概念
事务就是一组原子性的SQL查询,或者说一个独立的工作单元。如果数据库引擎能够成功地对数据库应用该组查询的全部语句,那么就执行该组查询。如果其中有任何一条语句因为崩溃或其他原因无法执行,那么所有的语句都不会执行。也就是说,事务内的语句,要么全部执行成功,要么全部执行失败。
举个例子:
银行应用是解释事务必要性的一个经典例子。假设一个银行的数据库有两张表:支票(checking)表和储蓄(savings)表。现在要从用户Jane的支票账户转移200美元到她的储蓄账户,那么需要至少三个步骤:
- 检查支票账户的余额高于200美元。
- 从支票账户余额中减去200美元。
- 在储蓄账户余额中增加200美元。
上述三个步骤的操作必须打包在一个事务中,任何一个步骤失败,则必须回滚所有的步骤。
可以用START TRANSACTION或SET AUTOCOMMIT=0语句开始一个事务,然后要么使用COMMIT提交事务将修改的数据持久保留,要么使用ROLLBACK撤销所有的修改。
事务的ACID
ACID表示原子性(atomicity)、一致性(consistency)、隔离性(isolation)和持久性(durability)。
1、原子性(atomicity)
一个事务必须被视为一个不可分割的最小工作单元,整个事务中的所有操作要么全部提交成功,要么全部失败回滚,对于一个事务来说,不可能只执行其中的一部分操作,这就是事务的原子性。
2、一致性(consistency)
数据库总是从一个一致性的状态转换到另外一个一致性的状态。
3、隔离性(isolation)
通常来说,一个事务所做的修改在最终提交以前,对其他事务是不可见的。
4、持久性(durability)
一旦事务提交,则其所做的修改就会永久保存到数据库中。此时即使系统崩溃,修改的数据也不会丢失。
事务并发引起的问题
- 脏读(dirty read) 一个事务读取了另一个事务尚未提交的数据。事务A、B并发执行时,当A事务update后,B事务select读取到A尚未提交的数据,此时A事务rollback,则B读到的数据是无效的"脏"数据。
- 不可重复读(non-repeatable read) 一个事务的操作导致另一个事务前后两次读取到不同的数据。事务A、B并发执行时,当B事务select读取数据后,A事务update操作更改B事务select到的数据,此时B事务再次读去该数据,发现前后两次的数据不一样。
- 幻读(phantom read) 一个事务的操作导致另一个事务前后两次查询的结果数据量不同。事务A、B并发执行时,当B事务select读取数据后,A事务insert或delete了一条满足A事务的select条件的记录,此时B事务再次select,发现查询到前次不存在的记录("幻影"),或者前次的某个记录不见了。
隔离级别
可以通过设置相应的事务隔离级别解决并发问题。
在SQL标准中定义了四种隔离级别,每一种级别都规定了一个事务中所做的修改,哪些在事务内和事务间是可见的或是不可见的。较低级别的隔离通常可以执行更高的并发,系统的开销也更低。
1、READ UNCOMMITTED(读未提交)
在READ UNCOMMITTED级别,事务中的修改,即使没有提交,对其他事务也都是可见的。事务可以读取未提交的数据,这也被称为脏读(Dirty Read)。这个级别会导致很多问题,从性能上来说,READ UNCOMMITTED不会比其他的级别好太多,但却缺乏其他级别的很多好处,除非真的有非常必要的理由,在实际应用中一般很少使用。
2、READ COMMITTED(读已提交)
大多数数据库系统的默认隔离级别都是READ COMMITTED(但MySQL不是)。READ COMMITTED满足前面提到的隔离性的简单定义:一个事务开始时,只能“看见”已经提交的事务所做的修改。换句话说,一个事务从开始直到提交之前,所做的任何修改对其他事务都是不可见的。这个级别会出现不可重复读(nonrepeatable read)问题,因为当事务1两次执行同样的查询,在事务1的两次查询中间有事务2执行了修改并提交,则事务1就会得到不一样的结果。
3、REPEATABLE READ(可重复读)
REPEATABLE READ解决了脏读的问题。该级别保证了在同一个事务中多次读取同样记录的结果是一致的。但是理论上,可重复读隔离级别还是无法解决另外一个幻读(Phantom Read)的问题。所谓幻读,指的是当某个事务在读取某个范围内的记录时,另外一个事务又在该范围内插入了新的记录,当之前的事务再次读取该范围的记录时,会产生幻行(Phantom Row)。InnoDB和XtraDB存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control)解决了幻读的问题。
