字符集是指一种从二进制编码到某类字符符号的映射,可以参考如何使用一个字节来表示英文字母。“校对”是指一组用于某个字符集的排序规则。MySQL4.1和之后的版本中,每一类编码字符都有其对应的字符集和校对规则。MySQL对各种字符集的支持非常完善,但是这也带来了一定的复杂性,某些场景下甚至会有一定的性能牺牲。(另外,曾经Drizzle放弃了所有的字符集,所有字符全部统一使用UTF-8。)
本节将解释在实际使用中,你可能最需要的一些设置和功能。如果想了解更多细节,可以详细地阅读MySQL官方手册的相关章节。
(基于5.X,新版本会有很多的优化和选择,详情翻阅官方文档)
1.MySQL如何使用字符集
每种字符集都可能有多种校对规则,并且都有一个默认的校对规则。每个校对规则都是针对某个特定的字符集的,和其他的字符集没有关系。校对规则和字符集总是一起使用的,所以后面我们将这样的组合也统称为一个字符集。
MySQL有很多的选项用于控制字符集。这些选项和字符集很容易混淆,一定要记住:只有基于字符的值才真正的“有”字符集的概念。对于其他类型的值,字符集只是一个设置,指定用哪一种字符集来做比较或者其他操作。基于字符的值能存放在某列中、査询的字符串中、表达式的计算结果中或者某个用户变量中,等等。
MySQ的设置可以分为两类:创建对象时的默认值、在服务器和客户端通信时的设置。
创建对象时的默认设置
MySQL服务器有默认的字符集和校对规则,每个数据库也有自己的默认值,每个表也有自己的默认值。这是一个逐层继承的默认设置,最终最靠底层的默认设置将影响你创建的对象。这些默认值,至上而下地告诉MySQL应该使用什么字符集来存储某个列。
在这个“阶梯”的每一层,你都可以指定一个特定的字符集或者让服务器使用它的默认值:
- 创建数据库的时候,将根据服务器上的character_set_server设置来设定该数据库的默认字符集。
- 创建表的时候,将根据数据库的字符集设置指定这个表的字符集设置。
- 创建列的时候,将根据表的设置指定列的字符集设置。
需要记住的是,真正存放数据的是列,所以更高“阶梯”的设置只是指定默认值。一个表的默认字符集设置无法影响存储在这个表中某个列的值。只有当创建列而没有为列指定字符集的时候,如果没有指定字符集,表的默认字符集才有作用。
服务器和客户端通信时的设置
当服务器和客户端通信的时候,它们可能使用不同的字符集。这时,服务器端将进行必要的翻译转换工作:
- 服务器端总是假设客户端是按照character_set_client设置的字符来传输数据和SQL语句的。
- 当服务器收到客户端的SQL语句时,它先将其转换成字符集character_set_connection。它还使用这个设置来决定如何将数据转换成字符串。
- 当服务器端返回数据或者错误信息给客户端时,它会将其转换成character_set_result。
图7-2展示了这个过程
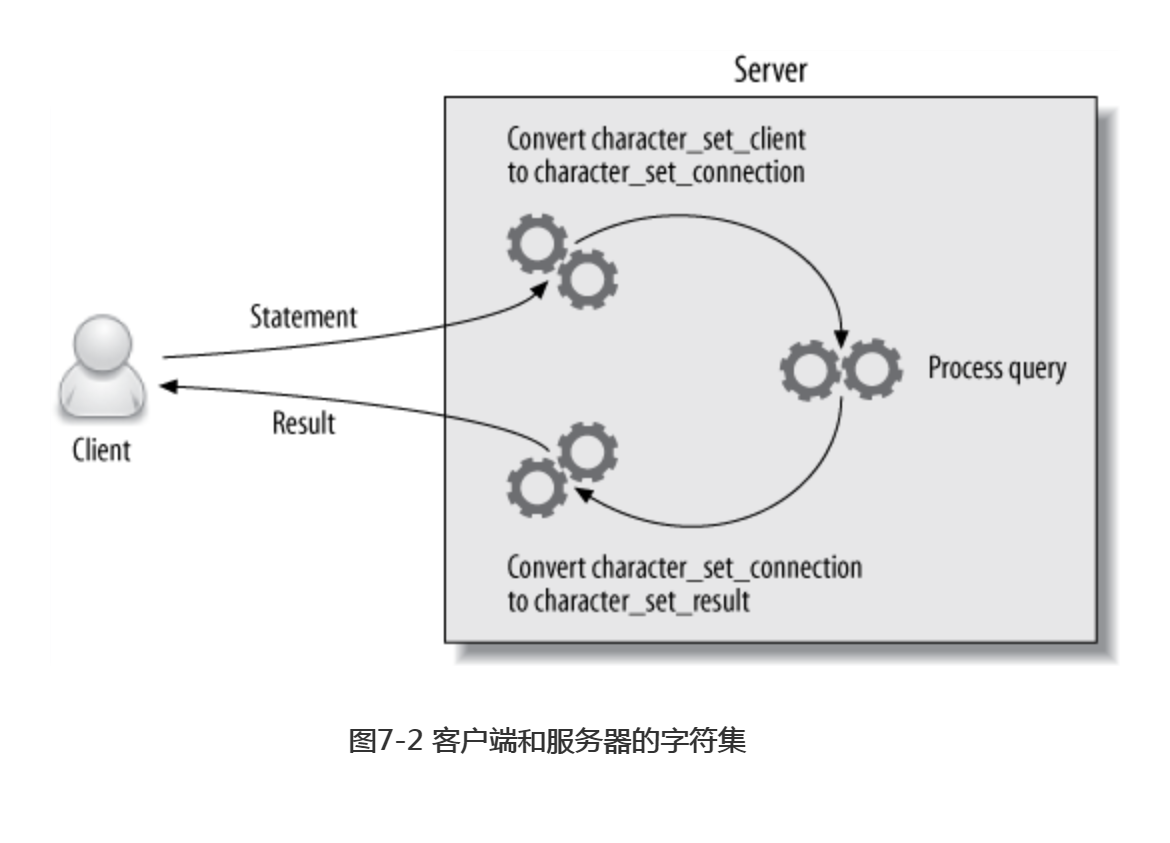
根据需要,可以使用SET NAMES或者SET CHARACTER SET语句来改变上面的设置。不过在服务器上使用这个命令只能改变服务器端的设置。客户端程序和客户端的API也需要使用正确的字符集才能避免在通信时出现问题。
假设使用latin1字符集(这是默认字符集)打开一个连接,并使用SET NAMES utf8来告诉服务器客户端将使用UTF-8字符集来传输数据。这样就创建了一个不匹配的字符集,可能会导致一些错误甚至出现一些安全性问题。应当先设置客户端字符集然后使用函数 mysql_real_escape_string()在需要的时候进行转义。在PHP中,可以使用mysql_set_charset()来修改客户端的字符集。
MySQL如何比较两个字符串的大小
如果比较的两个字符串的字符集不同,MySQL会先将其转成同一个字符集再进行比较。如果两个字符集不兼容的话,则会抛出错误,例如“ERROR 1267(HY000) illegal mix of collations”。这种情况下需要通过函数CONVERT()显式地将其中一个字符串的字符集转成一个兼容的字符集。MySQL5.0和更新的版本经常会做这样的隐式转换,所以这类错误通常是在MySQL4.1中比较常见。
MySQL还会为每个字符串设置一个“可转换性”。这个设置决定了值的字符集的优先级,因而会影响MySQL做字符集隐式转换后的值。另外,也可以使用函数CHARSET()、C0LLATI0N()、和C0ERCIBILITY()来定位各种字符集相关的错误。
