这是以前的一篇草稿,当初没写完,今天发出来,但总觉得水平有限,越学越觉得自己菜,写的博客水准低,发完这篇以后就谨慎发博了,毕竟自己菜,不能老吹B,下面是原稿。
好久没更了,本来年前想写篇关于爬虫的总结来,结果在家懒癌发作,开学了也没“挤”出时间来。今天主要是心情好,写下自己学到的一点知识,长了一点人生的经验。
前两周看了HMM和CRF的知识,因为最近做的东西要用到,这两天在用crf++,目前最新的好像是0.58版,再新的没找到资源,貌似0.54之后就只有发布的exe了,0.53版的还有源码,感兴趣的同学可以看看源码(我打算最近两天看)。用一个东西首先要看它的官方文档,对一些命令什么的看过之后,卡在了一个地方——template,文档上只说template里是训练时生成特征函数的,并解释了一下形如U00:%x[-2,0]的含义,但是,对于我们这种菜鸡,根本理解不了啊。问题主要有三个(首先假设我们有如下的template:)
# Unigram U00:%x[-2,0] U01:%x[-1,0] U02:%x[0,0] U03:%x[1,0] U04:%x[2,0] U05:%x[-2,0]/%x[-1,0]/%x[0,0] U06:%x[-1,0]/%x[0,0]/%x[1,0] U07:%x[0,0]/%x[1,0]/%x[2,0] U08:%x[-1,0]/%x[0,0] U09:%x[0,0]/%x[1,0] # Bigram B
1)U00~U04组合起来是什么意思;2)形如U05~U09那样的是什么意思;3)模版怎么写
知道问题就可以有目的的搜索,搜索结果大致是怎么理解crf++中的模版、用crf++进行中文标注、crf++模版格式等等,看了一堆,主要收获就是形如U09 是联合概率,剩下的都是和官网文档差不多,大多数文章相似度很高(哈哈哈),也算小小的解决了第二个问题,别的我依然蒙蔽。
今晚找老大聊了聊,老大解决了我的疑惑,又学到了一点人生的经验。下面说一下我得理解。
首先假设我们知道CRF(s因为有的加了)的概念,知道计算P(y|X)的公式
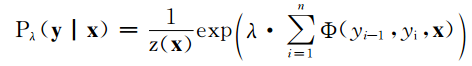
然后我们在模型中使用某特征(暂且叫字符n-gram特征),其具体特征形式化描述为
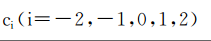
下标表示距离当前考察字符的相对位置,上一句意思就是对位置i,还要考察其前面两个字符和后面两个字符来计算其 Φ,比如: 我是中国人,考察中的时候还要考察我 是 国 人,模版写出来就是我们的U00~U04。
上面理解了,U05-U09就好理解了,它们其实就是像U00-U04这样的特征的组合,还是上面那个例子,U08表示 是/中。U08、U09这样的叫bigram(和下面的Bigram不同,一般而言比Bigram灵活一点),U05-U07叫trigram。其实在crf++代码是现中根据模板生成的特征也不过是一些字符串和对应的编号,然后通过学习得到特征函数的权重。
关于模板怎么写,这取决于你,一般来说会有一个窗口(即考虑当前token前几个后几个),大小自定义,源码里好像限制窗口最大为17,如果你的特征有多列,可能要多写些像U00-U04这样的模板不同的地方在于[,]里的第二项还有像U05-U09这样的组合特征模板,下面的Bigram特征一般没用,用的话也是最简单的B。
其实现在看来当初的疑问很简单,大家都是事后诸葛亮,但还是希望亡羊补牢为时未晚。学东西还是要学透,不然笨鸟还是笨鸟,最后连飞都飞不动了。