4、SERIALIZABLE(可串行化)
SERIALIZABLE是最高的隔离级别。它通过强制事务串行执行,避免了前面说的幻读的问题。简单来说,SERIALIZABLE会在读取的每一行数据上都加锁,所以可能导致大量的超时和锁争用的问题。实际应用中也很少用到这个隔离级别,只有在非常需要确保数据的一致性而且可以接受没有并发的情况下,才考虑采用该级别。
注意:MySQL默认的隔离级别是可重复读。

死锁
死锁是指两个或者多个事务在同一资源上相互占用,并请求锁定对方占用的资源,从而导致恶性循环的现象。当多个事务试图以不同的顺序锁定资源时,就可能会产生死锁。多个事务同时锁定同一个资源时,也会产生死锁。
举个例子:
有两个事务:事务1和事务2,事务1先修改emp表的数据行1,再修改数据行2;事务2先修改emp表的数据行2,再修改数据行1。
在加行锁(行锁必须要有索引,用主键就行)的情况下,两个事务各自持有一个锁,又去请求对方的锁就会产生死锁,,则陷入死循环。除非有外部因素介入才可能解除死锁。
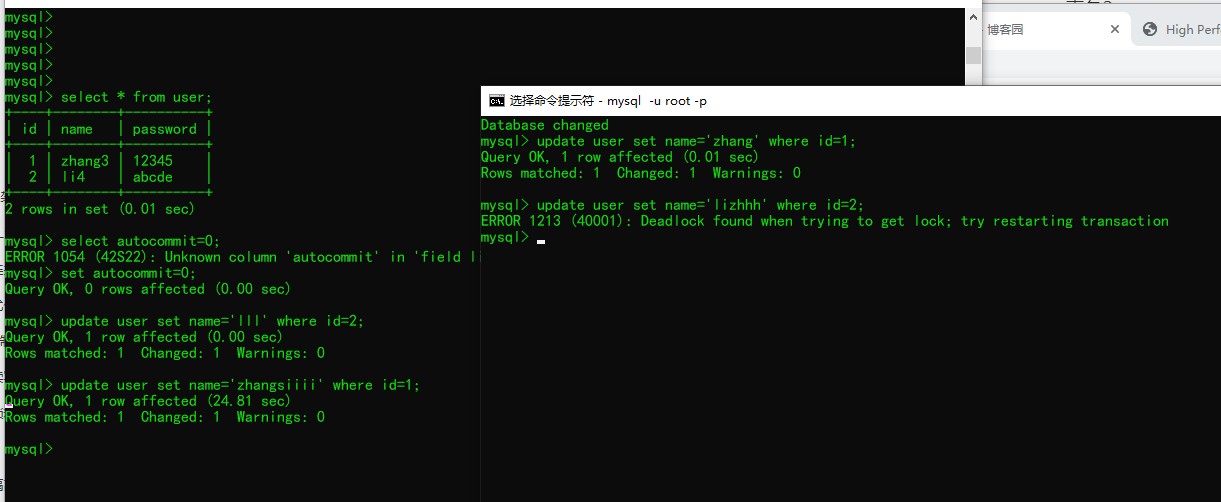
出现了死锁,MySQL自动重启了事务2(左边是事务1,右边是事务2,下面是事务2)
InnoDB目前处理死锁的方法是,将持有最少行级排他锁的事务进行回滚(这是相对比较简单的死锁回滚算法)。
死锁发生以后,只有部分或者完全回滚其中一个事务,才能打破死锁。大多数情况下只需要重新执行因死锁回滚的事务即可。
事务日志
- 事务日志可以帮助提高事务的效率。使用事务日志,存储引擎在修改表的数据时只需要修改其内存拷贝,再把该修改行为记录到硬盘上的事务日志中,不用每次都将修改的数据本身持久到磁盘。
- 事务日志采用的是追加的方式。事务日志持久以后,内存中被修改的数据在后台可以慢慢地刷回到磁盘。目前大多数存储引擎都是这样实现的,我们通常称之为预写式日志(Write-Ahead Logging),修改数据需要写两次磁盘。
- 如果数据的修改已经记录到事务日志并持久化,但数据本身还没有写回磁盘,此时系统崩溃,存储引擎在重启时能够自动恢复这部分修改的数据。具体的恢复方式则视存储引擎而定。
MySQL中的事务
提供事务的引擎
- MySQL提供了两种事务型的存储引擎:InnoDB和NDB Cluster。
- 一些第三方存储引擎也支持事务,比如:XtraDB和PBXT。
自动提交(AUTOCOMMIT)
MySQL默认采用自动提交(AUTOCOMMIT)模式。也就是说,如果不是显式地开始一个事务,则每个查询都被当作一个事务执行提交操作。
在当前连接中,可以通过设置AUTOCOMMIT变量来启用或者禁用自动提交模式:SET AUTOCOMMIT=0/1
当AUTOCOMMIT=0时,所有的查询都是在一个事务中,直到显式地执行COMMIT提交或者ROLLBACK回滚,该事务结束,同时又开始了另一个新事务。必须要显示的设置SET AUTOCOMMIT=1开启自动提交,后续的操作才不用手动提交或回滚。
show variables like '%autocommit%'; 命令查看当前的事务状态

在事务中混合使用存储引擎
修改AUTOCOMMIT对非事务型的表,比如MyISAM或者内存表,不会有任何影响。对这类表来说,没有COMMIT或者ROLLBACK的概念,也可以说是相当于一直处于AUTOCOMMIT启用的模式。
如果在事务中混合使用了事务型和非事务型的表(例如InnoDB和MyISAM表),在正常提交的情况下不会有什么问题。
但如果该事务需要回滚,非事务型的表上的变更就无法撤销,这会导致数据库处于不一致的状态,这种情况很难修复,事务的最终结果将无法确定。
隐式和显式锁定
InnoDB采用的是两阶段锁定协议(two-phase locking protocol)
隐式锁定:
在事务执行过程中,随时都可以执行锁定,锁只有在执行COMMIT或者ROLLBACK的时候才会释放,并且所有的锁是在同一时刻被释放。前面描述的锁定都是隐式锁定,InnoDB会根据隔离级别在需要的时候自动加锁。
显示锁定:
InnoDB也可以手动加锁:
- SELECT ... LOCK IN SHARE MODE
- SELECT ... FOR UPDATE
MySQL也支持LOCK TABLES和UNLOCK TABLES语句,这是在服务器层实现的,和存储引擎无关。如果应用需要用到事务,还是应该选择事务型存储引擎。
LOCK TABLES和事务之间相互影响的话,情况会变得非常复杂,在某些MySQL版本中甚至会产生无法预料的结果。
因此建议除了事务中禁用了AUTOCOMMIT,可以使用LOCK TABLES之外,其他任何时候都不要显式地执行LOCK TABLES,不管使用的是什么存储引擎。