1.在pod中使用宿主机命名空间、端口等资源
pod中的容器通常在分开的Linux命名空间中运行。这些命名空间将容器中的进程与其他容器中,或者宿主机默认命名空间中的进程隔离开来。
例如,每一个pod有自己的IP和端口空间,这是因为它拥有自己的网络命名空间。类似地,每一个pod拥有自己的进程树,因为它有自己的PID命名空间。同样的,pod拥有自己的IPC命名空间,仅允许同一pod内的进程通过进程间通信(Inter Process Communication,简称IPC)机制进行交流。
1.1 在pod中使用宿主节点的网络命名空间
部分pod(特别是系统pod)需要在宿主节点的默认命名空间中运行,以允许它们看到和操作节点级别的资源和设备。例如,某个pod可能需要使用宿主节点上的网络适配器,而不是自己的虚拟网络设备。这可以通过将pod spec中的hostNetwork设置为true实现。
如图13.1所示,在这种情况下,这个pod可以使用宿主节点的网络接口,而不是拥有自己独立的网络。这意味着这个pod没有自己的IP地址;如果这个pod中的某一进程绑定了某个端口,那么该进程将被绑定到宿主节点的端口上。
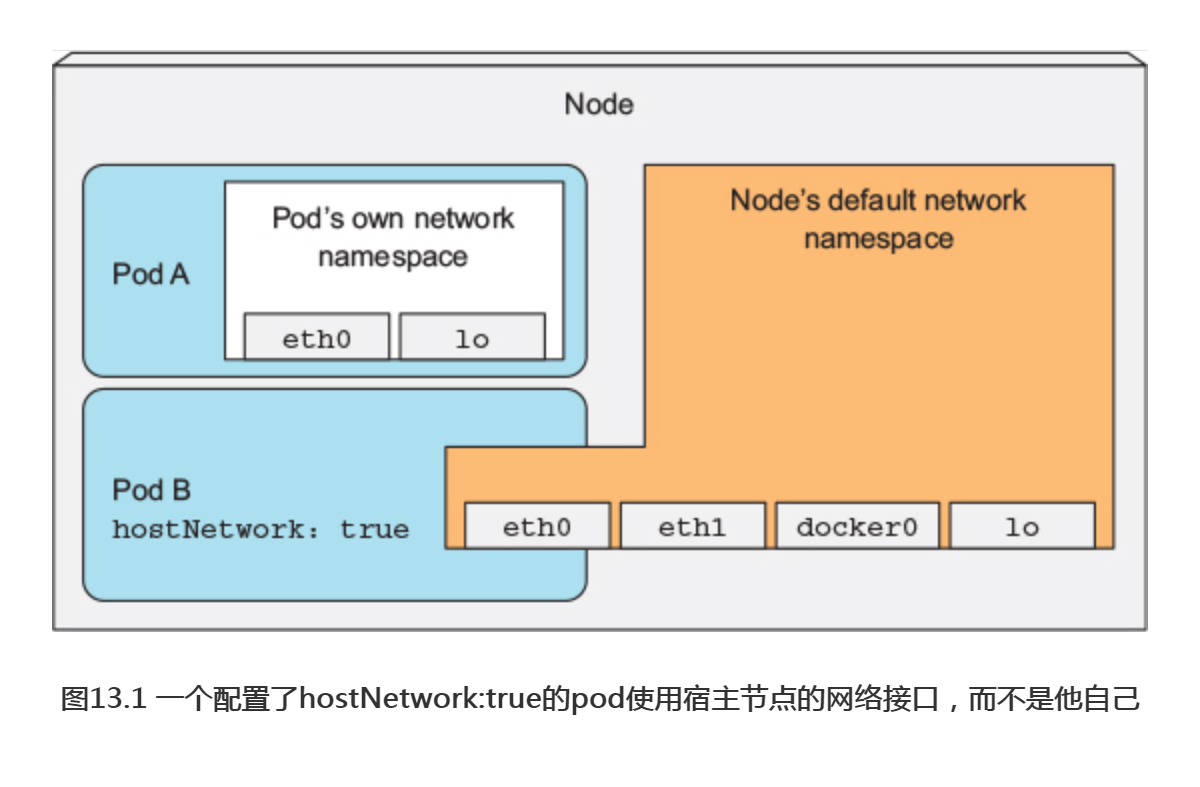
可以尝试运行这样一个pod,以下的代码清单展示了此种pod的一个例子。
#代码13.1 —个使用宿主节点默认的网络命名空间的pod: pod-with-host-network.yaml apiVersion: v1 kind: Pod metadata: name: pod-with-host-network spec: hostNetwork: true #使用宿主节点的网络命名空间 containers: - name: main image: alpine command: ["/bin/sleep", "999999"]
在运行了这个pod之后,可以用如下的命令来验证它确实使用了宿主节点的网络命名空间(例如,它可以看到宿主节点上所有的网络接口)
#代码13.2 使用宿主机网络命名空间的pod网络 $ kubectl exec pod-with-host-network ifconfig docker0 Link encap:Ethernet HWaddr 02:42:14:08:23:47 inet addr:172.17.0.1 Bcast:0.0.0.0 Mask:255.255.0.0 ... eth0 Link encap:Ethernet HWaddr 08:00:27:F8:FA:4E inet addr:10.0.2.15 Bcast:10.0.2.255 Mask:255.255.255.0 ... lo Link encap:Local Loopback inet addr:127.0.0.1 Mask:255.0.0.0 ... veth1178d4f Link encap:Ethernet HWaddr 1E:03:8D:D6:E1:2C inet6 addr: fe80::1c03:8dff:fed6:e12c/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 ...
