellec et al. 2018)。此外,脉冲神经元在接收到脉冲时将输入整合到膜电位中,并在膜电位达到某个阈值时产生(发放)脉冲,这使得事件驱动计算成为可能。由于脉冲事件和事件驱动计算的稀疏特性,SNN提供了卓越的功率效率,并且是神经形态架构中的首选神经网络(Merolla et al., 2014; Poon and Zhou 2011)。
尽管SNN具有出色的潜力,但它们仅限于相对简单的任务(例如,图像分类)和小型数据集(例如,MNIST和CIFAR),而且结构相当浅(Lee, Delbruck, and Pfeiffer 2016; Wu et al. 2019)。应用范围有限的主要原因之一是由于脉冲神经元的复杂动力学和不可微操作而缺乏可扩展的训练算法。DNN到SNN的转换方法作为一种替代方法,近年来得到了广泛的研究(Cao, Chen, and Khosla 2015; Diehl et al. 2015; Sengupta et al. 2019)。这些方法基于将预先训练的参数(例如,权重和偏差)从DNN导入到SNN的想法。DNN到SNN的转换方法在深度SNN中取得了与原始DNN(例如VGG和ResNet)相当的结果;然而,MNIST和CIFAR数据集的结果具有竞争力,而ImageNet数据集的结果与DNN的准确性相比并不令人满意。
在这项研究中,我们使用DNN到SNN的转换方法研究了深度SNN中更高级的机器学习问题,即目标检测。目标检测被认为更具挑战性,因为它涉及识别多个重叠目标和计算边界框的精确坐标。因此,它需要较高的数值精度来预测神经网络的输出值(即回归问题),而不是像在图像分类中那样选择概率最高的一类(即argmax函数)。根据我们的深入分析,在深度SNN中应用目标检测时会出现几个问题:a)传统归一化方法的效率低下,b)在SNN域中缺乏有效的leaky-ReLU实现方法。
为了克服这些问题,我们引入了两种新方法; 通道归一化和阈值不平衡的有符号神经元。因此,我们提出了一种基于脉冲的目标检测模型,称为Spiking-YOLO。作为SNN中目标检测的第一步,我们实现了基于Tiny YOLO的Spiking-YOLO (Redmon et al. 2016)。据我们所知,这是第一个用于目标检测的深度SNN,它在非平凡数据集、PASCAL VOC和MS COCO上取得了与DNN相当的结果。我们的贡献可以总结如下:
- 深度SNN中的第一个目标检测模型 我们首次展示了Spiking-YOLO,这是一种能够在深度SNN中实现节能目标检测的模型。Spiking-YOLO在非平凡数据集上取得了与原始DNN相当的结果,即98%。
- 通道归一化 我们为深度SNN开发了一种细粒度的归一化方法。所提出的方法能够在多个神经元中实现更高但适当的发放率,从而在深度SNN中实现快速准确的信息传输。
- 具有不平衡阈值的有符号神经元 我们提出了一种在SNN域中准确高效的leaky-ReLU实现方法。所提出的方法可以很容易地在具有最小开销的神经形态芯片中实现。
Related work
DNN-to-SNN conversion
与DNN不同,SNN使用由一系列脉冲组成的脉冲序列在神经元之间传递信息。LIF神经元将输入 z 累积到膜电位Vmem中:
![]()
其中![]() 是一个脉冲,并且
是一个脉冲,并且![]() 是第 l 层的第 j 个神经元的输入,其膜电压为Vth。
是第 l 层的第 j 个神经元的输入,其膜电压为Vth。![]() 能够被描述为:
能够被描述为:
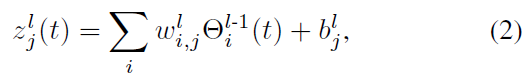
其中 w 和 b 分别是权重和偏差。 当积分值Vmem超过阈值电压Vth时产生脉冲Θ,如:
![]()
其中U(x)是单位阶跃函数。由于事件驱动的性质,SNN提供了节能操作(Pfeiffer and Pfeil 2018)。然而,它们很难训练,这是在各种应用中部署SNN时的主要障碍之一(Wu et al. 2019)。
