https://www.cnblogs.com/sammyliu/p/5225623.html
本系列文章总结 Linux 网络栈,包括:
(2)非虚拟化Linux环境中的网络分段卸载技术 GSO/TSO/UFO/LRO/GRO
(3)QEMU/KVM + VxLAN 环境下的 Segmentation Offloading 技术(发送端)
(4)QEMU/KVM + VxLAN 环境下的 Segmentation Offloading 技术(接收端)
1. Linux 网络路径

1.1 发送端
1.1.1 应用层
(1) Socket
应用层的各种网络应用程序基本上都是通过 Linux Socket 编程接口来和内核空间的网络协议栈通信的。Linux Socket 是从 BSD Socket 发展而来的,它是 Linux 操作系统的重要组成部分之一,它是网络应用程序的基础。从层次上来说,它位于应用层,是操作系统为应用程序员提供的 API,通过它,应用程序可以访问传输层协议。
- socket 位于传输层协议之上,屏蔽了不同网络协议之间的差异
- socket 是网络编程的入口,它提供了大量的系统调用,构成了网络程序的主体
- 在Linux系统中,socket 属于文件系统的一部分,网络通信可以被看作是对文件的读取,使得我们对网络的控制和对文件的控制一样方便。



UDP socket 处理过程 (来源) TCP Socket 处理过程(来源)
(2) 应用层处理流程
- 网络应用调用Socket API socket (int family, int type, int protocol) 创建一个 socket,该调用最终会调用 Linux system call socket() ,并最终调用 Linux Kernel 的 sock_create() 方法。该方法返回被创建好了的那个 socket 的 file descriptor。对于每一个 userspace 网络应用创建的 socket,在内核中都有一个对应的 struct socket和 struct sock。其中,struct sock 有三个队列(queue),分别是 rx , tx 和 err,在 sock 结构被初始化的时候,这些缓冲队列也被初始化完成;在收据收发过程中,每个 queue 中保存要发送或者接受的每个 packet 对应的 Linux 网络栈 sk_buffer 数据结构的实例 skb。
- 对于 TCP socket 来说,应用调用 connect()API ,使得客户端和服务器端通过该 socket 建立一个虚拟连接。在此过程中,TCP 协议栈通过三次握手会建立 TCP 连接。默认地,该 API 会等到 TCP 握手完成连接建立后才返回。在建立连接的过程中的一个重要步骤是,确定双方使用的 Maxium Segemet Size (MSS)。因为 UDP 是面向无连接的协议,因此它是不需要该步骤的。
- 应用调用 Linux Socket 的 send 或者 write API 来发出一个 message 给接收端
- sock_sendmsg 被调用,它使用 socket descriptor 获取 sock struct,创建 message header 和 socket control message
- _sock_sendmsg 被调用,根据 socket 的协议类型,调用相应协议的发送函数。
- 对于 TCP ,调用 tcp_sendmsg 函数。
- 对于 UDP 来说,userspace 应用可以调用 send()/sendto()/sendmsg() 三个 system call 中的任意一个来发送 UDP message,它们最终都会调用内核中的 udp_sendmsg() 函数。

1.1.2 传输层
传输层的最终目的是向它的用户提供高效的、可靠的和成本有效的数据传输服务,主要功能包括 (1)构造 TCP segment (2)计算 checksum (3)发送回复(ACK)包 (4)滑动窗口(sliding windown)等保证可靠性的操作。TCP 协议栈的大致处理过程如下图所示:

TCP 栈简要过程:
- tcp_sendmsg 函数会首先检查已经建立的 TCP connection 的状态,然后获取该连接的 MSS,开始 segement 发送流程。
- 构造 TCP 段的 playload:它在内核空间中创建该 packet 的 sk_buffer 数据结构的实例 skb,从 userspace buffer 中拷贝 packet 的数据到 skb 的 buffer。
- 构造 TCP header。
- 计算 TCP 校验和(checksum)和 顺序号 (sequence number)。
- TCP 校验和是一个端到端的校验和,由发送端计算,然后由接收端验证。其目的是为了发现TCP首部和数据在发送端到接收端之间发生的任何改动。如果接收方检测到校验和有差错,则TCP段会被直接丢弃。TCP校验和覆盖 TCP 首部和 TCP 数据。
- TCP的校验和是必需的
- 发到 IP 层处理:调用 IP handler 句柄 ip_queue_xmit,将 skb 传入 IP 处理流程。
UDP 栈简要过程:
- UDP 将 message 封装成 UDP 数据报
- 调用 ip_append_data() 方法将 packet 送到 IP 层进行处理。
1.1.3 IP 网络层 - 添加header 和 checksum,路由处理,IP fragmentation
网络层的任务就是选择合适的网间路由和交换结点, 确保数据及时传送。网络层将数据链路层提供的帧组成数据包,包中封装有网络层包头,其中含有逻辑地址信息- -源站点和目的站点地址的网络地址。其主要任务包括 (1)路由处理,即选择下一跳 (2)添加 IP header(3)计算 IP header checksum,用于检测 IP 报文头部在传播过程中是否出错 (4)可能的话,进行 IP 分片(5)处理完毕,获取下一跳的 MAC 地址,设置链路层报文头,然后转入链路层处理。
IP 头:

IP 栈基本处理过程如下图所示:

- 首先,ip_queue_xmit(skb)会检查skb->dst路由信息。如果没有,比如套接字的第一个包,就使用ip_route_output()选择一个路由。
- 接着,填充IP包的各个字段,比如版本、包头长度、TOS等。
- 中间的一些分片等,可参阅相关文档。基本思想是,当报文的长度大于mtu,gso的长度不为0就会调用 ip_fragment 进行分片,否则就会调用ip_finish_output2把数据发送出去。ip_fragment 函数中,会检查 IP_DF 标志位,如果待分片IP数据包禁止分片,则调用 icmp_send()向发送方发送一个原因为需要分片而设置了不分片标志的目的不可达ICMP报文,并丢弃报文,即设置IP状态为分片失败,释放skb,返回消息过长错误码。
- 接下来就用 ip_finish_ouput2 设置链路层报文头了。如果,链路层报头缓存有(即hh不为空),那就拷贝到skb里。如果没,那么就调用neigh_resolve_output,使用 ARP 获取。
1.1.4 数据链路层
功能上,在物理层提供比特流服务的基础上,建立相邻结点之间的数据链路,通过差错控制提供数据帧(Frame)在信道上无差错的传输,并进行各电路上的动作系列。数据链路层在不可靠的物理介质上提供可靠的传输。该层的作用包括:物理地址寻址、数据的成帧、流量控制、数据的检错、重发等。在这一层,数据的单位称为帧(frame)。数据链路层协议的代表包括:SDLC、HDLC、PPP、STP、帧中继等。
实现上,Linux 提供了一个 Network device 的抽象层,其实现在 linux/net/core/dev.c。具体的物理网络设备在设备驱动中(driver.c)需要实现其中的虚函数。Network Device 抽象层调用具体网络设备的函数。
、
1.1.5 物理层 - 物理层封装和发送

- 物理层在收到发送请求之后,通过 DMA 将该主存中的数据拷贝至内部RAM(buffer)之中。在数据拷贝中,同时加入符合以太网协议的相关header,IFG、前导符和CRC。对于以太网网络,物理层发送采用CSMA/CD,即在发送过程中侦听链路冲突。
- 一旦网卡完成报文发送,将产生中断通知CPU,然后驱动层中的中断处理程序就可以删除保存的 skb 了。
1.1.6 简单总结
 (来源)
(来源)
1.2 接收端
1.2.1 物理层和数据链路层


简要过程:
- 一个 package 到达机器的物理网络适配器,当它接收到数据帧时,就会触发一个中断,并将通过 DMA 传送到位于 linux kernel 内存中的 rx_ring。
- 网卡发出中断,通知 CPU 有个 package 需要它处理。中断处理程序主要进行以下一些操作,包括分配 skb_buff 数据结构,并将接收到的数据帧从网络适配器I/O端口拷贝到skb_buff 缓冲区中;从数据帧中提取出一些信息,并设置 skb_buff 相应的参数,这些参数将被上层的网络协议使用,例如skb->protocol;
- 终端处理程序经过简单处理后,发出一个软中断(NET_RX_SOFTIRQ),通知内核接收到新的数据帧。
- 内核 2.5 中引入一组新的 API 来处理接收的数据帧,即 NAPI。所以,驱动有两种方式通知内核:(1) 通过以前的函数netif_rx;(2)通过NAPI机制。该中断处理程序调用 Network device的 netif_rx_schedule 函数,进入软中断处理流程,再调用 net_rx_action 函数。
- 该函数关闭中断,获取每个 Network device 的 rx_ring 中的所有 package,最终 pacakage 从 rx_ring 中被删除,进入 netif _receive_skb 处理流程。
- netif_receive_skb 是链路层接收数据报的最后一站。它根据注册在全局数组 ptype_all 和 ptype_base 里的网络层数据报类型,把数据报递交给不同的网络层协议的接收函数(INET域中主要是ip_rcv和arp_rcv)。该函数主要就是调用第三层协议的接收函数处理该skb包,进入第三层网络层处理。
1.2.2 网络层


- IP 层的入口函数在 ip_rcv 函数。该函数首先会做包括 package checksum 在内的各种检查,如果需要的话会做 IP defragment(将多个分片合并),然后 packet 调用已经注册的 Pre-routing netfilter hook ,完成后最终到达 ip_rcv_finish 函数。
- ip_rcv_finish 函数会调用 ip_router_input 函数,进入路由处理环节。它首先会调用 ip_route_input 来更新路由,然后查找 route,决定该 package 将会被发到本机还是会被转发还是丢弃:
- 如果是发到本机的话,调用 ip_local_deliver 函数,可能会做 de-fragment(合并多个 IP packet),然后调用 ip_local_deliver 函数。该函数根据 package 的下一个处理层的 protocal number,调用下一层接口,包括 tcp_v4_rcv (TCP), udp_rcv (UDP),icmp_rcv (ICMP),igmp_rcv(IGMP)。对于 TCP 来说,函数 tcp_v4_rcv 函数会被调用,从而处理流程进入 TCP 栈。
- 如果需要转发 (forward),则进入转发流程。该流程需要处理 TTL,再调用 dst_input 函数。该函数会 (1)处理 Netfilter Hook (2)执行 IP fragmentation (3)调用 dev_queue_xmit,进入链路层处理流程。