Kubernetes控制平面组件通过pod部署时(例如,使用kubeadm部署Kubernetes集群),这些pod都会使用hostNetwork选项,让它们的行为与不在pod中运行时相同。
1.2 绑定宿主节点上的端口而不使用宿主节点的网络命名空间
一个与此有关的功能可以让pod在拥有自己的网络命名空间的同时,将端口绑定到宿主节点的端口上。这可以通过配置pod的spec, containers, ports字段中某个容器某一端口的hostPort属性来实现。
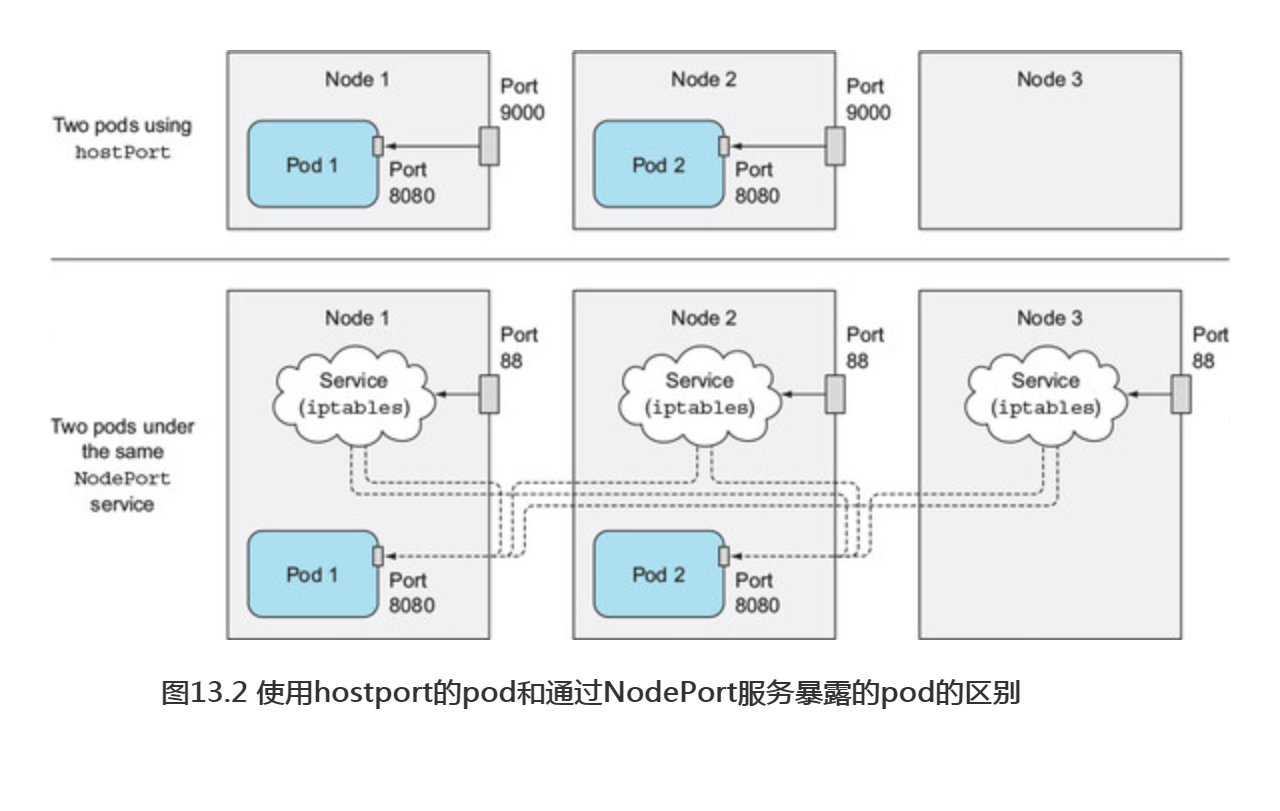
不要混淆使用hostPort的pod和通过NodePort服务暴露的pod。如图13.2 所示,它们是不同的。
在图中首先注意到的是,对于一个使用hostPort的pod,到达宿主节点的端口的连接会被直接转发到pod的对应端口上;然而在NodePort服务中,到达宿主节点的端口的连接将被转发到随机选取的pod上(这个pod可能在其他节点上)。另外一个区别是,对于使用hostPort的pod,仅有运行了这类pod的节点会绑定对应的端口;而NodePort类型的服务会在所有的节点上绑定端口,即使这个节点上没有运行对应的pod(如图中所示的节点3)。
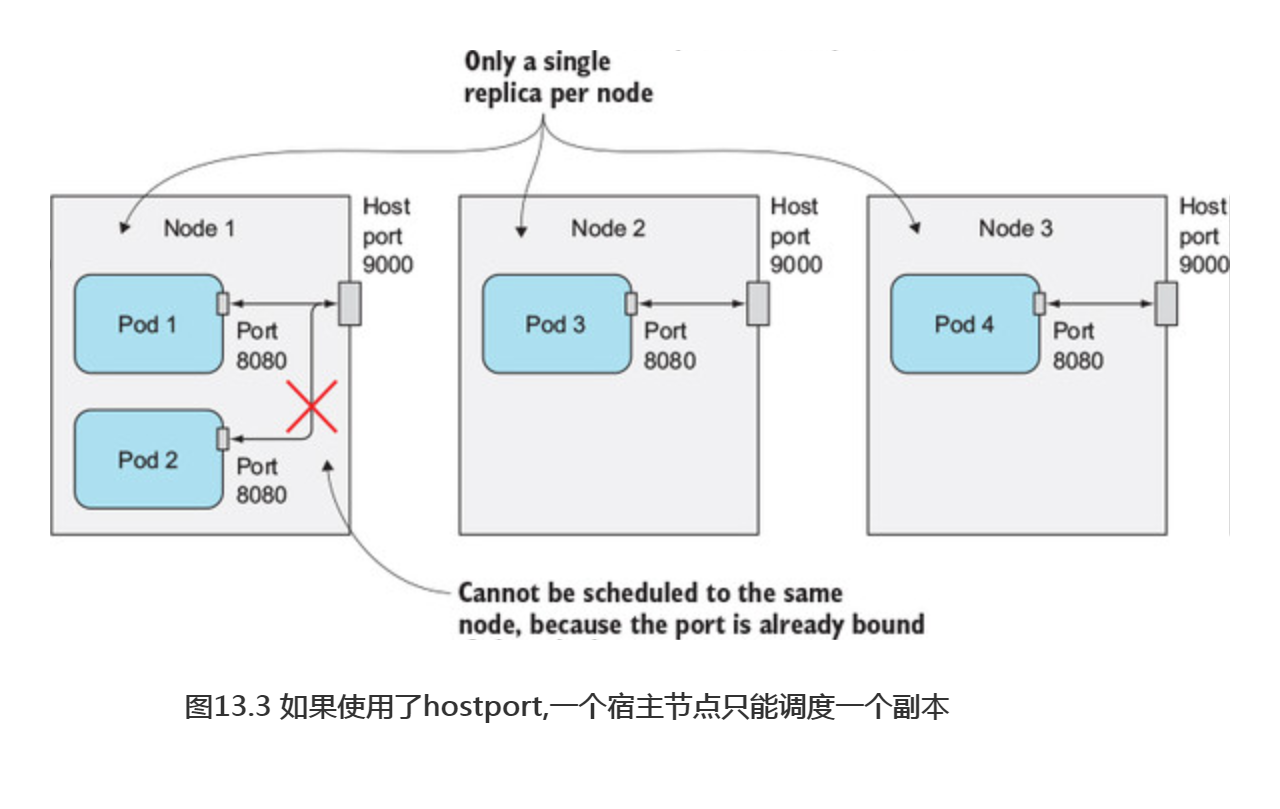
很重要的一点是,如果一个pod绑定了宿主节点上的一个特定端口,每个宿主节点只能调度一个这样的pod实例,因为两个进程不能绑定宿主机上的同一个端口。调度器在调度pod时会考虑这一点,所以它不会把两个这样的pod调度到同一个节点上(如图13.3所示),如果要在3个节点上部署4个这样的pod副本,只有3个副本能够成功部署(剩余1个pod保持Pending状态)。
如何在pod的YAML定义文件中定义hostPort选项。以下代码清单展示了一个运行kubia pod,并将该pod绑定到宿主机的9000端口的YAML描述文件。
#代码13.3 将pod中的一个端口绑定到宿主节点默认网络命名空间的端口:kubia-hostport.yaml apiVersion: v1 kind: Pod metadata: name: kubia-hostport spec: containers: - image: luksa/kubia name: kubia ports: - containerPort: 8080 #该容器可以通过pod IP 8080 端口访问 hostPort: 9000 #也可以通过所在节点的9000端口访问 protocol: TCP
创建这个pod之后,可以通过它所在节点的9000端口访问这个pod。有多个宿主节点时,并不能通过其他宿主节点的同一端口访问该pod。
hostPort功能最初是用于暴露通过DeamonSet部署在每个节点上的系统服务的。最初,这个功能也用于保证一个pod的两个副本不被调度到同一节点上,但是现在有更好的方法来实现这一需求。这个在<pod的高级调度中介绍>。
1.3 使用宿主节点的PID与IPC命名空间
pod spec中的hostPID和hostIPC选项与hostNetwork相似。当它们被设置为true时,Pod中的容器会使用宿主节点的PID和IPC命名空间,分别允许它们看到宿主机上的全部进程,或通过IPC机制与它们通信。以下代码清单是一个使用hostPID和hostIPC的pod的例子。
#代码 13.4使用宿主节点的PID和IPC命名空间:pod-with-host-pid-and-ipc.yaml apiVersion: v1 kind: Pod metadata: name: pod-with-host-pid-and-ipc spec: hostPID: true #希望使用这个pod使用宿主节点的PID命名空间 hostIPC: true #同样,希望使用宿主几点的IPC命名空间 containers: - name: main image: alpine command: ["/bin/sleep", "999999"]
pod中通常只能看到自己内部的进程,但在这个pod的容器中列出进程,可以看到宿主机上的所有进程,而不仅仅是容器内的进程,就如同以下的代码清单所示。
