作者:Yx.Ac
出处:勇幸|Thinking (http://www.ahathinking.com)
昨天和今天学习了并查集和trie树,并练习了三道入门题目,理解更为深刻,觉得有必要总结一下,这其中的内容定义之类的是取自网络,操作的说明解释及程序的注释部分为个人理解。
并查集学习:
- 并查集:(union-find sets)
一种简单的用途广泛的集合. 并查集是若干个不相交集合,能够实现较快的合并和判断元素所在集合的操作,应用很多,如其求无向图的连通分量个数等。最完美的应用当属:实现Kruskar算法求最小生成树。
- 并查集的精髓(即它的三种操作,结合实现代码模板进行理解):
1、Make_Set(x) 把每一个元素初始化为一个集合
初始化后每一个元素的父亲节点是它本身,每一个元素的祖先节点也是它本身(也可以根据情况而变)。
2、Find_Set(x) 查找一个元素所在的集合
查找一个元素所在的集合,其精髓是找到这个元素所在集合的祖先!这个才是并查集判断和合并的最终依据。
判断两个元素是否属于同一集合,只要看他们所在集合的祖先是否相同即可。
合并两个集合,也是使一个集合的祖先成为另一个集合的祖先,具体见示意图
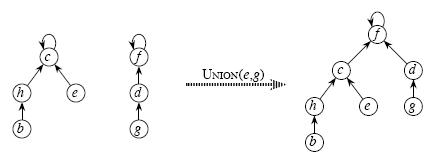
3、Union(x,y) 合并x,y所在的两个集合
合并两个不相交集合操作很简单:
利用Find_Set找到其中两个集合的祖先,将一个集合的祖先指向另一个集合的祖先。如图
- 并查集的优化
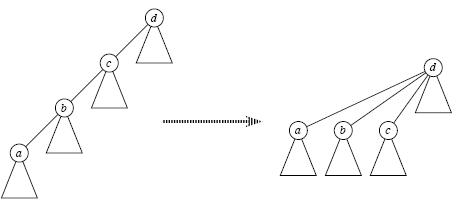
1、Find_Set(x)时 路径压缩
寻找祖先时我们一般采用递归查找,但是当元素很多亦或是整棵树变为一条链时,每次Find_Set(x)都是O(n)的复杂度,有没有办法减小这个复杂度呢?
答案是肯定的,这就是路径压缩,即当我们经过"递推"找到祖先节点后,"回溯"的时候顺便将它的子孙节点都直接指向祖先,这样以后再次Find_Set(x)时复杂度就变成O(1)了,如下图所示;可见,路径压缩方便了以后的查找。
2、Union(x,y)时 按秩合并
即合并的时候将元素少的集合合并到元素多的集合中,这样合并之后树的高度会相对较小。
- 主要代码实现
注意:代码中路径压缩时秩不需变化的,正如Eillen所说,秩只是表示节点高度的一个上界如果用秩进行计数,路径压缩也是不需要变化的因为所属集合的根节点的秩在合并时已经更新,其他子节点的秩不用到也无需再变化;int father[MAX]; /* father[x]表示x的父节点*/
int rank[MAX]; /* rank[x]表示x的秩*/
/* 初始化集合*/
void Make_Set(int x)
{
father[x] = x; //根据实际情况指定的父节点可变化
rank[x] = 0; //根据实际情况初始化秩也有所变化
}
/* 查找x元素所在的集合,回溯时压缩路径*/
int Find_Set(int x)
{
if (x != father[x])
{
father[x] = Find_Set(father[x]); //这个回溯时的压缩路径是精华
}
return father[x];
}
/*
按秩合并x,y所在的集合
下面的那个if else结构不是绝对的,具体<strong>根据实际情况</strong>变化
但是,宗旨是不变的即,按秩合并,实时更新秩。
*/
void Union(int x, int y)
{
x = Find_Set(x);
y = Find_Set(y);
if (x == y) return;
if (rank[x] > rank[y])
{
father[y] = x;
rank[x] += rank[y];
}else
{
if (rank[x] == rank[y])
{
rank[y]++;
}
father[x] = y;
}
}注:学习并查集时非常感谢Slyar提供的资料,这里注明链接:http://www.slyar.com/blog/;另,本文于2009年记录于博客园:http://www.cnblogs.com/cherish_yimi/
另外,我认为写并查集时涉及到的路径压缩,最好用递归,一方面代码的可读性非常好,另一方面,可以更直观的理解路径压缩时在回溯时完成的巧妙。
作者:Yx.Ac
出处:勇幸|Thinking (http://www.ahathinking.com)