SNN的训练方法包括具有脉冲时序依赖可塑性(STDP)的无监督学习(Diehl 和 Cook 2015) 以及具有梯度下降和误差反向传播的监督学习 (Lee, Delbruck, and Pfeiffer 2016)。 尽管 STDP 在生物学上更合理,但学习性能明显低于监督学习。 最近的工作提出了一种监督学习算法,其函数近似于 SNN 的不可微分部分(IF)(Jin, Zhang, and Li 2018; Lee, Delbruck, and Pfeiffer 2016),以提高学习性能。尽管做出了这些努力,但之前的大多数工作都仅限于浅层SNN上的图像分类任务和MNIST数据集。
作为一种替代方法,最近提出了将DNN转换为SNN。(Cao, Chen, and Khosla 2015)提出了一种忽略偏差和最大池化的DNN到SNN的转换方法。在随后的工作中,(Diehl et al. 2015)提出了基于数据的归一化来提高深度SNN的性能。(Rueckauer et al. 2017)提出了一种批归一化和脉冲最大池化的实现方法。(Sengupta et al. 2019)将转换方法扩展到VGG和残差架构。尽管如此,以前的大多数工作都仅限于图像分类任务(Park et al. 2019)。
Object detection
目标检测通过绘制边界框来定位图像或视频中的单个或多个目标,然后识别它们的类别。因此,目标检测模型不仅包括对目标进行分类的分类器,还包括预测边界框的精确坐标(x 轴和 y 轴)和大小(宽度和高度)的回归器。因为预测边界框的精确坐标至关重要,所以目标检测被认为是比图像分类更具挑战性的任务,其中使用argmax函数简单地选择具有最高概率的一类。
基于区域的CNN (R-CNN) (Girshick et al. 2014)被认为是目标检测领域最重要的进步之一。为了提高检测性能和速度,已经提出了R-CNN的各种扩展版本,即fast R-CNN (Girshick 2015)、faster R-CNN (Ren et al. 2015)和Mask R-CNN (He et al. 2017)。然而,由于多阶段检测方案,基于R-CNN的网络推理速度较慢,因此不适合实时目标检测。
作为一种替代方法,已经提出了单阶段检测方法,其中提取边界框信息,并将目标分类在一个统一的网络中。在单阶段检测模型中,"Single-shot multi-box detection" (SSD) (Liu et al. 2016)和"You only look once" (YOLO) (Redmon and Farhadi 2018)实现了最先进的性能。特别是,YOLO具有出色的推理速度(FPS),而不会显著损失准确度,这是实时目标检测的关键因素。因此我们选择Tiny YOLO作为我们的目标检测模型。
Methods
在目标检测中,识别多个目标并在它们周围绘制边界框(即回归问题)提出了很大的挑战:预测网络的输出值需要很高的数值精度。当使用传统的DNN-to-SNN转换方法将目标检测应用于深度SNN时,它会遭受严重的性能下降并且无法检测到任何目标。我们的深入分析强调了这种性能下降的可能解释:a)在许多神经元中极低的发放率和 b)在SNN中缺乏一种有效的leaky-ReLU实现方法。为了克服这些并发症,我们提出了两种新方法:通道归一化和阈值不平衡的有符号神经元。
Channel-wise data-based normalization
Conventional normalization methods 在典型的SNN中,确保神经元根据输入的大小生成脉冲序列并在不丢失任何信息的情况下传输这些脉冲序列是至关重要的。然而,在给定固定数量的时间步骤的情况下,神经元中的激活不足或过度激活可能会导致信息丢失。例如,如果阈值电压Vth非常大或输入很小,则膜电位Vmem将需要很长时间才能达到Vth,从而导致低发放率(即激活不足)。相反,如果Vth极小或输入很大,则Vmem很可能会超过Vth,并且无论输入值如何,神经元都会产生脉冲(即过度激活)。值得注意的是,发放率可以定义为N/T ,其中 N 是给定时间步骤 T 中的脉冲总数。最大发放率将是100%,因为每个时间步骤都可以生成一个脉冲。