1.2.3 传输层 (TCP/UDP)
- 传输层 TCP 处理入口在 tcp_v4_rcv 函数(位于 linux/net/ipv4/tcp ipv4.c 文件中),它会做 TCP header 检查等处理。
- 调用 _tcp_v4_lookup,查找该 package 的 open socket。如果找不到,该 package 会被丢弃。接下来检查 socket 和 connection 的状态。
- 如果socket 和 connection 一切正常,调用 tcp_prequeue 使 package 从内核进入 user space,放进 socket 的 receive queue。然后 socket 会被唤醒,调用 system call,并最终调用 tcp_recvmsg 函数去从 socket recieve queue 中获取 segment。
1.2.4 接收端 - 应用层
- 每当用户应用调用 read 或者 recvfrom 时,该调用会被映射为/net/socket.c 中的 sys_recv 系统调用,并被转化为 sys_recvfrom 调用,然后调用 sock_recgmsg 函数。
- 对于 INET 类型的 socket,/net/ipv4/af inet.c 中的 inet_recvmsg 方法会被调用,它会调用相关协议的数据接收方法。
- 对 TCP 来说,调用 tcp_recvmsg。该函数从 socket buffer 中拷贝数据到 user buffer。
- 对 UDP 来说,从 user space 中可以调用三个 system call recv()/recvfrom()/recvmsg() 中的任意一个来接收 UDP package,这些系统调用最终都会调用内核中的 udp_recvmsg 方法。
1.2.5 报文接收过程简单总结

2. Linux sk_buff struct 数据结构和队列(Queue)
2.1 sk_buff
(本章节摘选自 http://amsekharkernel.blogspot.com/2014/08/what-is-skb-in-linux-kernel-what-are.html)
2.1.1 sk_buff 是什么
当网络包被内核处理时,底层协议的数据被传送更高层,当数据传送时过程反过来。由不同协议产生的数据(包括头和负载)不断往下层传递直到它们最终被发送。因为这些操作的速度对于网络层的表现至关重要,内核使用一个特定的结构叫 sk_buff, 其定义文件在 skbuffer.h。Socket buffer被用来在网络实现层交换数据而不用拷贝来或去数据包 –这显著获得速度收益。
- sk_buff 是 Linux 网络的一个核心数据结构,其定义文件在 skbuffer.h。
- socket kernel buffer (skb) 是 Linux 内核网络栈(L2 到 L4)处理网络包(packets)所使用的 buffer,它的类型是 sk_buffer。简单来说,一个 skb 表示 Linux 网络栈中的一个 packet;TCP 分段和 IP 分组生产的多个 skb 被一个 skb list 形式来保存。
- struct sock 有三个 skb 队列(sk_buffer queue),分别是 rx , tx 和 err。

它的主要结构成员:

struct sk_buff {
/* These two members must be first. */ # packet 可以存在于 list 或者 queue 中,这两个成员用于链表处理
struct sk_buff *next;
struct sk_buff *prev;
struct sk_buff_head *list; #该 packet 所在的 list
...
struct sock *sk; #跟该 skb 相关联的 socket
struct timeval stamp; # packet 发送或者接收的时间,主要用于 packet sniffers
struct net_device *dev; #这三个成员跟踪该 packet 相关的 devices,比如接收它的设备等
struct net_device *input_dev;
struct net_device *real_dev;
union { #指向各协议层 header 结构
struct tcphdr *th;
struct udphdr *uh;
struct icmphdr *icmph;
struct igmphdr *igmph;
struct iphdr *ipiph;
struct ipv6hdr *ipv6h;
unsigned char *raw;
} h;
union {
struct iphdr *iph;
struct ipv6hdr *ipv6h;
struct arphdr *arph;
unsigned char *raw;
} nh;
union {
unsigned char *raw;
} mac;
struct dst_entry *dst; #指向该 packet 的路由目的结构,告诉我们它会被如何路由到目的地
char cb[40]; # SKB control block,用于各协议层保存私有信息,比如 TCP 的顺序号和帧的重发状态
unsigned int len, #packet 的长度
data_len,
mac_len, # MAC header 长度
csum; # packet 的 checksum,用于计算保存在 protocol header 中的校验和。发送时,当 checksum offloading 时,不设置;接收时,可以由device计算
unsigned char local_df, #用于 IPV4 在已经做了分片的情况下的再分片,比如 IPSEC 情况下。
cloned:1, #在 skb 被 cloned 时设置,此时,skb 各成员是自己的,但是数据是shared的
nohdr:1, #用于支持 TSO
pkt_type, #packet 类型
ip_summed; # 网卡能支持的校验和计算的类型,NONE 表示不支持,HW 表示支持,
__u32 priority; #用于 QoS
unsigned short protocol, # 接收 packet 的协议
security;
2.1.2 skb 的主要操作
(1)分配 skb = alloc_skb(len, GFP_KERNEL)

(2)添加 payload (skb_put(skb, user_data_len))

