Github:https://github.com/openai/multiagent-particle-envs
创造新环境
您可以通过实现上面的前4个函数来创建新的场景 (`make_world()`, `reset_world()`, `reward()`, and `observation()`).
环境列表
| 代码中的环境名称 (文中的名称) | 是否沟通? | 是否竞争? | 笔记 |
| simple.py | N | N | 单个智能体看到地标位置,根据它离地标的距离给予奖励。不是用于调试策略的多智能体环境。|
- 奖励:智能体与目标地标的距离的平方和的相反数。
| simple_adversary.py (物理欺骗) | N | Y | 一个对手 (红色),N个协作智能体 (绿色),N个地标 (通常N=2)。所有智能体观察地标和其他智能体的位置。一个地标是"目标地标" (绿色)。协作智能体会根据它们中的一个离目标地标有多近而得到奖励,但如果对手离目标地标很近,则会得到负奖励。敌方会根据离目标有多近而得到奖励,但它不知道哪个地标是目标地标。因此,协作智能体必须学会"分头行动",覆盖所有的地标来欺骗对手。|
- 协作智能体的奖励:对手与目标地标的距离的L2范式减去协作智能体与目标地标的距离的L2范式。
- 对手的奖励:对手与目标地标的距离的L2范式的相反数。
- 在基于距离的奖励之外,还有基于邻近的奖励,会根据阈值函数调整(增/减)原本的奖励。

| simple_crypto.py (隐蔽通信) | Y | Y | 两个协作智能体(Alice和Bob),一个对手(Eve)。Allien必须通过公共渠道给Bob发私人信息。Alice和Bob会根据Bob重建信息的程度得到奖励,但是如果Eve能重建信息,则会得到负奖励。Alice和Bob有一个私钥(在每个回合开始时随机生成),他们必须学会用它来加密消息。|
| simple_push.py (远离) | N |Y | 一个智能体,一个对手,一个地标。智能体根据到地标的距离获得奖励。如果对手离地标很近,如果智能体离地标很远,它就会得到奖励。所以对手学会了把智能体推离地标。|
- 智能体的奖励:智能体与目标地标的距离的L2范式的相反数。
- 对手的奖励:智能体与目标地标的距离的L2范式减去对手与目标地标的距离的L2范式。

| simple_reference.py | Y | N | 两个智能体,三个不同颜色的地标。每个智能体都希望到达它们的目标地标,而这个地标只有其他智能体知道。奖励是集体的。因此,智能体必须学会传达另一个智能体的目标,并导航到它们的地标。这与简单的说话者-聆听者场景相同,其中两个智能体同时是说话者和聆听者。|
- 奖励:智能体与目标地标的距离的平方和的相反数。
| simple_speaker_listener.py (协作沟通) | Y | N | 与simple_reference相同,只是一个智能体是不移动的"说话者" (灰色)(观察另一个智能体的目标),另一个智能体是聆听者(不能说话,但必须导航到正确的地标)。|
- 奖励:智能体与目标地标的距离的平方和的相反数。

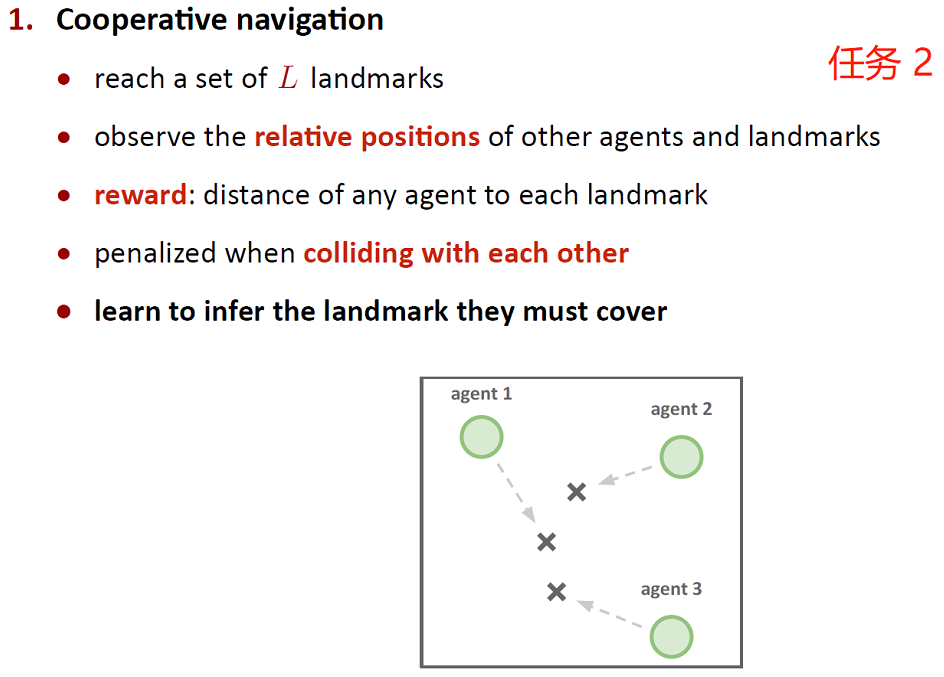
| simple_spread.py (协作导航) | N | N | N个智能体,N个地标。根据每个智能体距每个地标的距离来奖励智能体。如果智能体与其他智能体发生碰撞,它们将受到惩罚。所以,智能体们必须学会在避免碰撞的同时覆盖所有的地标。|
- 奖励:智能体与目标地标的距离的L2范式的相反数。
| simple_tag.py (捕食者-被捕食者) | N | Y | 捕食环境。协作智能体(绿色)速度更快,希望避免被对手(红色)击中。对手速度较慢,想要击中协作智能体。障碍物(大黑圈)挡住了路。|
- 协作智能体的奖励:协作智能体与任一对手的距离小于一定阈值,则减去相应正值;同时,应当减去边界惩罚。
-
对手的奖励:对手与协作智能体的距离小于一定阈值,则加上相应正值。

PS:代码实现与论文以及图中描述的不一致,其中协作智能体与对手描述相反。
import numpy as np
from multiagent.core import World, Agent, Landmark
from multiagent.scenario import BaseScenario
class Scenario(BaseScenario):
def make_world(self):
world = World()
# set any world properties first
world.dim_c = 2 # 沟通通道维度
num_good_agents = 1 # 协作智能体数目
num_adversaries = 3 # 对手数目
num_agents = num_adversaries + num_good_agents # 智能体数目
num_landmarks = 2 # 地标数目
# add agents
world.agents = [Agent() for i in range(num_agents)]
for i, agent in enumerate(world.agents):
agent.name = 'agent %d' % i
agent.collide = True # 实体与其他实体碰撞
agent.silent = True # 无法发送通信信号
agent.adversary = True if i < num_adversaries else False # 对手/协作智能体
agent.size = 0.075 if agent.adversary else 0.05 # 大小
agent.accel = 3.0 if agent.adversary else 4.0 # 加速度
agent.max_speed = 1.0 if agent.adversary else 1.3 # 最大速度
# add landmarks
world.landmarks = [Landmark() for i in range(num_landmarks)]
for i, landmark in enumerate(world.landmarks):
landmark.name = 'landmark %d' % i
landmark.collide = True # 实体与其他实体碰撞
landmark.movable = False # 实体不可以移动/被推
landmark.size = 0.2 # 大小
landmark.boundary = False
# make initial conditions
self.reset_world(world)
return world
def reset_world(self, world):
# random properties for agents
for i, agent in enumerate(world.agents):
agent.color = np.array([0.35, 0.85, 0.35]) if not agent.adversary else np.array([0.85, 0.35, 0.35])
# random properties for landmarks
for i, landmark in enumerate(world.landmarks):
landmark.color = np.array([0.25, 0.25, 0.25])
# set random initial states
for agent in world.agents:
agent.state.p_pos = np.random.uniform(-1, +1, world.dim_p) # 位置初始化
agent.state.p_vel = np.zeros(world.dim_p) # 速度初始化