还可以使用前缀和COLLATE子句来指定字符串的字符集或者校对字符集。例如,下面的 示例中使用了前缀(由下画线开始)来指定utf8字符集,还使用了COLLATE子句指定了使用二进制校对规则:
mysql> SELECT _utf8 'hello world' COLLATE utf8_bin; +--------------------------------------+ | _utf8 'hello world' COLLATE utf8_bin | +--------------------------------------+ | hello world | +--------------------------------------+
一些特殊情况
MySQL的字符集行为中还是有一些隐藏的“惊喜”的。下面列举了一些需要注意的地方:
诡异的character set database设置
character_set_database设置的默认值和默认数据库的设置相同。当改变默认数据库的时候,这个变量也会跟着变。所以当连接到MySQL实例上又没有指定要使用的数据库时,默认值会和character_set_server相同。
LOAD DATA INFILE
当使用LOAD DATA INFILE的时候,数据库总是将文件中的字符按照字符集character_set_database来解析。在MySQL5.0和更新的版本中,可以在LOAD DATA INFILE中使用子句CHARACTER SET来设定字符集,不过最好不要依赖这个设定。我们发现指定字符集最好的方式是先使用USE指定数据库,再执行SET NAMES来设定字符集,最后再加载数据。MySQL在加载数据的时候,总是以同样的字符集处理所有数据,而不管表中的列是否有不同的字符集设定。
SELECT INTO OUTFILE
MySQL会将SELECT INTO 0UTFILE的结果不做任何转码地写入文件。目前,除了使用函数CONVERT()将所有的列都做一次转码外,还没有什么别的办法能够指定输出的字符集。
嵌入式转义序列
MySQL会根据character_set_client的设置来解析转义序列,即使是字符串中包含前缀或者COLLATE子句也一样。这是因为解析器在处理字符串中的转义字符时,完全不关心校对规则——对解析器来说,前缀并不是一个指令,它只是一个关键字而已。
2.选择字符集和校对规则
讨论:极简原则
在一个数据库中使用多个不同的字符集是一件很让人头疼的事情,字符集之间的不兼容问题会很难缠。有时候,一切都看起来正常,但是当某个特殊字符出现的时候,所有类型的操作都可能会无法进行(例如多表之间的关联)。你可以使用ALTER TABLE命令将对应列转成相互兼容的字符集,还可以使用编码前綴和COLLATE子句将对应的列值转成兼容的编码。
正确的方法是,最好先为服务器(或者数据库)选择一个合理的字符集。然后根据不同的实际情况,让某些列选择合适的字符集。
MySQL4.1和之后的版本支持很多的字符集和校对规则,包括支持使用Unicode编码的 多字节UTF-8字符集(MySQL支持UTF-8的一个三字节子集,这几乎可以包含世界上的所有字符集)。可以使用命令SHOW CHARACTERSET和SHOW COLLATION来查看MySQL支持的字符集和校对规则。
对于校对规则通常需要考虑的一个问题是,是否以大小写敏感的方式比较字符串,或者是以字符串编码的二进制值来比较大小。它们对应的校对规则的前缀分别是_cs、_ci和_bin,根据需要很容易选择。大小写敏感和二进制校对规则的不同之处在于,二进制校对规则直接使用字符的字节进行比较,而大小写敏感的校对规则在多字节字符集时,如德语,有更复杂的比较规则。
在显式设置字符集的时候,并不是必须同时指定字符集和校对规则的名字。如果缺失了其中一个或者两个,MySQL会使用可能的默认值来进行填充。表7-2表示了MySQL如何选择字符集和校对规则。
| 表7-2:MySQL如何选择字符集和校对规则 | ||
| 用户设置 | 返回结果的字符集 | 返回结果的校对规则 |
| 同时设置字符集和校对规则 | 与用户设置相同 | 与用户设置相同 |
| 仅设置字符集 | 与用户设置相同 | 与字符集的默认校对规则相同 |
| 仅设置校对规则 | 与校对规则对应的字符集相同 | 与用户设置相同 |
| 都未设置 | 使用默认值 | 使用默认值 |