(3)使用 skb->push 添加 protocol header,或者 skb->pull 删除 header

2.2 Linux 网络栈使用的驱动队列 (driver queue)
(本章节摘选自 Queueing in the Linux Network Stack by Dan Siemon)
2.2.1 队列

在 IP 栈和 NIC 驱动之间,存在一个 driver queue (驱动队列)。典型地,它被实现为 FIFO ring buffer,简单地可以认为它是固定大小的。这个队列不包含 packet data,相反,它只是保存 socket kernel buffer (skb)的指针,而 skb 的使用如上节所述是贯穿内核网络栈处理过程的始终的。
该队列的输入时 IP 栈处理完毕的 packets。这些packets 要么是本机的应用产生的,要么是进入本机又要被路由出去的。被 IP 栈加入队列的 packets 会被网络设备驱动(hardware driver)取出并且通过一个数据通道(data bus)发到 NIC 硬件设备并传输出去。
在不使用 TSO/GSO 的情况下,IP 栈发到该队列的 packets 的长度必须小于 MTU。
2.2.2 skb 大小 - 默认最大大小为 NIC MTU
绝大多数的网卡都有一个固定的最大传输单元(maximum transmission unit, MTU)属性,它是该网络设备能够传输的最大帧(frame)的大小。对以太网来说,默认值为 1500 bytes,但是有些以太网络可以支持巨帧(jumbo frame),最大能到 9000 bytes。在 IP 网络栈内,MTU 表示能发给 NIC 的最大 packet 的大小。比如,如果一个应用向一个 TCP socket 写入了 2000 bytes 数据,那么 IP 栈需要创建两个 IP packets 来保持每个 packet 的大小等于或者小于 1500 bytes。可见,对于大数据传输,相对较小的 MTU 会导致产生大量的小网络包(small packets)并被传入 driver queue。这成为 IP 分片 (IP fragmentation)。
下图表示 payload 为 1500 bytes 的 IP 包,在 MTU 为 1000 和 600 时候的分片情况:

理解 Linux 网络栈(2):非虚拟化Linux 环境中的 Segmentation Offloading 技术
https://www.cnblogs.com/sammyliu/p/5227121.html
本系列文章总结 Linux 网络栈,包括:
(2)非虚拟化Linux环境中的网络分段卸载技术 GSO/TSO/UFO/LRO/GRO
(3)QEMU/KVM + VxLAN 环境下的 Segmentation Offloading 技术(发送端)
(4)QEMU/KVM + VxLAN 环境下的 Segmentation Offloading 技术(接收端)
第一篇文章总结了Linux 网络协议栈的概括和功能。本文总结非虚拟化环境中的各种 Segmentation Offloading 技术。
1. 为什么需要 Segmentation offloading
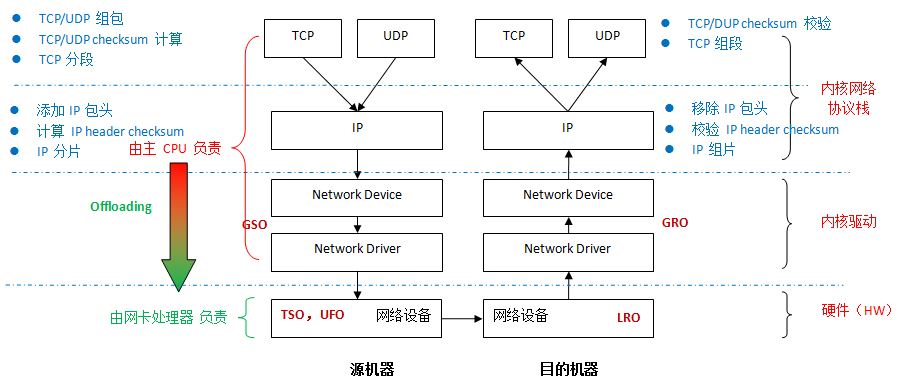
从第一篇文章的介绍中我们知道,Linux 内核传输层和网络层都要做大量的计算工作,具体见上图,这些计算都在服务器的主 CPU 中进行。这里有一些网络协议栈计算所需要的 CPU 资源的一些参考数据。大体上,发送或者接收 1 bit/s 的数据需要 1 赫兹的 CPU 处理能力,也就是说,5 Git/s (625 MB/s) 的网络流量大概需要 5 GHz 的 CPU 处理能力,相当于此时需要 2 个 2.5 Ghz 的多核处理器。因为以太网是单向的,发送和接收 10 Gbit/s (吞吐量就是 20 10 Gbit/s)时,大概需要 8 个 2.5 GHz 的 CPU 内核。
这些计算大概可以分为两类:(1)数据计算,比如校验和计算和验证、分包和组包等,这个和所处理的 packets 的数量有关(2)数据传输和上下文切换带来的 overhead,这个和传输和切换的次数有关。
为了解决问题,考虑到越来越多的物理网卡具有较强的处理能力,就出现了两个思路:
(1)如果网卡能够支持某些 Linux 内核协议栈所承担的计算任务,那么就可以将这些计算从协议栈 offload (卸载)到物理网卡。
(2)如果网卡不能支持这些计算,那么尽可能地将这些计算在 Linux 内核网络栈中延后(传输过程)和提前(接收过程)来减少 overhead。以 TCP 分组或者 IP 分片为例,延迟该过程,可以减少在网络栈中传输和处理的 packets 的数目,从而减少数据传输和上下文切换所需要的主 CPU 计算能力。
2. Segmentation offloading 技术
2.1 TSO (TCP Segmentation Offloading)
2.1.1 TCP Segmentation (TCP 分段)
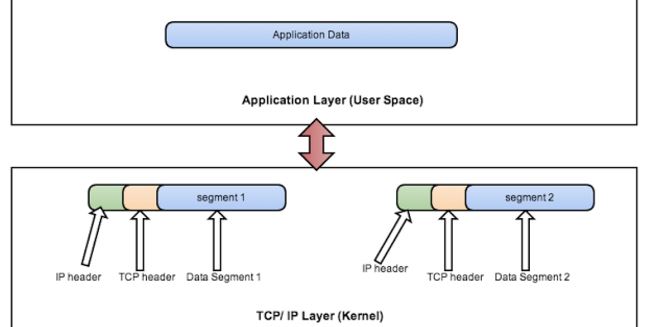
MSS(Maxium Segment Size): MSS 是 TCP 数据段每次能够传输的最大数据分段的长度。为了达到最佳的传输效能,TCP 协议在建立连接的时候通常要协商双方的 MSS 值,这个值 TCP 协议在实现的时候往往用 MTU 值代替( MSS = MTU - IP 数据包包头大小20Bytes - TCP 数据段的包头大小20Bytes),所以在默认以太网 MTU 为 1500 bytes 时,MSS为 1460。
TCP 分段:当网络应用发给 TCP 的 message 的长度超过 MSS 时,TCP 会对它按照 MSS 的大小将其分为多个小的 packet,并且在每个 packet 上添加 TCP Header 成为一个 TCP 段(segement)。
2.1.2 TSO
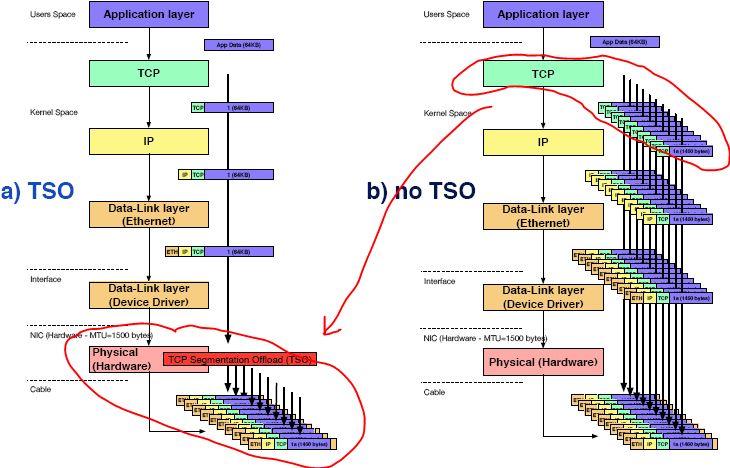
TSO 是一种利用网卡分割大数据包,减小 CPU 负荷的一种技术,也被叫做 LSO (Large segment offload) ,如果数据包的类型只能是 TCP,则被称之为 TSO,如果硬件支持 TSO 功能的话,也需要同时支持硬件的 TCP 校验计算和分散 - 聚集 (Scatter Gather) 功能。可以看到 TSO 的实现,需要一些基本条件,而这些其实是由软件和硬件结合起来完成的,对于硬件,具体说来,硬件能够对大的数据包进行分片,分片之后,还要能够对每个分片附着相关的头部。
TSO 就是将由 TCP 协议栈所做的 TCP 分段交给具有这种能力的物理网卡去做,因此它需要如下支持:
- 物理网卡支持。
- Linux 网卡驱动支持。可以使用 ethtool -K ethX tso on 命令打开网卡和驱动对 TSO 的支持,如果返回错误则表示不支持。
- 还需要 Net:TCP checksum offloading and Net:Scatter Gather 支持。
使用 TSO 以后,应用发出的大的数据块在不超过 64k 的情况下,将会直接经过Linux 网络栈发到网卡的驱动的 driver queue,然后在网卡中根据 skb 中的预设分组数据(主要是 MSS)对它执行 TCP 分段。下图是使用 TSO 和不使用 TSO 的情形的对比:
2.2 UFO - UDP Fragmentation Offload
UDP 数据报,由于它不会自己进行分段,因此当长度超过了 MTU 时,会在网络层进行 IP 分片。同样,ICMP(在网络层中)同样会出现IP分片情况。
2.2.1 IP fragmentation (分片)
MTU 和 IP 分片:
- MTU:上文已经说过了,MTU 是链路层中的网络对数据帧的一个限制,依然以以太网为例,默认 MTU 为1500字节。
- IP 分片:一个 IP 数据报在以太网中传输,如果它的长度大于该 MTU 值,就要进行分片传输,使得每片数据报的长度小于MTU。分片传输的 IP 数据报不一定按序到达,但 IP 首部中的信息能让这些数据报片按序组装。IP数据报的分片与重组是在网络层进完成的。
IP 分片和 TCP 分段的区别:
- IP 数据报分片后,只有第一片带有UDP首部或ICMP首部,其余的分片只有IP头部,到了端点后根据IP头部中的信息再网络层进行重组。而 TCP 报文段的每个分段中都有TCP 首部,到了端点后根据 TCP 首部的信息在传输层进行重组。IP数据报分片后,只有到达目的地后才进行重组,而不是向其他网络协议,在下一站就要进行重组。