agent.state.c = np.zeros(world.dim_c) # 通信信号初始化
for i, landmark in enumerate(world.landmarks):
if not landmark.boundary:
landmark.state.p_pos = np.random.uniform(-0.9, +0.9, world.dim_p) # 位置初始化
landmark.state.p_vel = np.zeros(world.dim_p) # 速度初始化
def benchmark_data(self, agent, world):
# returns data for benchmarking purposes
if agent.adversary:
collisions = 0
for a in self.good_agents(world):
if self.is_collision(a, agent):
collisions += 1
return collisions
else:
return 0
# 判断是否发生碰撞
def is_collision(self, agent1, agent2):
delta_pos = agent1.state.p_pos - agent2.state.p_pos
dist = np.sqrt(np.sum(np.square(delta_pos)))
dist_min = agent1.size + agent2.size
return True if dist < dist_min else False
# return all agents that are not adversaries
def good_agents(self, world):
return [agent for agent in world.agents if not agent.adversary]
# return all adversarial agents
def adversaries(self, world):
return [agent for agent in world.agents if agent.adversary]
def reward(self, agent, world):
# Agents are rewarded based on minimum agent distance to each landmark
main_reward = self.adversary_reward(agent, world) if agent.adversary else self.agent_reward(agent, world)
return main_reward
def agent_reward(self, agent, world):
# Agents are negatively rewarded if caught by adversaries
rew = 0
shape = False
adversaries = self.adversaries(world)
if shape: # reward can optionally be shaped (increased reward for increased distance from adversary)
for adv in adversaries:
rew += 0.1 * np.sqrt(np.sum(np.square(agent.state.p_pos - adv.state.p_pos)))
if agent.collide:
for a in adversaries:
if self.is_collision(a, agent):
rew -= 10
# agents are penalized for exiting the screen, so that they can be caught by the adversaries
# 智能体离开屏幕会受到惩罚,这样它就可以被对手抓住
def bound(x):
if x < 0.9:
return 0
if x < 1.0:
return (x - 0.9) * 10
return min(np.exp(2 * x - 2), 10)
for p in range(world.dim_p):
x = abs(agent.state.p_pos[p])
rew -= bound(x)
return rew
def adversary_reward(self, agent, world):
# Adversaries are rewarded for collisions with agents
rew = 0
shape = False
agents = self.good_agents(world)
adversaries = self.adversaries(world)
if shape: # reward can optionally be shaped (decreased reward for increased distance from agents)
for adv in adversaries:
rew -= 0.1 * min([np.sqrt(np.sum(np.square(a.state.p_pos - adv.state.p_pos))) for a in agents])
if agent.collide:
for ag in agents:
for adv in adversaries:
if self.is_collision(ag, adv):
rew += 10
return rew
def observation(self, agent, world):
# get positions of all entities in this agent's reference frame
entity_pos = []
for entity in world.landmarks:
if not entity.boundary:
entity_pos.append(entity.state.p_pos - agent.state.p_pos)
# communication of all other agents
comm = []
other_pos = []
other_vel = []
for other in world.agents:
if other is agent: continue
comm.append(other.state.c)
other_pos.append(other.state.p_pos - agent.state.p_pos)
if not other.adversary:
other_vel.append(other.state.p_vel)
# 智能体的速度,智能体的位置,智能体与每个地标的距离,智能体与其他智能体的位置,其他智能体的速度
return np.concatenate([agent.state.p_vel] + [agent.state.p_pos] + entity_pos + other_pos + other_vel)
| simple_world_comm.py | Y | Y | 从论文附带的视频中看到的环境。和简单的标签一样,除了(1) 有食物(蓝色小球),协作智能体在附近会得到奖励,(2) 我们现在有了"森林",把智能体藏在里面,不让外界看到;(3) 有一个"头目对手",可以随时看到智能体,并可以与其他对手沟通,帮助协调追捕。|
相关代码
- make_env.py:
""" Code for creating a multiagent environment with one of the scenarios listed in ./scenarios/. Can be called by using, for example: env = make_env('simple_speaker_listener') After producing the env object, can be used similarly to an OpenAI gym environment. A policy using this environment must output actions in the form of a list for all agents. Each element of the list should be a numpy array, of size (env.world.dim_p + env.world.dim_c, 1). Physical actions precede communication actions in this array. See environment.py for more details. """ def make_env(scenario_name, benchmark=False): ''' Creates a MultiAgentEnv object as env. This can be used similar to a gym environment by calling env.reset() and env.step(). Use env.render() to view the environment on the screen. Input: scenario_name : name of the scenario from ./scenarios/ to be Returns (without the .py extension) benchmark : whether you want to produce benchmarking data 是否要生成基准数据 (usually only done during evaluation)(通常仅在评估期间进行) Some useful env properties (see environment.py): .observation_space : Returns the observation space for each agent .action_space : Returns the action space for each agent .n : Returns the number of Agents ''' from multiagent.environment import MultiAgentEnv import multiagent.scenarios as scenarios # load scenario from script scenario = scenarios.load(scenario_name + ".py").Scenario() # create world world = scenario.make_world() # create multiagent environment if benchmark: env = MultiAgentEnv(world, scenario.reset_world, scenario.reward, scenario.observation, scenario.benchmark_data) else: env = MultiAgentEnv(world, scenario.reset_world, scenario.reward, scenario.observation) return env
- multiagent/scenarios/__init__.py:
import imp import os.path as osp def load(name): pathname = osp.join(osp.dirname(__file__), name) return imp.load_source('', pathname)
- multiagent/environment.py:
import gym from gym import spaces from gym.envs.registration import EnvSpec import numpy as np from multiagent.multi_discrete import MultiDiscrete # environment for all agents in the multiagent world # currently code assumes that no agents will be created/destroyed at runtime! class MultiAgentEnv(gym.Env): metadata = { 'render.modes' : ['human', 'rgb_array'] } def __init__(self, world, reset_callback=None, reward_callback=None, observation_callback=None, info_callback=None, done_callback=None, shared_viewer=True): self.world = world self.agents = self.world.policy_agents # set required vectorized gym env property self.n = len(world.policy_agents) # scenario callbacks self.reset_callback = reset_callback self.reward_callback = reward_callback self.observation_callback = observation_callback self.info_callback = info_callback self.done_callback = done_callback # environment parameters self.discrete_action_space = True # if true, action is a number 0...N, otherwise action is a one-hot N-dimensional vector self.discrete_action_input = False # if true, even the action is continuous, action will be performed discretely self.force_discrete_action = world.discrete_action if hasattr(world, 'discrete_action') else False # if true, every agent has the same reward self.shared_reward = world.collaborative if hasattr(world, 'collaborative') else False self.time = 0 # configure spaces self.action_space = [] self.observation_space = [] for agent in self.agents: total_action_space = [] # physical action space if self.discrete_action_space: u_action_space = spaces.Discrete(world.dim_p * 2 + 1) else: u_action_space = spaces.Box(low=-agent.u_range, high=+agent.u_range, shape=(world.dim_p,), dtype=np.float32) if agent.movable: total_action_space.append(u_action_space) # communication action space if self.discrete_action_space: c_action_space = spaces.Discrete(world.dim_c) else: c_action_space = spaces.Box(low=0.0, high=1.0, shape=(world.dim_c,), dtype=np.float32) if not agent.silent: total_action_space.append(c_action_space) # total action space if len(total_action_space) > 1: # all action spaces are discrete, so simplify to MultiDiscrete action space if all([isinstance(act_space, spaces.Discrete) for act_space in total_action_space]): act_space = MultiDiscrete([[0, act_space.n - 1] for act_space in total_action_space]) else: act_space = spaces.Tuple(total_action_space) self.action_space.append(act_space) else: self.action_space.append(total_action_space[0]) # observation space obs_dim = len(observation_callback(agent, self.world)) self.observation_space.append(spaces.Box(low=-np.inf, high=+np.inf, shape=(obs_dim,), dtype=np.float32)) agent.action.c = np.zeros(self.world.dim_c) # rendering self.shared_viewer = shared_viewer if self.shared_viewer: self.viewers = [None] else: self.viewers = [None] * self.n self._reset_render() def step(self, action_n): obs_n = [] reward_n = [] done_n = [] info_n = {'n': []} self.agents = self.world.policy_agents # set action for each agent for i, agent in enumerate(self.agents): self._set_action(action_n[i], agent, self.action_space[i]) # advance world state self.world.step() # record observation for each agent for agent in self.agents: obs_n.append(self._get_obs(agent)) reward_n.append(self._get_reward(agent)) done_n.append(self._get_done(agent)) info_n['n'].append(self._get_info(agent)) # all agents get total reward in cooperative case reward = np.sum(reward_n) if self.shared_reward: reward_n = [reward] * self.n return obs_n, reward_n, done_n, info_n def reset(self): # reset world self.reset_callback(self.world) # reset renderer self._reset_render() # record observations for each agent obs_n = [] self.agents = self.world.policy_agents for agent in self.agents: obs_n.append(self._get_obs(agent)) return obs_n # get info used for benchmarking def _get_info(self, agent): if self.info_callback is None: return {} return self.info_callback(agent, self.world) # get observation for a particular agent def _get_obs(self, agent): if self.observation_callback is None: return np.zeros(0) return self.observation_callback(agent, self.world) # get dones for a particular agent # unused right now -- agents are allowed to go beyond the viewing screen def _get_done(self, agent): if self.done_callback is None: return False return self.done_callback(agent, self.world) # get reward for a particular agent def _get_reward(self, agent): if self.reward_callback is None: return 0.0 return self.reward_callback(agent, self.world) # set env action for a particular agent def _set_action(self, action, agent, action_space, time=None): agent.action.u = np.zeros(self.world.dim_p) agent.action.c = np.zeros(self.world.dim_c) # process action if isinstance(action_space, MultiDiscrete): act = [] size = action_space.high - action_space.low + 1 index = 0 for s in size: act.append(action[index:(index+s)]) index += s action = act else: action = [action] if agent.movable: # physical action if self.discrete_action_input: agent.action.u = np.zeros(self.world.dim_p) # process