#代码13.5 配置hostPID: true的pod内可见的进程列表 $ kubectl exec pod-with-host-pid-and-ipc ps aux PID USER TIME COMMAND 1 root 0:01 /usr/lib/systemd/systemd --switched-root --system ... 2 root 0:00 [kthreadd] 3 root 0:00 [ksoftirqd/0] 5 root 0:00 [kworker/0:0H] 6 root 0:00 [kworker/u2:0] 7 root 0:00 [migration/0] 8 root 0:00 [rcu_bh] 9 root 0:00 [rcu_sched] 10 root 0:00 [watchdog/0] ...
将hostIPC设置为true, pod中的进程就可以通过进程间通信机制与宿主机上的其他所有进程进行通信。
2.配置节点的安全上下文
除了让pod使用宿主的命名空间外,还可以在pod或其所属容器的描述中通过security-Context选项配置其他与安全性相关的特性。这个选项可以运用于整个pod,或者每个pod中单独的容器。
了解安全上下文中可以配置的内容
配置安全上下文可以允许你做很多事:
-
- 指定容器中运行进程的用户(用户ID)。
- 阻止容器使用root用户运行(容器的默认运行用户通常在其镜像中指定,所以可能需要阻止容器以root用户运行)。
- 使用特权模式运行容器,使其对宿主节点的内核具有完全的访问权限。
- 与以上相反,通过添加或禁用内核功能,配置细粒度的内核访问权限。
- 设置SELinux (Security Enhaced Linux,安全增强型Linux)选项,加强对容器的限制。
- 阻止进程写入容器的根文件系统。
以下内容将开始探索这些选项的细节。
运行pod而不配置安全上下文
首先,运行一个没有任何安全上下文配置的pod (不指定任何安全上下文选项), 与配置了安全上下文的pod形成对照:
$ kubectl run pod-with-defaults --image alpine --restart Never -- /bin/sleep 999999 pod "pod-with-defaults" created
来看一看这个容器中的用户ID和组ID,以及它所属的用户组。这可以通过在容器中运行id命令查看。
$ kubectl exec pod-with-defaults id uid=0(root) gid=0(root) groups=0(root), 1(bin), 2(daemon), 3(sys), 4(adm), 6(disk), 10(wheel), 11(floppy), 20(dialout), 26(tape), 27(video)
这个容器在用户ID(uid)为0的用户,即root,用户组ID(gid)为0(同样是root)的用户组下运行。它同样还属于一些其他的用户组。
注意:容器运行时使用的用户在镜像中指定。在Dockerfile中,这是通过使用USER命令实现的。如果该命令被省略,容器将使用root用户运行。
现在来运行一个使用特定用户运行容器的pod。
2.1 使用指定用户运行容器
为了使用一个与镜像中不同的用户ID来运行pod,需要设置该pod的securityContext.runAsUser选项。可以通过以下代码清单来运行一个使用guest用户运行的容器,该用户在alpine镜像中的用户ID为405。
#代码13.6 使用特定用户运行容器:pod-as-user-guest.yaml apiVersion: v1 kind: Pod metadata: name: pod-as-user-guest spec: containers: - name: main image: alpine command: ["/bin/sleep", "999999"] securityContext: runAsUser: 405 #需要指明一个用户ID,而不是用户名(id405对应guest用户)
现在可以像之前一样在pod中运行id命令,查看runAsUser选项的效果:
$ kubectl exec pod-as-user-guest id uid=405(guest) gid=100(users)
与要求的一样,该容器在guest用户下运行。
2.2 阻止容器以root用户运行
如果你不关心容器是哪个用户运行的,只是希望阻止以root用户运行呢?