- 对 IP 分片的 TCP segment (段)来说,即使只丢失一片数据, TCP 层也要重新传整个数据报。这是因为IP层本身没有超时重传机制------由更高层(比如TCP)来负责超时和重传。当来自TCP报文段的某一段(在IP数据报的某一片中)丢失后,TCP在超时后会重发整个TCP报文段,该报文段对应于一份IP数据报(可能有多个IP分片),没有办法只重传数据报中的一个数据分片。这就是为什么对 TCP 来说要尽量避免 IP 分片的原因。
IP 分片和 TCP 分段的关系:
- 在非虚拟化环境中,MSS 肯定是要比 MTU 小的,因此,每个 TCP 分组不再需要 IP 分片就可以直接交给网卡去传输。
- 在虚拟户环境中,如果配置不当,虚机网络应用的 TCP 连接的 MSS 比宿主机物理网卡的 MTU 大的情况下,宿主机上还是会执行 IP 分片的。
2.2.2 UFO
UDP 协议层本身不对大的数据报进行分片,而是交给 IP 层去做。因此,UFO 就是将 IP 分片 offload 到网卡(NIC)中进行。其原理同 TSO。
"IPv4/IPv6: UFO (UDP Fragmentation Offload) Scatter-gather approach: UFO is a feature wherein the Linux kernel network stack will offload the IP fragmentation functionality of large UDP datagram to hardware. This will reduce the overhead of stack in fragmenting the large UDP datagram to MTU sized packets"
2.3 GSO - Generic Segemetation Offload
TSO 是使得网络协议栈能够将大块 buffer 推送至网卡,然后网卡执行分片工作,这样减轻了 CPU 的负荷,但 TSO 需要硬件来实现分片功能;而性能上的提高,主要是因为延缓分片而减轻了 CPU 的负载,因此,可以考虑将 TSO 技术一般化,因为其本质实际是延缓分片,这种技术,在 Linux 中被叫做 GSO(Generic Segmentation Offload)。它比 TSO 更通用,原因在于它不需要硬件的支持分片就可使用,对于支持 TSO 功能的硬件,则先经过 GSO 功能,然后使用网卡的硬件分片能力执行分片;而对于不支持 TSO 功能的网卡,将分片的执行,放在了将数据推送的网卡的前一刻,也就是在调用驱动的 xmit 函数前。
2.3.1 对于 UDP,在物理网卡不支持 UFO 时,使用和不使用 GSO 的情形
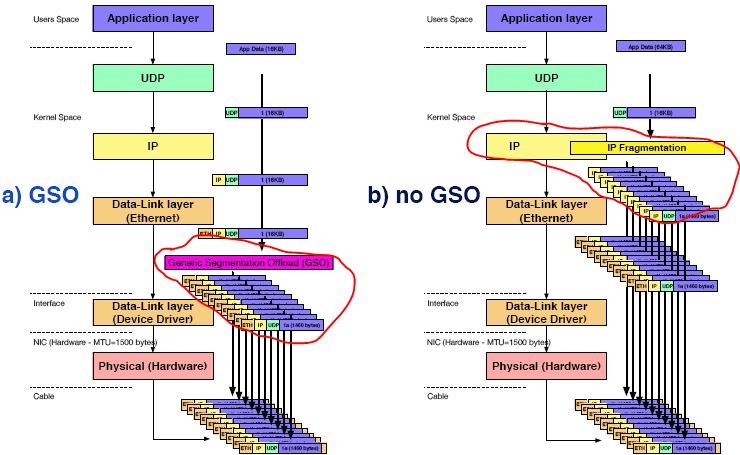
注意这两者中间的重要区别:
- 当没有 GSO 时,UDP 包会在 IP 层做 IP 分片,这会带来比较严重的问题,包括:依赖于 PMTU,这个技术在很多的实际网络中有时候无法工作;在高速网络中,IPv4 packet ID 有时候会重复而导致数据损坏(Breaks down on high-bandwidth links because the IPv4 16-bit packet ID value can wrap around, causing data corruption);它将 UDP 头算在 payload 内,因此只有第一个分片有 UDP 头,因此一个分片丢失会导致整个IP包的损失。
- 当有 GSO 时,由 Linux UDP 协议栈提供 UDP 分片逻辑而不是 IP 分片逻辑,这使得每个分片都有完整的 UDP 包头,然后继续 IP 层的 GSO 分片。所以 GSO 本身是对 UFO 的优化。
2.3.2 GSO for UDP 代码分析
GSO for UDP 代码在 http://www.mit.edu/afs.new/sipb/contrib/linux/net/ipv4/udp_offload.c:
- UDP GSO 回调函数:
static const struct net_offload udpv4_offload = {
.callbacks = {
.gso_segment = udp4_ufo_fragment,
.gro_receive = udp4_gro_receive,
.gro_complete = udp4_gro_complete,
},
}
函数 udp4_ufo_fragment 最终调用 skb_segment 函数进行分片:
/**
* skb_segment - Perform protocol segmentation on skb.
* @head_skb: buffer to segment
* @features: features for the output path (see dev->features)
*
* This function performs segmentation on the given skb. It returns
* a pointer to the first in a list of new skbs for the segments.
* In case of error it returns ERR_PTR(err).
*/
struct sk_buff *skb_segment(struct sk_buff *head_skb,
netdev_features_t features)
- 在函数 static int ip_finish_output_gso(struct net *net, struct sock *sk, struct sk_buff *skb, unsigned int mtu) 中能看到,首先按照 MSS 做 GSO,然后在调用 ip_fragment 做 IP 分片。可见,在通常情况下(虚机 TCP MSS 要比物理网卡 MTU 小),只做 UDP GSO 分段,IP 分片是不需要做的;只有在特殊情况下 (虚机 TCP MSS 超过了宿主机物理网卡 MTU),IP 分片才会做。这个和试验中看到的效果是相同的。
2.3.3 对 TCP,在网卡不支持 TSO 时,使用和不使用 GSO 的情形