下面的命令展示了在创建数据库、表、列的时候如何显式地指定字符集和校对规则:
CREATE DATABASE d CHARSET latin1; CREATE TABLE d.t( col1 CHAR(1), col2 CHAR(1) CHARSET utf8, col3 CHAR(1) COLLATE latin1_bin ) DEFAULT CHARSET=cp125
这个表最后的字符集和校对规则如下:
mysql> SHOW FULL COLUMNS FROM d.t;
+------+---------+-------------------+
|Field | Type | Collation |
+------+---------+-------------------+
|col1 | char(1) | cp1251_general_ci |
|col2 | char(1) | utf8_general_ci |
|col3 | char(1) | latin1_bin |
+------+---------+-------------------+
3.字符集和校对规则如何影响查询
某些字符集和校对规则可能会需要更多的CPU操作,可能会消耗更多的内存和存储空间,甚至还会影响索引的正常使用。所以在选择字符集的时候,也有一些需要注意的地方。
不同的字符集和校对规则之间的转换可能会带来额外的系统开销。例如,数据表sakila.film在列title上有索引,可以加速下面的ORDER BY查询:
mysql> EXPLAIN SELECT title, release_year FROM sakila.film ORDER BY titleG *************************** 1. row *************************** id: 1 select_type: SIMPLE table: film type: index possible_keys: NULL key: idx_title key_len: 767 ref: NULL rows: 953 Extra:
只有排序査询要求的字符集与服务器数据的字符集相同的时候,才能使用索引进行排序。索引根据数据列的校对规则进行排序,这里使用的是utf8_general_ci。如果希望使用别的校对规则进行排序,那么MySQL就需要使用文件排序:
mysql> EXPLAIN SELECT title, release_year -> FROM sakila.film ORDER BY title COLLATE utf8_binG *************************** 1. row *************************** id: 1 select_type: SIMPLE table: film type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 953 Extra: Using filesort
为了能够适应各种字符集,包括客户端字符集、在査询中显式指定的字符集,MySQL会在需要的时候进行字符集转换。例如,当使用两个字符集不同的列来关联两个表的时候,MySQL会尝试转换其中一个列的字符集。这和在数据列外面封装一个函数一样,会让MySQL无法使用这个列上的索引。如果你不确定MySQL内部是否做了这种转换,可以在EXPLAIN EXTENDED后使用SHOW WARNINGS来査看MySQL是如何处理的。从输出中可以看到查询中使用的字符集,也可以看出MySQL是否做了字符集转换操作。
UTF-8是一种多字节编码,它存储一个字符会使用变长的字节数(一到三个字节)。在MySQL内部,通常使用一个定长的空间来存储字符串,再进行相关操作,这样做的目的是希望总是保证缓存中有足够的空间来存储字符串。例如,一个编码是UTF-8的CHAR(10)需要30个字节,即使最终存储的时候没有存储任何“多字节”字符也是一样。变长的字段类型(VARCHAR TEXT)存储在磁盘上时不会有这个困扰,但当它存储在临时表中用来处理或者排序时,也总是会分配最大可能的长度。
在多字节字符集中,一个字符不再是一个字节。所以,在MySQL中有两个函数LENGTH()和CHAR_LENGTH{)来计算字符串的长度,在多字节字符集中,这两个函数的返回结果会不同。如果使用的是多字节字符集,那么确保在统计字符集的时候使用CHAR_LENGTH()。(例如需要SUBSTRING()操作的时候)。其实,在应用程序中也同样要注意多字节字符集的这个问题。