假设有一个已经部署好的pod,它使用一个在Dockerfile中使用USER daemon命令制作的镜像,使其在daemon用户下运行。如果攻击者获取了访问镜像仓库的权限,并上传了一个标签完全相同,在root用户下运行的镜像,会发生什么?当Kubernetes的调度器运行该pod的新实例时,kubelet会下载攻击者的镜像,并运行该镜像中的任何代码。
虽然容器与宿主节点基本上是隔离的,使用root用户运行容器中的进程仍然是一种不好的实践。例如,当宿主节点上的一个目录被挂载到容器中时,如果这个容器中的进程使用了root用户运行,它就拥有该目录的完整访问权限;如果用非root用户运行,则没有完整权限。
为了防止以上的攻击场景发生,可以进行配置,使得pod中的容器以非root用户运行,如以下的代码清单所示。
#代码13.7 阻止容器使用root用户运行:pod-run-as-non-root.yaml apiVersion: v1 kind: Pod metadata: name: pod-run-as-non-root spec: containers: - name: main image: alpine command: ["/bin/sleep", "999999"] securityContext: runAsNonRoot: true #这个容器只予许以非root用户运行
部署这个pod之后,它会被成功调度,但是不允许运行:
$ kubectl get po pod-run-as-non-root NAME READY STATUS pod-run-as-non-root 0/1 container has runAsNonRoot and image will run as root
现在,即使攻击者篡改了镜像,他们也无法做出进一步的破坏。
2.3 使用特权模式运行pod
有时pod需要做它们的宿主节点上能够做的任何事,例如操作被保护的系统设备,或使用其他在通常容器中不能使用的内核功能。
这种pod的一个样例就是kube-proxy pod,这种pod修改宿主机的iptables规则来让Kubernetes中的服务规则生效。使用kubeadm部署集群时,会看到每个节点上都运行了kube-proxy pod,并且可以查看YAML描述文件中所有使用到的特殊特性。
为获取宿主机内核的完整权限,该pod需要在特权模式下运行。这可以通过将容器的securityContext中的privileged设置为true实现。可以通过以下代码清单中的YAML文件创建一个特权模式的pod。
#代码13.8 一个带有特权容器的pod:pod-privileged.yaml apiVersion: v1 kind: Pod metadata: name: pod-privileged spec: containers: - name: main image: alpine command: ["/bin/sleep", "999999"] securityContext: privileged: true #这个容器将在特权模式下运行
部署这个pod,然后与之前部署的非特权模式的pod做对比。
熟悉Linux的会知道Linux中有一个叫作/dev的特殊目录,该目录包含系统中所有设备对应的设备文件。这些文件不是磁盘上的常规文件,而是用于与设备通信的特殊文件。通过列出/dev目录下文件的方式查看先前部署的非特权模式容器(名为Pod-with-defaults的pod)中的设备,如以下代码清单所示。
#代码13.9 非特权pod可用设备列表 $ kubectl exec -it pod-with-defaults ls /dev core null stderr urandom fd ptmx stdin zero full pts stdout fuse random termination-log mqueue shm tty
这个相当短的列表己经列出了全部的设备,将这个列表与下面的列表比较。下面的列表列出了在特权pod中能看到的特权设备。
#代码13.10 特权pod可用的设备列表 $ kubectl exec -it pod-privileged ls /dev autofs snd tty46 bsg sr0 tty47 btrfs-control stderr tty48 core stdin tty49 cpu stdout tty5 cpu_dma_latency termination-log tty50 fd tty tty51 full tty0 tty52 fuse tty1 tty53 hpet tty10 tty54 hwrng tty11 tty55 ... ... ...
由于完整的设备列表过长,以上没有完整列出所有的设备,但这己经足以证明这个设备列表远远长于之前的列表。事实上,特权模式的pod可以看到宿主节点上的所有设备。这意味着它可以自由使用任何设备。
举个例子,如果要在树莓派上运行一个pod,用这个pod来控制相连的LED, 那么必须使用特权模式运行这个pod。
2.4 为容器单独添加内核功能
上一节中己经介绍了一种给予容器无限力量的方法。过去,传统的UNIX实现只区分特权和非特权进程,但是经过多年的发展,Linux己经可以通过内核功能支持更细粒度的权限系统。
相比于让容器运行在特权模式下以给予其无限的权限,一个更加安全的做法是只给予它使用真正需要的内核功能的权限。Kubernetes允许为特定的容器添加内核功能,或禁用部分内核功能,以允许对容器进行更加精细的权限控制,限制攻击者潜在侵入的影响。
例如,一个容器通常不允许修改系统时间(硬件时钟的时间)。可以通过在pod-with-defaults pod中修改设定时间来验证:
$ kubectl exec -it pod-with-defaults -- date +%T -s "12:00:00" date:can't set date: Operation not permitted
如果需要允许容器修改系统时间,可以在容器capbilities里add—项名为CAP_SYS_TIME的功能,如以下代码清单所示。
#代码13.11 添加CAP_SYS_TIME功能:pod-add-settime-capability. yaml apiVersion: v1 kind: Pod metadata: name: pod-add-settime-capability spec: containers: - name: main image: alpine command: ["/bin/sleep", "999999"] securityContext: #在securityContext中添加或者禁用内核功能 capabilities: add: #在这里添加了SYS_TIME功能 - SYS_TIME
注意:Linux内核功能的名称通常以CAP_开头。但在pod spec中指定内核功能时,必须省略CAP_前缀。
在新的容器中运行同样的命令,可以成功修改系统时间:
$ kubectl exec -it pod-add-settime-capability -- date +%T -s "12:00:00" 12:00:00 $ kubectl exec -it pod-add-settime-capability -- date Sun May 7 12:00:03 UTC 2017
警告:自行尝试时,请注意这样可能导致节点不可用。在Minikube中,尽管系统时间成功被网络时间协议(Network Time Protocol,NTP)重置,仍然不得不重启节点以调度新的pod。
添加内核功能远比通过设置privileged:true更好,诚然这样需要使用者了解各种内核功能。
2.5 在容器中禁用内核功能
己经了解到如何给容器添加内核功能,另一方面你也可以禁用容器中的内核功能。例如,默认情况下容器拥有CAP_CHOWN权限,允许进程修改文件系统中文件的所有者。
在以下示例中可以看到,可以在pod-with-defaults中将/tmp目录的所有者改为guest用户:
$ kubectl exec pod-with-defaults chown guest /tmp $ kubectl exec pod-with-defaults -- ls -la / | grep tmp drwxrwxrwt 2 guest root 6 May 25 15:18 tmp
为了阻止容器的此种行为,需要如以下代码清单所示,在容器的securityContext.capabilities.drop列表中加入此项,以禁用这个修改文件所有者的内核功能。
#代码 13.12禁用容器中的内核功能:pod-drop-chown-capability.yaml apiVersion: v1 kind: Pod metadata: name: pod-drop-chown-capability spec: containers: - name: main image: alpine command: ["/bin/sleep", "999999"] securityContext: capabilities: drop: #在这里禁用了容器修改文件所有者 - CHOWN