两者都是 TCP 分片,只是位置不同。
2.3.4 GSO for TCP 代码逻辑分析
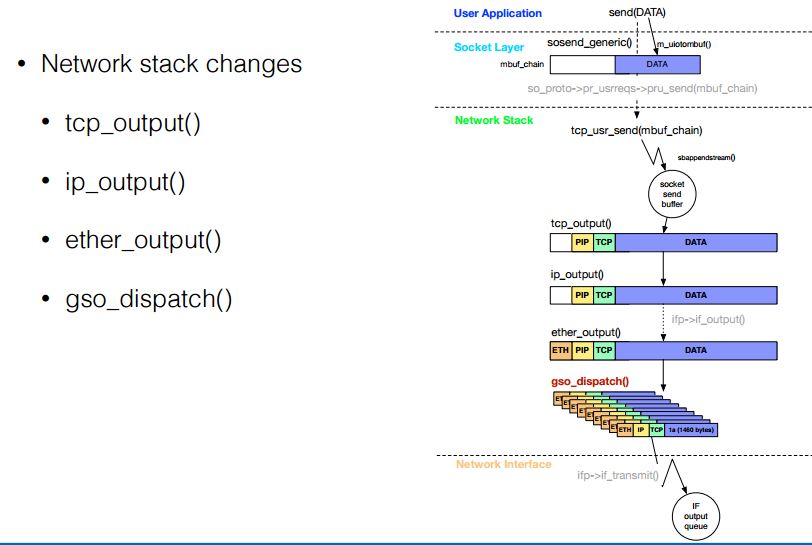
(1)tcp_output 函数
1. Checks if GSO is enabled:
sysctl net.inet.tcp.gso = 1
sysctl net.gso.”ifname”.enable_gso = 1
2. Checks if the packet length exceeds the MTU
If 1 and 2 are true, sets GSO flag: m->m_pkthdr.csum_flags |= GSO_TO_CSUM(GSO_TCP4);
(2)ip_output 函数
If GSO is enabled and required, then avoids checksum (IP & TCP) and avoids IP Fragmentation
(3)ether_output 函数
If GSO is enabled and required: calls gso_dispatch() instead of ifp->transmit()
(4)gso_dispatch 函数
int gso_dispatch(struct ifnet *ifp, struct mbuf *m, u_int mac_hlen)
{
…
gso_flags = CSUM_TO_GSO(m->m_pkthdr.csum_flags);
…
error = gso_functions[gso_flags](ifp, m, mac_hlen);
return error;
}
(5)gso_functions 函数
gso_functions[GSO_TCP4] gso_ip4_tcp(…) - GSO on TCP/IPv4 packet 1. m_seg(struct mbuf *m0, int hdr_len, int mss, …) returns the mbuf queue that contains the segments of the original packet (m0). hdr_len - first bytes of m0 that are copied in each new segments mss - maximum segment size 2. fixes TCP and IP headers in each new segments 3. sends new segments to the device driver [ifp->if_transmit()]
2.4 LRO (Large Receive Offload)
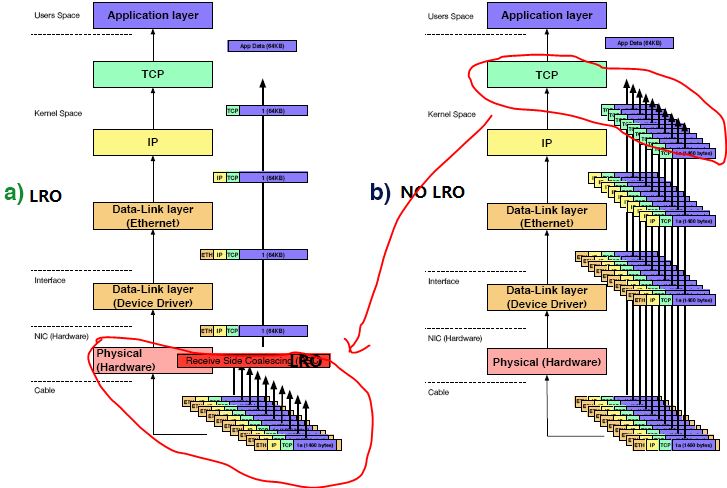
Linux 在 2.6.24 中加入了支持 IPv4 TCP 协议的 LRO (Large Receive Offload) ,它通过将多个 TCP 数据聚合在一个 skb 结构,在稍后的某个时刻作为一个大数据包交付给上层的网络协议栈,以减少上层协议栈处理 skb 的开销,提高系统接收 TCP 数据包的能力。当然,这一切都需要网卡驱动程序支持。理解 LRO 的工作原理,需要理解 sk_buff 结构体对于负载的存储方式,在内核中,sk_buff 可以有三种方式保存真实的负载:
- 数据被保存在 skb->data 指向的由 kmalloc 申请的内存缓冲区中,这个数据区通常被称为线性数据区,数据区长度由函数 skb_headlen 给出
- 数据被保存在紧随 skb 线性数据区尾部的共享结构体 skb_shared_info 中的成员 frags 所表示的内存页面中,skb_frag_t 的数目由 nr_frags 给出,skb_frags_t 中有数据在内存页面中的偏移量和数据区的大小
- 数据被保存于 skb_shared_info 中的成员 frag_list 所表示的 skb 分片队列中
合并了多个 skb 的超级 skb,能够一次性通过网络协议栈,而不是多次,这对 CPU 负荷的减轻是显然的。
2.5 GRO (Generic Receive Offloading)
前面的 LRO 的核心在于:在接收路径上,将多个数据包聚合成一个大的数据包,然后传递给网络协议栈处理,但 LRO 的实现中存在一些瑕疵:
- 数据包合并可能会破坏一些状态
- 数据包合并条件过于宽泛,导致某些情况下本来需要区分的数据包也被合并了,这对于路由器是不可接收的
- 在虚拟化条件下,需要使用桥接功能,但 LRO 使得桥接功能无法使用
- 实现中,只支持 IPv4 的 TCP 协议
而解决这些问题的办法就是新提出的 GRO。首先,GRO 的合并条件更加的严格和灵活,并且在设计时,就考虑支持所有的传输协议,因此,后续的驱动,都应该使用 GRO 的接口,而不是 LRO,内核可能在所有先有驱动迁移到 GRO 接口之后将 LRO 从内核中移除。GRO 和 LRO 的最大区别在于,GRO 保留了每个接收到的数据包的熵信息,这对于像路由器这样的应用至关重要,并且实现了对各种协议的支持。以 IPv4 的 TCP 为例,匹配的条件有:
- 源 / 目的地址匹配
- TOS/ 协议字段匹配
- 源 / 目的端口匹配
这篇文章 linux kernel 网络协议栈之GRO(Generic receive offload) 详细分析了 GRO 代码。
2.5.1 在不支持 LRO 的情况下,对 TCP 使用和不使用 GRO 的情形