discrete action if action[0] == 1: agent.action.u[0] = -1.0 if action[0] == 2: agent.action.u[0] = +1.0 if action[0] == 3: agent.action.u[1] = -1.0 if action[0] == 4: agent.action.u[1] = +1.0 else: if self.force_discrete_action: d = np.argmax(action[0]) action[0][:] = 0.0 action[0][d] = 1.0 if self.discrete_action_space: agent.action.u[0] += action[0][1] - action[0][2] agent.action.u[1] += action[0][3] - action[0][4] else: agent.action.u = action[0] sensitivity = 5.0 if agent.accel is not None: sensitivity = agent.accel agent.action.u *= sensitivity action = action[1:] if not agent.silent: # communication action if self.discrete_action_input: agent.action.c = np.zeros(self.world.dim_c) agent.action.c[action[0]] = 1.0 else: agent.action.c = action[0] action = action[1:] # make sure we used all elements of action assert len(action) == 0 # reset rendering assets def _reset_render(self): self.render_geoms = None self.render_geoms_xform = None # render environment def render(self, mode='human'): if mode == 'human': alphabet = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ' message = '' for agent in self.world.agents: comm = [] for other in self.world.agents: if other is agent: continue if np.all(other.state.c == 0): word = '_' else: word = alphabet[np.argmax(other.state.c)] message += (other.name + ' to ' + agent.name + ': ' + word + ' ') print(message) for i in range(len(self.viewers)): # create viewers (if necessary) if self.viewers[i] is None: # import rendering only if we need it (and don't import for headless machines) #from gym.envs.classic_control import rendering from multiagent import rendering self.viewers[i] = rendering.Viewer(700,700) # create rendering geometry if self.render_geoms is None: # import rendering only if we need it (and don't import for headless machines) #from gym.envs.classic_control import rendering from multiagent import rendering self.render_geoms = [] self.render_geoms_xform = [] for entity in self.world.entities: geom = rendering.make_circle(entity.size) xform = rendering.Transform() if 'agent' in entity.name: geom.set_color(*entity.color, alpha=0.5) else: geom.set_color(*entity.color) geom.add_attr(xform) self.render_geoms.append(geom) self.render_geoms_xform.append(xform) # add geoms to viewer for viewer in self.viewers: viewer.geoms = [] for geom in self.render_geoms: viewer.add_geom(geom) results = [] for i in range(len(self.viewers)): from multiagent import rendering # update bounds to center around agent cam_range = 1 if self.shared_viewer: pos = np.zeros(self.world.dim_p) else: pos = self.agents[i].state.p_pos self.viewers[i].set_bounds(pos[0]-cam_range,pos[0]+cam_range,pos[1]-cam_range,pos[1]+cam_range) # update geometry positions for e, entity in enumerate(self.world.entities): self.render_geoms_xform[e].set_translation(*entity.state.p_pos) # render to display or array results.append(self.viewers[i].render(return_rgb_array = mode=='rgb_array')) return results # create receptor field locations in local coordinate frame def _make_receptor_locations(self, agent): receptor_type = 'polar' range_min = 0.05 * 2.0 range_max = 1.00 dx = [] # circular receptive field if receptor_type == 'polar': for angle in np.linspace(-np.pi, +np.pi, 8, endpoint=False): for distance in np.linspace(range_min, range_max, 3): dx.append(distance * np.array([np.cos(angle), np.sin(angle)])) # add origin dx.append(np.array([0.0, 