目的:本文会对oracle 11gR2 集群件(Grid Infrastructure,以下简称GI) 新特性 agent进行介绍,包括 agent的功能,常见的agent介绍,以及基本的诊断方法。
适用范围:11.2.0.1及以上版本。
首先我们对10gR2 crs 管理资源的方法进行简单的介绍。在10gR2 当中,crsd 负责对集群中的资源进行管理。具体说来,crsd 调用相关的racg脚本,产生racg进程对资源进行管理,例如racgvip 脚本用来管理vip资源。这种管理办法,由于是racg进程进行对资源的操作,有时候会存在一些问题。从11gR2 GI开始, agent 作为一个全新的架构对GI中所有的资源进行管理,这种全新的agent 架构使资源管理更加强壮,性能更好。
接下来我们对agent的特点进行一些介绍。
1.几乎所有的资源和daemon都是由agent 管理的。例如gipc, gpnp等 由ohasd 产生的orarootagent管理。
2.Agent守护进程是多线程的,而且是HA(High Available)进程.
3.Ohasd 会产生下面的agent
cssdagent(这个agent代表命令“crsctl stat res –t –init” 中的资源ora.cssd )
orarootagent
oraagent
cssdmonitor
Crsd 会产生下面的agent
orarootagent
Oraagent
用户自定义的agent.
注意:用户oracle和grid都会产生各自对应的oraagent来管理各自的资源。例如 oraagent_grid管理资源ora.asm, oraagent_oracle管理ora.<database_name>.db资源。
下面我们对agent如何管理资源进行介绍。首先,agent 拥有一些EP(Entry Point),类似于可以对资源执行的动作。
Start:启动资源
Stop:停止资源
Check:检查资源的状态,如果发现了资源状态改变,则agent会通知GI,资源状态发生了改变。
Clean:清理资源,一般来说清理资源会在资源存在问题,需要重新启动或failover之前发生。
Abort:中止资源。
当以上的任意EP结束之后,会返回以下返回值中的一个,而这些返回值也对应着资源的状态。
ONLINE:在线。对应资源的online状态
OFFLINE:离线。对应资源的offline状态。对于offline状态,可以细分为planed offline 和unplaned offline。Planed offline是指GI倾向于这个资源处在offline状态,例如我们使用GI相关的工具(srvctl, crsctl)停止了一个资源,这种情况,GI就认为资源应该处于offline状态,因为停止资源的操作是通过GI来实现的。同时,对于planed offline的资源,它的target状态也会被修改为offline状态,这意味着,如果在资源的target状态为offline时重启GI stacks,除非资源的auto_start属性设置为always,否则,该资源不会被自动启动(关于target状态,和属性auto_start的更多信息,请参考oracle联机文档Oracle Clusterware Administration and Deployment Guide 11g Release 2)。对于unplaned offline,是指资源被GI以外的工具停止,例如使用sqlplus手动关闭数据库,在这种情况下,GI并不认为该资源应该处于offline状态,资源的target状态仍然为online,所以,资源在重新启动GI时仍然会被启动,当然除非资源的auto_start属性设置为never。
UNKNOWN:未知,对应资源的unknown状态。在这种状态下,agent会继续对该资源进行check。
PARTIAL:资源部分在线,对应资源的intermediate状态。 在这种情况下agent会继续对该资源进行check,并及时更新资源状态。
FAILED:失败。该返回值说明资源存在问题,不能正常工作,agent会首先执行clean EP,之后根据资源的相关属性进行failover或restart操作。
之后,我们可以通过下面这张表格了解agent与负责管理的资源的对应关系。
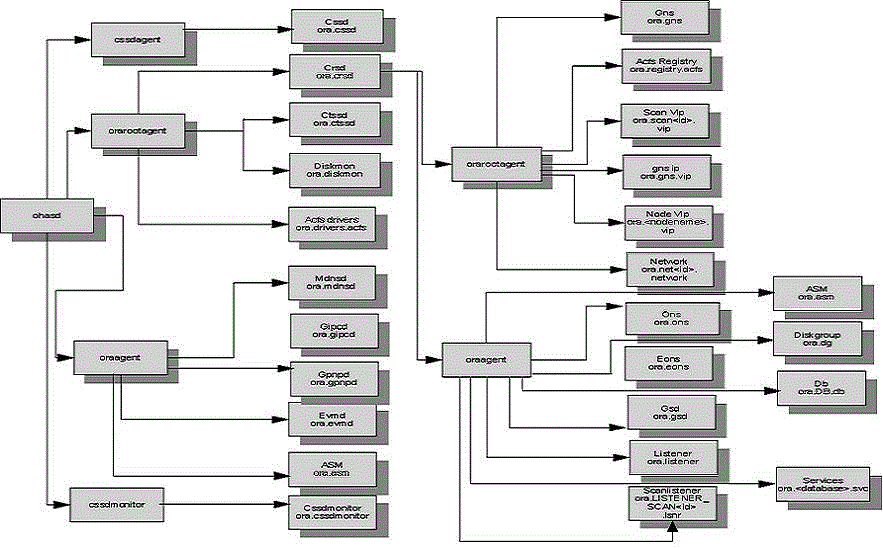

最后,我们对agent相关的trace文件进行简单的介绍。首先,agent的trace 文件位于路径GRID_HOME/log/<host>/agent下,以下是比较详细的信息。
GRID_HOME/log/<host>/agent /ohasd/orarootagent_root <– ohasd产生的orarootagent日志
GRID_HOME/log/<host>/agent/ohasd/oraagent_grid <– ohasd产生的oraagent日志
GRID_HOME/log/<host>/agent/ohasd/oracssdagent_root <– ohasd产生的cssdagent日志
GRID_HOME/log/<host>/agent/ohasd/oracssdmonitor_root <– ohasd产生的cssdmonitor日志
GRID_HOME/log/<host>/agent/crsd/oraagent_grid <– crsd产生的oraagent日志,owner为grid
GRID_HOME/log/<host>/agent/crsd/oraagent_oracle <– crsd产生的oraagent日志,owner为oracle
GRID_HOME/log/<host>/agent/crsd/orarootagent_root <–crsd产生的orarootagent日志
另外,以下的文件对诊断agent相关的问题也很有帮助。
集群alert log(Grid_home/log/<hostname>/alert<hostname>.log)
Grid_home/log/<hostname>/ohasd/ohasd.log
Grid_home/log/<hostname>/crsd/crsd.log
由于每个agent需要管理多个资源,所以,如果只是某一个资源存在问题,可以使用有问题的资源名称过滤agent日志会更有效率,当然Agent日志的可读性很好,在这里不进行详细的介绍。Agent如果crash,一般情况下,会产程一个core文件(Grid_home/log/<hostname>/agent/{ohasd|crsd}/<agent名>_<用户名>)和对应的堆栈文件(Grid_home/log/<hostname>/agent/{ohasd|crsd}/<agent名>_<用户名>/<agent名>_<用户名>OUT.log)。