禁用CHOWN内核功能后,不允许在这个pod中修改文件所有者:
$ kubectl exec pod-drop-chown-capability chown guest /tmp chown: /tmp: Operation not permitted
这里已经对容器安全上下文的大部分选项研究完毕。下面再介绍一个选项。
2.6 阻止对容器根文件系统的写入
因为安全原因,可能需要阻止容器中的进程对容器的根文件系统进行写入,仅允许它们写入挂载的存储卷。
假如在运行一个有隐藏漏洞,可以允许攻击者写入文件系统的PHP应用。这些PHP文件在构建时放入容器的镜像中,并且在容器的根文件系统中提供服务。由于漏洞的存在,攻击者可以修改这些文件,在其中注入恶意代码。
这一类攻击可以通过阻止容器写入自己的根文件系统(应用的可执行代码的通常储存位置)来防止。可以如以下代码所示,将容器的securityContext.readOnlyRootFilesystem设置为true来实现。
#代码13.13 根文件系统只读的容器:pod-with-readonly-filesystem.yaml apiVersion: v1 kind: Pod metadata: name: pod-with-readonly-filesystem spec: containers: - name: main image: alpine command: ["/bin/sleep", "999999"] securityContext: #这个容器的根文件系统不予许写入 readOnlyRootFilesystem: true volumeMounts: #但是向/volume写入是予许的,因为这个目录挂载了一个存储卷 - name: my-volume mountPath: /volume readOnly: false volumes: - name: my-volume emptyDir:
这个pod中的容器虽然以root用户运行,拥有/目录的写权限,但在该目录下写入一个文件会失败:
$ kubectl exec -it pod-with-readonly-filesystem touch /new-file touch:/new-file: Read-only file system
另一方面,对挂载的卷的写入是允许的:
$ kubectl exec -it pod-with-readonly-filesystem touch /volume/newfile $ kubectl exec -it pod-with-readonly-filesystem -- ls -la /volume/newfile -rw-r--r-- 1 root root 0 May 7 19:11 /mountedVolume/newfile
如以上例子所示,如果容器的根文件系统是只读的,很可能需要为应用会写入的每一个目录(如日志、磁盘缓存等)挂载存储卷。
提示:为了增强安全性,请将在生产环境运行的容器的readOnlyRootFilesystem选项设置为true。
设置pod级别的安全上下文
以上的例子都是对单独的容器设置安全上下文。这些选项中的一部分也可以从pod级别设定(通过pod.spec.securityContext属性)。它们会作为pod中每一个容器的默认安全上下文,但是会被容器级别的安全上下文覆盖。下面将会介绍pod级别安全上下文独有的内容.
2.7 容器使用不同用户运行时共享存储卷
存储卷在pod的不同容器中共享数据。可以顺利地在一个容器中写入数据,在另一个容器中读出这些数据。
但这只是因为两个容器都以root用户运行,对存储卷中的所有文件拥有全部权限。现在假设使用前面介绍的runAsUser选项。可能需要在一个pod中用两个不同的用户运行两个容器(可能是两个第三方的容器,都以它们自己的特定用户运行进程)。如果这样的两个容器通过存储卷共享文件,它们不一定能够读取或写入另一个容器的文件。
因此,Kubernetes允许为pod中所有容器指定supplemental组,以允许它们无论以哪个用户ID运行都可以共享文件。这可以通过以下两个属性设置:
-
- fsGroup
- supplementalGroups
下面来看一下如何在pod中使用它们,以及它们效果。以下代码清单描述了一个拥有两个共享同一存储卷的容器的pod。
#代码 13.14 fsGroup和supplementalGroups: pod-with-shared-volume-fsgroup.yaml apiVersion: v1 kind: Pod metadata: name: pod-with-shared-volume-fsgroup spec: securityContext: #fsGroup和supplementalGroups在pod级别的安全上下文中定义 fsGroup: 555 supplementalGroups: [666, 777] containers: - name: first image: alpine command: ["/bin/sleep", "999999"] securityContext: #第一个容器使用的用户ID为1111 runAsUser: 1111 volumeMounts: #两个容器使用同一个存储卷 - name: shared-volume mountPath: /volume readOnly: false - name: second image: alpine command: ["/bin/sleep", "999999"] securityContext: runAsUser: 2222 #第二个容器使用的用户ID为2222 volumeMounts: - name: shared-volume mountPath: /volume readOnly: false volumes: - name: shared-volume emptyDir:
创建这个pod之后,进入第一个容器查看它的用户ID和组ID:
$ kubectl exec -it pod-with-shared-volume-fsgroup -c first sh /$ id uid=1111 gid=0(root) groups=555,666,777
id命令显示,这个pod运行在ID为1111的用户下,它的用户组为0 (root),但用户组555、666、777也关联到了该用户下。
在pod的定义中,将fsGroup设置成了555,因此,存储卷属于用户组ID为555的用户组:
/$ls -l / | grep volume
drwxrwsrwx 2 root 555 6 May 29 12:23 volume
该容器在这个存储卷所在目录中创建的文件,所属的用户ID为1111(即该容器运行时使用的用户ID),所属的用户组ID为555:
/ $ echo foo > /volume/foo /$ls -l /volume total 4 -rw-r--r-- 1 1111 555 4 May 29 12:25 foo
这个文件的所属用户情况与通常设置下的新建文件不同。在通常情况下,某一用户新创建文件所属的用户组ID,与该用户的所属用户组ID相同,在这种情下是0。在这个容器的根文件系统中创建一个文件,可以验证这一点:
/ $ echo foo > /tmp/foo /$ls -l /tmp
total 4
-rw-r--r-- 1 1111 root 4 May 29 12:41 foo
如你所见,安全上下文中的fsGroup属性当进程在存储卷中创建文件时起作用,而supplementalGroups属性定义了某个用户所关联的额外的用户组。
3.限制pod使用安全相关的特性—PodSecurityPolicy
上面的例子都是在任一宿主节点做任何想做的事。比如,部署一个特权模式的pod,可以在任一宿主节点上做任何想做的事。但是需要有一种机制阻止用户使用其中部分功能。集群管理人员可以通过创建PodSecurityPolicy资源来限制对以上提到的安全相关的特性的使用。
3.1 PodSecurityPolicy资源介绍
PodSecurityPolicy是一种集群级别(无命名空间)的资源,它定义了用户能否在pod中使用各种安全相关的特性。维护PodSecurityPolicy资源中配置策略的工作由集成在API服务器中的PodSecurityPolicy准入控制插件完成。
注意:集群中不一定启用了PodSecurityPolicy准入控制插件。这个请确保已启动
当有人向API服务器发送pod资源时,PodSecurityPolicy准入控制插件会将这个pod与己经配置的PodSecurityPolicy进行校验。如果这个pod符合集群中己有安全策略,它会被接收并存入etcd;否则它会立即被拒绝。这个插件也会根据安全策略中配置的默认值对pod进行修改。