为了防止神经元激活不足或过度激活,需要仔细选择权重和阈值电压,以实现神经元的充分和平衡激活(Diehl et al. 2015)。已经提出了各种基于数据的归一化方法(Diehl et al. 2015)。逐层归一化(Diehl et al. 2015)(缩写为layer-norm)是最著名的归一化方法之一;layer-norm使用相应层的最大激活对特定层中的权重进行归一化,该激活是通过在DNN中运行训练数据集计算得出的。这是基于训练和测试数据集的分布相似的假设。此外,请注意,使用最大激活对权重进行归一化与对输出激活进行归一化具有相同的效果。layer-norm可以计算为:
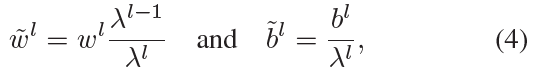
其中 w, λ 和 b 分别是权重、从训练数据集计算的最大激活值和第 l 层中的偏差。作为layer-norm的扩展版本,(Rueckauer et al. 2017)引入了一种使用最大激活的99.9%对激活进行归一化的方法;这增加了对异常值的鲁棒性并确保神经元有足够的发放。然而,我们的实验表明,当使用传统的归一化方法在深度SNN中应用目标检测时,模型的性能会显著下降。
Analysis of layer-norm limitation 图1表示从layer-norm获得的每个通道中的归一化最大激活值。Tiny YOLO由八个卷积层组成;x轴表示通道索引,y轴表示归一化的最大激活值。蓝线和红线分别表示每层中归一化激活的平均值和最小值。如图1所示,对于特定的卷积层,每个通道上的归一化激活的偏差相对较大。例如,在Conv1层中,某些通道(例如,通道6、7和14)的归一化最大激活值接近1,而对于其他通道(例如,通道1、2、3、13和16)则接近0。其他卷积层也是如此。显然,layer-norm在归一化之前具有相对较小激活值的众多通道中产生异常小的归一化激活(即激活不足)。
这些极小的归一化激活在图像分类中未被检测到,但在解决深度SNN中的回归问题时可能会出现极大的问题。例如,要传输0.7,需要7个脉冲和10个时间步骤。应用相同的逻辑,传输0.007将需要7个脉冲和1000个时间步骤,而不会丢失任何信息。因此,要发送极小(例如,0.007)或精确(例如,0.9007 对 0.9000)的值而不会造成任何损失,需要大量的时间步骤。时间步骤的数量被认为是正在传输的信息的分辨率。因此,极小的归一化激活会产生低发放率,当时间步骤数少于所需数量时,这会导致信息丢失。
Proposed normalization method 我们提出了一种更细粒度的归一化方法,被称为通道归一化(缩写为channel-norm),以实现在深度SNN中快速高效的信息传输。我们的方法以通道方式而不是传统的分层方式通过最大可能激活(第99.9个百分位数)对权重进行归一化。所提出的channel-norm可以被表示为:
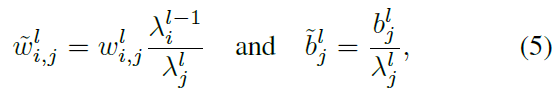
其中 i 和 j 是通道的索引。层 l 中的权重 w 通过每个通道中的最大激活![]() 进行归一化(与归一化输出激活相同的效果)。如前所述,最大激活是根据训练数据集计算的。在接下来的层中,归一化的激活必须乘以
进行归一化(与归一化输出激活相同的效果)。如前所述,最大激活是根据训练数据集计算的。在接下来的层中,归一化的激活必须乘以![]() 以获得归一化之前的原始激活。详细方法在算法1和图2中描述。
以获得归一化之前的原始激活。详细方法在算法1和图2中描述。
以通道方式对激活进行归一化消除了极小的激活(即激活不足),这些激活在归一化之前具有较小的激活值。换句话说,神经元被归一化以获得更高但适当的发放率,从而在短时间内实现准确的信息传输。

Analysis of the improved firing rate 在图3中,x 轴和 y 轴分别表示发放率和在对数尺度上产生特定发放率的神经元数量。对于channel-norm,许多神经元产生高达80%的发放率。然而,在layer-norm中,大多数神经元产生的发放率在0%到3.5%之间。这清楚地表明,channel-norm消除了极小的激活,并且更多的神经元正在产生更高但适当的发放率。此外,图4显示了卷积层1中每个通道的发放率。显然,channel-norm在大多数通道中产生了更高的发放率。特别是在通道2中,channel-norm产生的发放率是layer-norm的20倍。此外,图5显示了来自20个采样神经元的脉冲活动的光栅图。可以看出,当应用channel-norm时,许多神经元的发放更加规律。