2.6 TCP/UDP Segementation Offload 小结
2.6.1 小结
| Offload | 传输段还是接收端 | 针对的协议 | Offloading 的位置 | ethtool 命令输出中的项目 | ethtool 命令中的 option | 网卡/Linux 内核支持情况 |
| TSO | 传输段 | TCP | NIC | tcp-segmentation-offload | tso |
Linux 内核从 2.5.33 引入 (2002) 网卡普遍支持 |
| UFO | 传输段 | UDP | NIC | udp-fragmentation-offload | ufo |
linux 2.6.15 引入 (2006) 网卡普遍不支持 |
| GSO | 传输段 | TCP/UDP | NIC 或者 离开 IP 协议栈进入网卡驱动之前 | generic-segmentation-offload | gso |
GSO/TCP: Linux 2.6.18 中引入(2006) GSO/UDP: linux 3.16 (2014) |
| LRO | 接收段 | TCP | NIC | large-receive-offload | lro |
Linux 内核 2.6.24 引入(2008) 网卡普遍支持 |
| GRO | 接收段 | TCP | NIC 或者离开网卡驱动进入 IP 协议栈之前 | generic-receive-offload | gro |
Linux 内核 2.6.18 引入(2006) 网卡普遍支持 |
2.6.2 性能对比
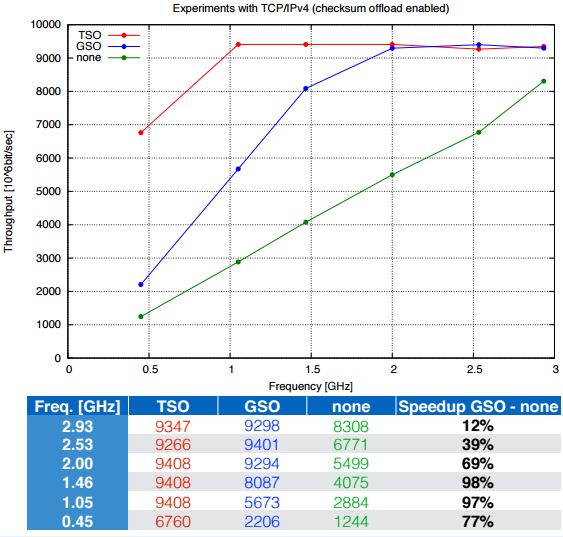
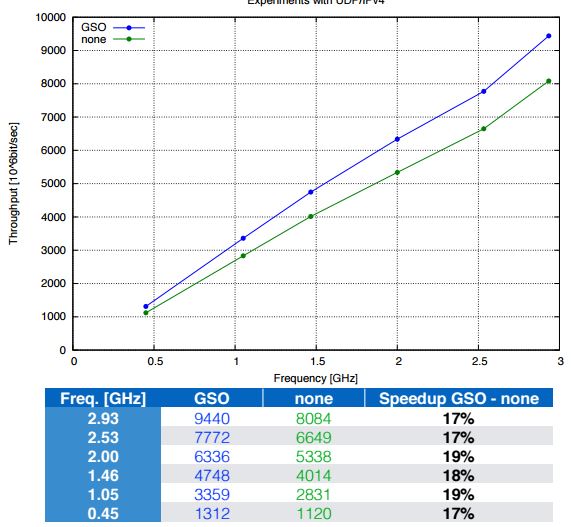
[TSO/GSO for TCP/IPv4] [GSO for UDP/IPv4]
从这图也可以看出:
- 对 TCP 来说,在 CPU 资源充足的情况下,TSO/GSO 能带来的效果不大,但是在CPU资源不足的情况下,其带来的改观还是很大的。
- 对 UDP 来说,其改进效果一般,改进效果不超过 20%。所以在 VxLAN 环境中,其实是可以把 GSO 关闭,从而避免它带来的一些潜在问题。
2.6.3 Offloading 带来的潜在问题
分段offloading 可能会带来潜在的问题,比如网络传输的延迟 latency,因为 packets 的大小的增加,大大增加了 driver queue 的容量(capacity)。比如说,系统一方面在使用大的 packet size 传输大量的数据,同时在运行许多的交换式应用(interactive application)。因为交互式应用会定时发送许多小的packet,这时候可能会应为这些小的 packets 被淹没在大的 packets 之中,需要等待较长的时间才能被处理,这可能会带来不可接受的延迟。
在网络上也能看到一些建议,在使用这些 offloading 技术时如果发现莫名的网络问题,建议先将这些技术关闭后再看看情况有没有改变。