在Minikube中启用RBAC和PodSecurityPolicy准入控制
这里使用Minkubev0.19.0来运行以下样例。这个版本没有启用RBAC和PodSecurityPolicy准入控制插件,这些在以下的部分练习中是必需的。其中一个练习需要以不同用户认证,因此还需要开启basic authenticate插件,其中用户的信息在一个文件中定义。
为了在Minikube中启用这些插件,需要运行如下命令(或类似的命令,这取决于使用的版本):
$ minikube start --extra-config apiserver.Authentication.PasswordFile. ➥ BasicAuthFile=/etc/kubernetes/passwd --extra-config=apiserver. ➥ Authorization.Mode=RBAC --extra-config=apiserver.GenericServerRun ➥ Options.AdmissionControl=NamespaceLifecycle,LimitRanger,Service ➥ Account,PersistentVolumeLabel,DefaultStorageClass,ResourceQuota, ➥ DefaultTolerationSeconds,PodSecurityPolicy
这个API服务器需要创建在以上命令中制定的口令文件才能开始运行。以下命令可以创建这个文件:
cat <<EOF | minikube ssh sudo tee /etc/kubernetes/passwd password,alice,1000,basic-user password,bob,2000,privileged-user EOF
了解PodSecurityPolicy可以做的事
一个PodSecurityPolicy资源可以定义以下事项:
-
- 是否允许pod使用宿主节点的PID、IPC、网络命名空间
- pod允许绑定的宿主节点端口
- 容器运行时允许使用的用户ID
- 是否允许拥有特权模式容器的pod
- 允许添加哪些内核功能,默认添加哪些内核功能,总是禁用哪些内核功能
- 允许容器使用哪些SELinux选项
- 容器是否允许使用可写的根文件系统
- 允许容器在哪些文件系统组下运行
- 允许pod使用哪些类型的存储卷
检视一个PodSecurityPolicy样例
以下代码清单展示了一个PodSecurityPolicy的样例。它阻止了pod使用宿主节点的PID、IPC、网络命名空间,运行特权模式的容器,以及绑定大多数宿主节点的端口(除10000-11000和13000-14000范围内的端口)。它没有限制容器运行时使用的用户、用户组和SELinux选项。
#代码13.15 一个 PodSecurityPolicy 的样例:pod-security-policy.yaml apiVersion: extensions/v1beta1 kind: PodSecurityPolicy metadata: name: default spec: hostIPC: false #容器不予许使用宿主节点的IPC,PID和网络命名空间 hostPID: false hostNetwork: false hostPorts: #容器只能绑定宿主节点的10000-11000端口(含端点)或13000-14000端口 - min: 10000 max: 11000 - min: 13000 max: 14000 privileged: false #容器不能在特权模式下运行 readOnlyRootFilesystem: true #容器强制使用只读根文件系统 runAsUser: #容器可以以任意用户和用户组运行 rule: RunAsAny fsGroup: rule: RunAsAny supplementalGroups: rule: RunAsAny seLinux: #它们也可以使用任何Selinux的选项 rule: RunAsAny volumes: #pod可以使用所有类型的存储卷 - '*'
以上样例的大部分选项是不言自明的,这个PodSecurityPolicy在集群中创建成功之后,API服务器将不再允许之前样例中的特权pod。
$ kubectl create -f pod-privileged.yaml Error from server (Forbidden): error when creating "pod-privileged.yaml" pods "pod-privileged" is forbidden: unable to validate against any pod security policy: [spec.containers[0].securityContext.privileged:Invalid value: true: Privileged containers are not allowed]
类似地,集群中不能再部署使用宿主节点的PID、IPC、网络命名空间的pod了。 同样,因为以上策略中的readOnlyRootFilesystem选项己设置为true,容器的根文件系统将变为只读(容器只能写入挂载的存储卷)。
3.2 了解 runAsUser、fsGroup 和 supplementalGroup 策略
前面的例子中的策略没有对容器运行时可以使用的用户和用户组施加任何限制,因为它们在runAsUser、fsGroup、supplementalGroups等字段中使用了runAsAny规则。如果需要限制容器可以使用的用户和用户组ID,可以将规则改为MustRunAs,并指定允许使用的ID范围。
使用MustRunAs规则
来看以下的例子。为了只允许容器以用户ID 2的身份运行并限制默认的文件系统组和增补组ID在2-10或20-30的范围(包含临界值)内,需要在PodSecurityPolicy资源中加入如以下代码清单所示片段。
#代码 13.16指定容器运行时必须使用的用户和用户组ID : psp-must-run-as.yaml apiVersion: extensions/v1beta1 kind: PodSecurityPolicy metadata: name: default spec: hostIPC: false hostPID: false hostNetwork: false hostPorts: - min: 10000 max: 11000 - min: 13000 max: 14000 privileged: false readOnlyRootFilesystem: true runAsUser: rule: MustRunAs ranges: #添加一个max=min的range来制定一个特定的ID - min: 2 max: 2 fsGroup: # 支持指定多个区间---这里,组ID可以在2-10(含端点)或20-30之间 rule: MustRunAs ranges: - min: 2 max: 10 - min: 20 max: 30 supplementalGroups: rule: MustRunAs ranges: - min: 2 max: 10 - min: 20 max: 30 seLinux: rule: RunAsAny volumes: - '*'
如果pod spec试图将其中的任一字段设置为该范围之外的值,这个pod将不会被API服务器接收。可以通过删除之前PodSecurityContextPolicy,并通过psp-must-run-as.yaml文件创建一个新的来实践这一点。
注意:修改策略对已经存在的pod无效,因为PodSecurityPolicy资源仅在创建和升级pod时起作用。
部署runAsUser在指定范围之外的pod
如果尝试使用之前的pod-as-user-guest.yaml文件部署一个pod,其中指定了容器运行的用户ID为405,API服务器会拒绝这个pod:
$ kubectl create -f pod-as-user-guest.yaml Error from server (Forbidden): error when creating "pod-as-user-guest.yaml" :pods "pod-as-user-guest" is forbidden: unable to validate against any pod security policy: [securityContext.runAsUser:Invalid value: 405: UID on container main does not match required range. Found 405, allowed: [{2 2}]]
好,这个是显然的。但是如果部署pod时没有指定runAsUser属性,但用户ID被注入到镜像的情况下(在Dockerfile中使用USER命令),会发生什么?