另一个“惊喜”可能是关于索引限制方面的。如果要索引一个UTF-8字符集的列,MySQL会假设每一个字符都是三个字节,所以最长索引前缀的限制一下缩短到原来的三分之一了:
mysql> CREATE TABLE big_string(str VARCHAR(500), KEY(str)) DEFAULT CHARSET=utf8; Query OK, 0 rows affected, 1 warning (0.06 sec) mysql> SHOW WARNINGS; +---------+------+---------------------------------------------------------+ | Level | Code | Message | +---------+------+---------------------------------------------------------+ | Warning | 1071 | Specified key was too long; max key length is 999 bytes | +---------+------+---------------------------------------------------------+
注意到,MySQL的索引前缀自动缩短到333个字符了:
mysql> SHOW CREATE TABLE big_stringG *************************** 1. row *************************** Table: big_string Create Table: CREATE TABLE `big_string` ( `str` varchar(500) default NULL, KEY `str` (`str`(333)) ) ENGINE=MyISAM DEFAULT CHARSET=utf8
如果你不注意警告信息也没有再重新检査表的定义,可能不会注意到这里仅仅是在该列的前缀上建立了索引。这会对MySQL使用索引有一些影响,例如无法使用索引覆盖扫描。
也有人建议,直接使用UTF-8字符集,“整个世界都清净了”。不过从性能的角度来看这不是一个好主意。根据存储的数据,很多应用无须使用UTF-8字符集,如果坚持使用UTF-8,只会消耗更多的磁盘空间。
在考虑使用什么字符集的时候,需要根据存储的具体内存来决定。例如,存储的内容主要是英文字符,那么即使使用UTF-8也不会消耗太多的存储空间,因为英文字符在UTF_8字符集中仍然使用一个字节。但如果需要存储一些非拉丁语系的字符,如俄语、阿拉伯语,那么区别会很大。如果应用中只需要存储阿拉伯语,那么可以使用cp1256字符集,这个字符集可以用一个字节表示所有的阿拉伯语字符。如果还需要存储别的语言,那么就应该使用UTF-8了,这时相同的阿拉伯语字符会消耗更多的空间。类似地,当从某个具体的语种编码转换成UTF-8时,存储空间的使用会相应增加。如果使用的是InnoDB表,那么字符集的改变可能导致数据的大小超过可以在页内存储的临界值,需要保存在额外的外部存储区,这会导致很严重的空间浪费,还会带来很多空间碎片。
有时候根本不需要使用任何的字符集。通常只有在做大小写无关的比较、排序、字符串 操作(例如SUBSTRINGS的时候才需要使用字符集。如果你的数据库不关心字符集,那么可以直接将所有的东西存储到二进制列中,包括UTF-8编码数据也可以存储在其中。这么做,可能还需要一个列记录字符的编码集。虽然很多人一直都是这么用的,但还是有不少事项需要注意。这会导致很多难以排査的错误,例如,忘记了多个字节才是一个字符时,还继续使用SUBSTRING()和LENGTH()做字符串操作,就会出错。如果可能,建议尽量不要这样做。
4.总结
字符集是一种字节到字符之间的映射,而校对规则是指一个字符集的排序方法。很多人都使用Latin1(默认字符集,对英语和某些欧洲语言有效)或者UTF-8。如果使用的是UTF-8,那么在使用临时表和缓冲区的时候需要注意:MySQL会按照每个字符三个字节的最大占用空间来分配存储空间,这可能消耗更多的内存或者磁盘空间。注意让字符集和MySQL字符集配置相符,否则可能会由于字符集转换让某些索引无法正常使用。