我们的详细分析验证了细粒度channel-norm可以更好地使激活正常化,防止激活不足导致低发放率。换句话说,极小的激活被适当地归一化,使得神经元可以在短时间内准确地传递信息。在图像分类等简单应用中,这些小的激活可能并不重要,对网络的最终输出影响不大;但是,它们在回归问题中至关重要,并且会显著影响模型的准确性。因此,channel-norm是解决深度SNN中更高级机器学习问题的可行解决方案。
Signed neuron featuring imbalanced threshold
Limitation of leaky-ReLU implementation in SNNs ReLU,最常用的激活函数之一,只保留正输入值,丢弃所有负值;当x ≥ 0时,f(x) = x,否则f(x) = 0。与ReLU不同,leaky-ReLU包含带有泄漏项的负值,斜率为α,通常设置为0.01;当x ≥ 0时,f(x) = x,否则f(x) = αx (Xu et al. 2015)。
之前的大多数DNN到SNN的转换方法都集中在将IF神经元转换为ReLU,而完全忽略了激活函数负区域的泄漏项。请注意,在Tiny YOLO 中,负激活占51%以上。为了扩展绑定到SNN中负区域的激活函数,(Rueckauer et al. 2017)添加了第二个Vth项(-1)。他们的方法成功地将BinaryNet (Hubara et al. 2016)转换为SNN,其中BinaryNet激活在CIFAR-10上被限制为+1或-1。
目前,各种DNN都使用leaky-ReLU作为激活函数,但尚未提出在SNN域中实现leaky-ReLU 的准确有效的方法。Leaky-ReLU可以通过简单地将负激活乘以斜率α以及第二个Vth项(-1)在SNN中实现。然而,这在生物学上是不合理的(脉冲是一个离散信号),并且在用于神经形态芯片时可能是一个巨大的挑战。例如,斜率α的浮点乘法需要额外的硬件。
The notion of imbalanced threshold 我们在此介绍了一个具有不平衡阈值的有符号神经元(以下简称IBT),它不仅可以解释正激活和负激活,还可以准确有效地补偿leaky-ReLU负区域中的泄漏项。所提出的方法还通过为负区域引入不同的阈值电压Vth,neg来保留脉冲的离散特性。第二阈值电压Vth,neg等于Vth除以斜率的负数-α,并且Vth,pos与之前一样等于Vth。这将在leaky-ReLU的负区域复制泄漏项(斜率α)。具有IBT的有符号神经元的潜在动力学由下式表示:
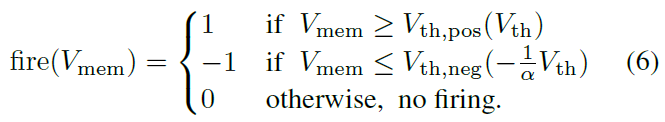
如图6所示,如果斜率α = 0.1,则负责正激活的阈值电压Vth,pos为1V,负激活的阈值电压Vth,neg为-10V;因此,Vmem必须集成十次以上才能为leaky-ReLU中的负激活产生一个脉冲。
值得注意的是,带符号的神经元还可以实现兴奋性和抑制性神经元,这在生物学上更合理(Dehghani et al. 2016; Wilson and Cowan 1972)。使用带IBT的有符号神经元,leaky-ReLU可以在SNN中准确实现,并且可以以最小的开销直接映射到当前的神经形态架构。此外,所提出的方法将为在广泛的应用中将各种DNN模型转换为SNN创造更多机会。
Evaluation
Experimental setup
作为深度SNN中目标检测的第一步,我们使用了实时目标检测模型Tiny YOLO,它是YOLO的一个更简单但高效的版本。我们根据(Rueckauer et al. 2017)在SNN中实现了最大池化和批归一化。Tiny YOLO在非平凡数据集PASCAL VOC和MS COCO上进行了测试。我们的模拟基于TensorFlow Eager,我们在NVIDIA Tesla V100 GPU上进行了所有实验。
Experimental results
Conclusion