部署镜像中用户ID在指定范围之外的pod
现在创建一个不同版本的Node.js镜像,这个镜像被配置为使用用户ID为5的用户运行。该镜像使用的Dockerfile如以下代码清单所示。
#代码13.17 包含USER指令的Dockerfile FROM node:7 ADD app.js /app.js USER 5 ENTRYPOINT ["node", "app.js"] #app.js const http = require('http'); const os = require('os'); console.log("Kubia server starting..."); var handler = function(request, response) { console.log("Received request from " + request.connection.remoteAddress); response.writeHead(200); response.end("You've hit " + os.hostname() + " "); }; var www = http.createServer(handler); www.listen(8080);
镜像命名为uksa/kubia-run-as-user-5,dockerHub可以找到。 如果使用这个镜像创建pod,API服务器不会拒绝:
$ kubectl run run-as-5 --image luksa/kubia-run-as-user-5 --restart Never pod "run-as-5" created
与之前不同,API服务器接收了这个pod,kubelet也运行了这个容器。接下来查看这个容器使用的用户ID和用户组ID:
$ kubectl exec run-as-5 -- id uid=2(bin) gid=2(bin) groups=2(bin)
可以看到,这个容器运行时使用的用户ID为2,就是在PodSecurityPolicy中指定的ID。PodSecurityPolicy可以将硬编码覆盖到镜像中的用户ID。
在runAsUser字段中使用mustRunAsNonRoot规则
runAsUser字段中还可以使用另一种规则:mustRunAsNonRoot。正如其名,它将阻止用户部署以root用户运行的容器。在此种情况下,spec容器中必须指定runAsUser字段,并且不能为0(0为root用户的ID),或者容器的镜像本身指定了用一个非0的用户ID运行。这种做法的好处己经在之前介绍过。
3.3 配置允许、默认添加、禁止使用的内核功能
容器可以运行在特权模式下,也可以通过对每个容器添加或禁用Linux内核功能来定义更细粒度的权限配置。以下三个字段会影响容器可以使用的内核功能:
-
- allowedCapabilities
- defaultAddCapabilities
- requiredDropCapabilities
下面看一个例子,然后讨论这三个字段各自的行为。以下代码清单展示了一个定义了这三个字段的PodSecurityPolicy资源。
#代码13.18 在PodSecurityPolicy资源中指定内核功能:psp-capabilities.yaml apiVersion: extensions/v1beta1 kind: PodSecurityPolicy metadata: name: default spec: allowedCapabilities: #予许容器添加SYS_TIME功能 - SYS_TIME defaultAddCapabilities: #为每个容器自动添加CHOWN功能 - CHOWN requiredDropCapabilities: #要求容器禁用SYS_ADMIN功能和SYS_MODULE功能 - SYS_ADMIN - SYS_MODULE .......
注意:SYS_ADMIN功能允许使用一系列的管理操作;SYS_MODULE功能允许加载或卸载Linux内核模块。
指定容器中可以添加的内核功能
allowedCapabilities字段用于指定spec容器的securityContext.capabilities中可以添加哪些内核功能。之前的一个例子中,容器内添加了SYS_TIME内核功能。如果启用了PodSecurityPolicy访问控制插件,pod中不能添加以上内核功能,除非在PodSecurityPolicy中指明允许添加,如代码清单13.18所示。
为所有容器添加内核功能
defaultAddCapabilities字段中列出的所有内核功能将被添加到每个已部署的pod的每个容器中。如果用户不希望某个容器拥有这些功能,必须在容器的spec中显式地禁用它们。
代码清单13.18中的例子自动在每个容器中添加CAP_CH0WN功能,因此容器中的进程允许修改容器中文件的所有者(例如,使用chown命令)。
禁用容器中的内核功能
这个例子中的最后一个字段是requiredDropCapabilities。这个名字有点奇怪,但它并没有那么复杂。在这个字段中列出的内核功能会在所有容器中被禁用(PodSecurityPolicy访问控制插件会在所有容器的securityContext.capabilities.drop字段中加入这些功能)。
如果用户试图在创建的pod中显式加入requiredDropCapabilities字段中的内核功能,这个pod会被拒绝:
$ kubectl create -f pod-add-sysadmin-capability.yaml Error from server (Forbidden): error when creating "pod-add-sysadmin-capability .yaml " : pods "pod-add-sysadmin-capability" is forbidden: unable to validate against any pod security policy: [capabilities.add: Invalid value: "SYS_ADMIN": capability may not be added]
3.4 限制pod可以使用的存储卷类型
最后一项PodSecurityPolicy资源可以做到的是定义用户可以在pod中使用哪些类型的存储卷。在最低限度上,一个PodSecurityPolicy需要允许pod使用以下类型的存储卷:empty Dir、configMap、secret、downwardAPI、persistentVolumeClaim。PodSecurityPolicy资源中的相关部分如以下代码清单所示。
#代码13.19 仅允许特定类型存储卷的PodSecurityPolicy片段:psp-volumes.yaml apiVersion: extensions/v1beta1 kind: PodSecurityPolicy metadata: name: default spec: volumes: - emptyDir - configMap - secret - downwardAPI - persistentVolumeClaim
如果有多个PodSecurityPolicy资源,pod可以使用PodSecurityPolicy中允许使用的任何一个存储卷类型(实际生效的是所有volume列表的并集)。
3.5 对不同的用户与组分配不同的PodSecurityPolicy
已经提到过PodSecurityPolicy是集群级别的资源,这意味着它不能存储和应用在某一特定的命名空间上。这是否意味着它总是会应用在所有的命名空间上呢?不是的,因为这样会使得它们相当难以应用。毕竟,系统pod经常需要允许做一些常规pod不应当做的事情。
对不同用户分配不同PodSecurityPolicy是通过RBAC机制实现的。这个方法是,创建需要的PodSecurityPolicy资源,然后创建ClusterRole资源并通过名称将它们指向不同的策略,以此使PodSecurityPolicy资源中的策略对不同的用户或组生效。通过ClusterRoleBinding资源将特定的用户或组绑定到ClusterRole上,当PodSecurityPolicy访问控制插件需要决定是否接纳一个pod时,它只会考虑创建pod的用户可以访问到的PodSecurityPolicy中的策略。
