什么是csv
逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)
读csv文件
1、首先导入CSV模板
2、创建一个CSV文件对象
3、打开文件进行读取
# coding:utf-8
import csv
f = csv.reader(open('1111.csv','r'))
for i in f:
print(i)
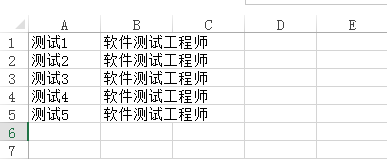
代码结果:
['测试1', '软件测试工程师']
['测试2', '软件测试工程师']
['测试3', '软件测试工程师']
['测试4', '软件测试工程师']
['测试5', '软件测试工程师']写入CSV文件
1、首先导入CSV模块
2、创建一个CSV文件对象
3、进行写入CSV文件
# coding:utf-8
import csv
data = [
("测试1",'软件测试工程师'),
("测试2",'软件测试工程师'),
("测试3",'软件测试工程师'),
("测试4",'软件测试工程师'),
("测试5",'软件测试工程师'),
]
f = open('222.csv','w')
writer = csv.writer(f)
for i in data:
writer.writerow(i)
f.close()写入后打开文件发现乱码了

解决方法:
1、导入codecs模块
2、使用cpdecs打开文件
# coding:utf-8
import csv
import codecs
data = [
("测试1",'软件测试工程师'),
("测试2",'软件测试工程师'),
("测试3",'软件测试工程师'),
("测试4",'软件测试工程师'),
("测试5",'软件测试工程师'),
]
f = codecs.open('222.csv','w','gbk')
writer = csv.writer(f)
for i in data:
writer.writerow(i)
f.close()这个时候发现不会乱码了
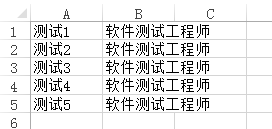
编码和解码
CSV文件其他用法
csv.DictReader()用法:
# 将CSV 数据读进列表中(首先查找是否使用给定字段名,如果没有,就是用第一行作为键)
# coding:utf-8
import csv
data = [
("测试1",'软件测试工程师1'),
("测试3",'软件测试工程师3'),
("测试4",'软件测试工程师4'),
("测试5",'软件测试工程师5'),
]
f1 = open('222.csv','r')
reader = csv.DictReader(f1)
for i in reader:
print(i)
f1.close()
代码结果:
[('测试1', '测试3'), ('软件测试工程师1', '软件测试工程师3')]
[('测试1', '测试4'), ('软件测试工程师1', '软件测试工程师4')]
[('测试1', '测试5'), ('软件测试工程师1', '软件测试工程师5')]csv.DictWriter()用法
# 直接字典字段写入到CSV文件中
# coding:utf-8
import csv
data = {'id':'123','name':'anjing','age':'26'}
with open('123.csv','w')as f:
fieldnames = {'id','name','age'} # 表头
writer = csv.DictWriter(f,fieldnames=fieldnames)
writer.writeheader()
writer.writerow(data)结果:

发现上面写入后中间多了一行,如何解决这一行呢?
加入参数“newline=‘’”
# coding:utf-8
import csv
data = {'id':'123','name':'anjing','age':'26'}
# 加入参数“enwline=''”
with open('123.csv','w',newline='')as f:
fieldnames = {'id','name','age'}
writer = csv.DictWriter(f,fieldnames=fieldnames)
writer.writeheader()
writer.writerow(data)
写读追加状态
'r':读
'w':写
'a':追加
'r+' == r+w(可读可写,文件若不存在就报错(IOError))
'w+' == w+r(可读可写,文件若不存在就创建)
'a+' ==a+r(可追加可写,文件若不存在就创建)
对应的,如果是二进制文件,就都加一个b就好啦:
'rb' 'wb' 'ab' 'rb+' 'wb+' 'ab+'
来源:https://www.cnblogs.com/qican/p/11122206.htmlhttps://www.cnblogs.com/qican/p/11122206.html