0.0])) # grid receptive field if receptor_type == 'grid': for x in np.linspace(-range_max, +range_max, 5): for y in np.linspace(-range_max, +range_max, 5): dx.append(np.array([x,y])) return dx # vectorized wrapper for a batch of multi-agent environments # assumes all environments have the same observation and action space class BatchMultiAgentEnv(gym.Env): metadata = { 'runtime.vectorized': True, 'render.modes' : ['human', 'rgb_array'] } def __init__(self, env_batch): self.env_batch = env_batch @property def n(self): return np.sum([env.n for env in self.env_batch]) @property def action_space(self): return self.env_batch[0].action_space @property def observation_space(self): return self.env_batch[0].observation_space def step(self, action_n, time): obs_n = [] reward_n = [] done_n = [] info_n = {'n': []} i = 0 for env in self.env_batch: obs, reward, done, _ = env.step(action_n[i:(i+env.n)], time) i += env.n obs_n += obs # reward = [r / len(self.env_batch) for r in reward] reward_n += reward done_n += done return obs_n, reward_n, done_n, info_n def reset(self): obs_n = [] for env in self.env_batch: obs_n += env.reset() return obs_n # render environment def render(self, mode='human', close=True): results_n = [] for env in self.env_batch: results_n += env.render(mode, close) return results_n
- multiagent/core.py:
import numpy as np # physical/external base state of all entites class EntityState(object): def __init__(self): # physical position self.p_pos = None # physical velocity self.p_vel = None # state of agents (including communication and internal/mental state) class AgentState(EntityState): def __init__(self): super(AgentState, self).__init__() # communication utterance self.c = None # action of the agent class Action(object): def __init__(self): # physical action self.u = None # communication action self.c = None # properties and state of physical world entity class Entity(object): def __init__(self): # name self.name = '' # properties: self.size = 0.050 # entity can move / be pushed self.movable = False # entity collides with others self.collide = True # material density (affects mass) self.density = 25.0 # color self.color = None # max speed and accel self.max_speed = None self.accel = None # state self.state = EntityState() # mass self.initial_mass = 1.0 @property def mass(self): return self.initial_mass # properties of landmark entities class Landmark(Entity): def __init__(self): super(Landmark, self).__init__() # properties of agent entities class Agent(Entity): def __init__(self): super(Agent, self).__init__() # agents are movable by default self.movable = True # cannot send communication signals self.silent = False # cannot observe the world self.blind = False # physical motor noise amount self.u_noise = None # communication noise amount self.c_noise = None # control range self.u_range = 1.0 # state self.state = AgentState() # action self.action = Action() # script behavior to execute self.action_callback = None # multi-agent world class World(object): def __init__(self): # list of agents and entities (can change at execution-time!) self.agents = [] self.landmarks = [] # communication channel dimensionality self.dim_c = 0 # position dimensionality self.dim_p = 2 # color dimensionality self.dim_color = 3 # simulation timestep self.dt = 0.1 # physical damping self.damping = 0.25 # contact response parameters self.contact_force = 1e+2 self.contact_margin = 1e-3 # return all entities in the world @property def entities(self): return self.agents + self.landmarks # return all agents controllable by external policies @property def policy_agents(self): return [agent for agent in self.agents if agent.action_callback is None] # return all agents controlled by world scripts @property def scripted_agents(self): return [agent for agent in self.agents if agent.action_callback is not None] # update state of the world def step(self): # set actions for scripted agents for agent in self.scripted_agents: agent.action = agent.action_callback(agent, self) # gather forces applied to entities p_force = [None] * len(self.entities) # apply agent physical controls p_force = self.apply_action_force(p_force) # apply environment forces p_force = self.apply_environment_force(p_force) # integrate physical state self.integrate_state(p_force) # update agent state for agent in self.agents: self.update_agent_state(agent) # gather agent action forces def apply_action_force(self, p_force): # set applied forces for i,agent in enumerate(self.agents): if agent.movable: noise = np.random.randn(*agent.action.u.shape) * agent.u_noise if agent.u_noise else 0.0 p_force[i] = agent.action.u + noise return p_force # gather physical forces acting on entities def apply_environment_force(self, p_force): # simple (but inefficient) collision response for a,entity_a in enumerate(self.entities): for b,entity_b in enumerate(self.entities): if(b <= a): continue [f_a, f_b] = self.get_collision_force(entity_a, entity_b) if(f_a is not None): if(p_force[a] is None): p_force[a] = 0.0 p_force[a] = f_a + p_force[a] if(f_b is not None): if(p_force[b] is None): p_force[b] = 0.0 p_force[b] = f_b + p_force[b] return p_force # integrate physical state def integrate_state(self, p_force): for i,entity in enumerate(self.entities): if not entity.movable: continue entity.state.p_vel = entity.state.p_vel * (1 - self.damping) if (p_force[i] is not None): entity.state.p_vel += (p_force[i] / entity.mass) * self.dt if entity.max_speed is not None: speed = np.sqrt(np.square(entity.state.p_vel[0]) + np.square(entity.state.p_vel[1])) if speed > entity.max_speed: entity.state.p_vel = entity.state.p_vel / np.sqrt(np.square(entity.state.p_vel[0]) + np.square(entity.state.p_vel[1])) * entity.max_speed entity.state.p_pos += entity.state.p_vel * self.dt def update_agent_state(self, agent): # set communication state (directly for now) if agent.silent: agent.state.c = np.zeros(self.dim_c) else: noise = np.random.randn(*agent.action.c.shape) * agent.c_noise if agent.c_noise else 0.0 agent.state.c = agent.action.c + noise # get collision forces for any contact between two entities def get_collision_force(self, entity_a, entity_b): if (not entity_a.collide) or (not entity_b.collide): return [None, None] # not a collider if (entity_a is entity_b): return [None, None] # don't collide against itself # compute actual distance between entities delta_pos = entity_a.state.p_pos - entity_b.state.p_pos dist = np.sqrt(np.sum(np.square(delta_pos))) # minimum allowable distance dist_min = entity_a.size + entity_b.size # softmax penetration k = self.contact_margin penetration = np.logaddexp(0, -(dist - dist_min)/k)*k force = self.contact_force * delta_pos / dist * penetration force_a = +force if entity_a.movable else None force_b = -force if entity_b.movable else None return [force_a, force_b]