可以在下面的练习中看到如何做到这些。首先,创建另一个PodSecurityPolicy。
创建一个允许部署特权容器的PodSecurityPolicy
首先,要创建一个特殊的PodSecurityPolicy,允许用户创建拥有特权容器的pod。以下代码清单展示了该PodSecurityPolicy的定义。
#代码13.20 特权用户使用的 PodSecurityPolicy: psp-privileged.yaml apiVersion: extensions/v1beta1 kind: PodSecurityPolicy metadata: name: privileged spec: privileged: true #予许创建特权容器 runAsUser: rule: RunAsAny fsGroup: rule: RunAsAny supplementalGroups: rule: RunAsAny seLinux: rule: RunAsAny volumes: - '*'
在向API服务器post这个PodSecurityPolicy之后,集群中有两个策略:
S kubectl get psp
NAME PRIV CAPS SELINUX RUNASUSER FSGROUP
default false [] RunAsAny RunAsAny RunAsAny
privileged true [] RunAsAny RunAsAny RunAsAny
正如PRIV列中所示,default策略禁止运行特权容器,然而privileged策略是允许的。因为现在是以cluster-admin身份登录的,所以可以看到所有的策略。部署pod时,如果任一策略允许使用pod中使用到的特性,API服务器就会接收这个pod。
现在考虑另外两个使用该集群的用户:Alice和Bob。希望Alice只能部署受限制的(非特权)pod,允许Bob部署特权pod。可以通过让Alice只能使用default PodSecurityPolicy,而Bob可以使用以上两个PodSecurityPolicy来做到。
使用RBAC将不同的PodSecurityPolicy分配给不同用户
RBAC机制可以给用户授予特定类型的资源的访问权限,但RBAC机制也可以通过使用引用其名字来授予对特定资源实例的访问权限。这就是为了让不同用户使用不同PodSecurityPolicy的方法。
首先需要创建两个ClusterRole,分别允许使用其中一个策略。将第一个ClusterRole命名为psp-default并允许其使用default PodSecurityPolicy资源。可以使用 kubectl create clusterrole来操作:
$ kubectl create clusterrole psp-default --verb=use --resource=podsecuritypolicies --resource-name=default clusterrole "psp-default" created
注意:使用的动词是use,而非get、list、watch或类似的动词。
通过--resource-name选项引用了一个PodSecurityPolicy资源的特定实例。现在,创建另一个名为psp-privileged ClusterRole,指向privileged策略:
$ kubectl create clusterrole psp-privileged --verb=use --resource=podsecuritypolicies --resource-name=privileged clusterrole "psp-privileged" created
现在,需要把这两个策略绑定到用户上。绑定一个ClusterRole资源以授予对集群级别资源(PodSecurityPolicy资源就是集群级别的资源)的访问权限,需要使用ClusterRoleBinding资源而非(有命名空间的)RoleBinding。
要将psp-default ClusterRole绑定到所有己认证用户上,而非只有Alice。这是必需的,否则没有用户可以创建pod,因为PodSecurityPolicy访问控制插件会因为没有找到任何策略而拒绝创建pod。所有己认证用户都属于system: authenticated组,因此需要将该ClusterRole绑定到这个组:
$ kubectl create clusterrolebinding psp-all-users --clusterrole=psp-default --group=system:authenticated clusterrolebinding "psp-all-users" created
接着,需要将psp-privileged ClusterRole绑定到用户Bob:
$ kubectl create clusterrolebinding psp-bob --clusterrole=psp-privileged --user=bob clusterrolebinding "psp-bob" created
作为一个己认证用户,Alice现在拥有使用default PodSecurityPolicy的权限, 然而Bob拥有使用default和privileged PodSecurityPolicy的权限。Alice不能创建特权pod,而Bob可以。接下来看看是否确实如此。
为kubectl创建不同用户
如何以Alice或Bob的身份通过认证,而非现在己经认证的用户?这里不做详细解释这里只展示允许以Alice或Bob的身份使用kubectl的命令。
首先,需要使用如下命令,用kubectl的config子命令创建两个新用户:
$ kubectl config set-credentials alice --username=alice --password=password User "alice" set. $ kubectl config set-credentials bob --username=bob --password=password User "bob" set.
这些命令的行为应当很明显。因为使用了用户名和密码作为凭据,kubectl将对这两个用户使用基础HTTP认证进行认证(其他的认证方法包括token、客户端证书等)。
使用不同用户创建pod
现在,可以尝试以Alice的身份认证,并创建一个特权pod。可以通过--user选项向kubectl传达使用的用户凭据:
$ kubectl --user alice create -f pod-privileged.yaml Error from server (Forbidden): error when creating "pod-privileged.yaml": pods "pod-privileged" is forbidden: unable to validate against any pod security policy: [spec.containers[0].securityContext.privileged: Invalid value: true: Privileged containers are not allowed]
与预期相同,API服务器不允许Alice创建特权pod。现在看一下Bob是否允许:
$ kubectl --user bob create -f pod-privileged.yaml pod "pod-privileged" created
现在成功地使用了RBAC,让访问控制插件对不同用户使用不同的PodSecurityPolicy资源。
4.小结
1.PodSecurityPolicy资源可以通过RBAC中的ClusterRole和ClusterRoleBinding与特定用户关联。
2.集群级别的PodSecurity Policy资源可以用来防止用户创建可能危及宿主节点的pod