用命令检查集群复制状态:masterha_check_repl --conf=/etc/masterha/app1.cnf
报错如下:
Tue Jan 12 09:25:51 2016 - [info] Checking replication health on 192.168.200.27..
Tue Jan 12 09:25:51 2016 - [error][/usr/local/share/perl5/MHA/Server.pm, ln499] Slave is currently behind 326281 seconds on 192.168.200.27(192.168.200.27:3306)
Tue Jan 12 09:25:51 2016 - [error][/usr/local/share/perl5/MHA/ServerManager.pm, ln1526] failed!
Tue Jan 12 09:25:51 2016 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm, ln424] Error happened on checking configurations. at /usr/local/share/perl5/MHA/MasterMonitor.pm line 417
Tue Jan 12 09:25:51 2016 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm, ln523] Error happened on monitoring servers.
Tue Jan 12 09:25:51 2016 - [info] Got exit code 1 (Not master dead).
MySQL Replication Health is NOT OK!
注:192.168.200.27为第一slave节点
检查192.168.200.27的复制状态,192.168.200.26第二slave也是一样的情况,复制停在同一pos
运行show slave statusG,结果如下
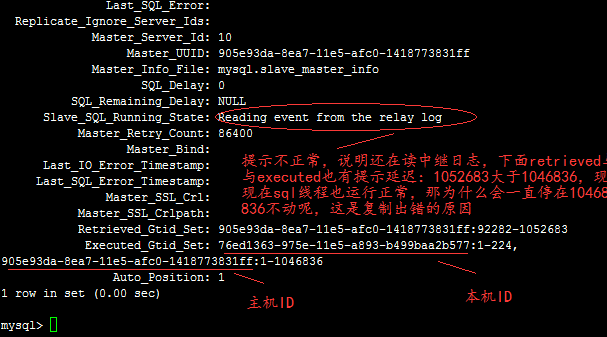
从机运行正常的情况下,Slave_SQL_Running_State: 应该提示“Slave has read all relay log; waiting for the slave I/O thread to update it”
并且从机复制落后的情况下,用pt检查一致性都不行,如下:
[root@boshiwan-hhjj-db-slave1 ~]# pt-table-checksum --nocheck-replication-filters --no-check-binlog-format --replicate=test.checksums --databases=ipdb h=192.168.200.28,u=checksum,p=checksum,P=3306
Replica lag is 329101 seconds on boshiwan-hhjj-db-slave1. Waiting.
Replica lag is 329131 seconds on boshiwan-hhjj-db-slave1. Waiting.
所以要找到两台从机的sql线程为什么会卡住的原因
经过排查,找到故障原因:由于主库上5天前进行过从sqlserver 2000的导入,使用的是sqlserver的工具,其中一个大表XOXPRODUCT的数据有70W+条,中间又建立过临时表XOXPRODUCT,估计这个表存储过200W+的记录,导致slave一直在执行一个大事务,而又是单线程处理,所以就一直卡在这,什么时候结束这个事务也不知道
处理:由于也不知道什么时候能执行完这个事务,现在离主库也差不多有34w秒,也就是差不多4天了,所以计划重新搭建集群。
排查过程:
1.通过show engine innodb statusG的显示来查看msyql运行过程中的细节,由于信息量太大,直接列出会看不到开头的信息,而开头的信息又非常重要,所以要如下操作:
a. set global innodb_status_output_locks=on;
b. pager less
c. show engine innodb statusG
在第一页的输出中就看到了关键信息,如下图

2.并且这个线程打满了cpu的1个核,查看命令:top 进入后按数字1
