一、什么是组合搜索
我们在很多网站都可以找到组合搜索的功能,例如博客园、汽车之家等。

在汽车的组合搜索中,可以看到有 价格、级别、国别、品牌、结构等过滤条件。
这些条件我们可以认为都对应数据库的一张表(实际上静态的条件可以放内存)。
当我们选择条件时,页面所展示的内容要根据我们选择的条件进行过滤(对应数据库中过滤条件)。
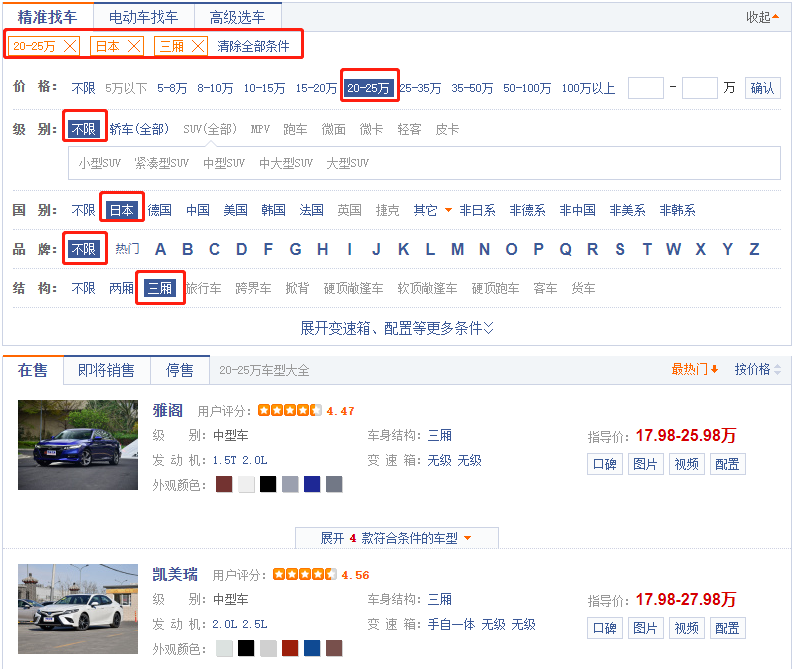
二、如何实现的
1.观察实例
我们在选择各种过滤条件的时候,观察浏览器的URL变化:

可以发现,当我们全部选择 "不限" 的时候,URL变为:

list后面的所有数字全部变为0。说明,各项条件中"不限"对应的状态数字就是0。在数据库中自增ID是从1开始的,所以0用于表示ALL(即不过滤)。
当我们选择一些条件时,例如选择国别为中国,级别为微型车,可以看到URL变为:

也就是说这些数字就代表了我们选择的条件。对应在数据库中,该条件对应的ID就是这个数字。
2.实现思路
1)页面上分别将所有的条件列举出来
2)当我们点击某个条件时,触发事件,获取所有条件对应的ID,然后串在一起。并请求页面,将串在一起的字符串作为请求URL的一部分。
3)路由系统通过正则表达式可以获取到每个条件的ID,然后通过参数传递给视图函数。
4)视图函数将获得的条件ID作为数据库查询条件,查询对应的内容。
三、实现一个简单的组合搜索
HTML代码:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Index</title> <style> .condition{ padding: 5px; } /*a标签的默认样式*/ .condition a{ display: inline-block; padding: 3px 5px; text-decoration: none; color: #3B5998; } </style> </head> <body> <div style=" 800px;margin:0 auto;border: 1px solid #dddddd"> <h2>过滤条件</h2> <div class="condition"> <!-- 不限这个按钮,category_id一定为0,但点击它不能改变article_type_id,所以要将上次请求的article_type_id放进href中 --> <a id="a_cate_0" href="/app01/index-0-{{ last_args.article_type_id }}/">不限</a> <!-- 其他从1开始的category_id随着循环来设置,但article_type_id同样不能动 --> {% for row in category_list %} <!-- 这里设置一个id,用于JS操作样式 --> <a id="a_cate_{{ row.id }}" href="/app01/index-{{ row.id }}-{{ last_args.article_type_id }}/">{{ row.caption }}</a> {% endfor %} </div> <!-- article_type_list和category一样,只是反了一下 --> <div class="condition"> <a id="a_art_0" href="/app01/index-{{ last_args.category_id }}-0/">不限</a> {% for row in article_type_list %} <a id="a_art_{{ row.id }}" href="/app01/index-{{ last_args.category_id }}-{{ row.id }}/">{{ row.caption }}</a> {% endfor %} </div> <h2>查询结果</h2> <ul> {% for row in result %} <li style="padding: 10px;"> <div style="font-weight: bold;">{{ row.title}}</div> <div> {{ row.content }} </div> </li> {% endfor %} </ul> </div> <script src="/static/js/jquery-1.12.4.js"></script> <script> $(function(){ // 每次请求的页面,一加载完,就将该页面对应的过滤条件<a>标签染色 $("#a_cate_{{ last_args.category_id }}").css("background-color","#3B5998").css("color","white"); $("#a_art_{{ last_args.article_type_id }}").css("background-color","#3B5998").css("color","white"); }) </script> </body> </html>
路由:
urlpatterns = [ re_path('^index-(?P<category_id>d+)-(?P<article_type_id>d+)/$', views.index), ]
视图函数代码:
def index(request, **kwargs): # 获取参数,如果为0,为不限,则不加入过滤条件中 condition_dict = {} for k, v in kwargs.items(): if v != '0': condition_dict[k] = v # 获取所有的category、article_type_list和博客内容 category_list = models.Category.objects.all() article_type_list = models.ArticleType.objects.all() result = models.Article.objects.filter(**condition_dict) # 将过滤条件和内容,以及该次请求的id传回页面 return render(request, 'index.html', {'result': result, 'category_list': category_list, 'article_type_list': article_type_list, 'last_args': kwargs})
实现效果:

四、JSONP
JSON是一种数据格式,用于不同语言程序之间可以传递数据。
JSONP是一种操作方式(或者说是一种技巧)。
1.跨域请求数据
跨域请求数据,我们可以才用以下两种方式:
1)我们在视图函数中使用requests包,来请求其他网站提供的数据接口。(可行)
2)直接使用前端JS代码来请求其他网站的数据接口。(直接使用Ajax来请求不可行)
为什么第二种方式不可行:
因为AJAX直接请求跨域数据接口,浏览器会拒收其返回的响应数据。浏览器报错:

2.什么是JSONP
当我们想直接使用前端Ajax来请求跨域的API时(返回JSON数据,例如天气网站提供的接口),浏览器会拒收这种方式的响应,我们无法获取到数据。
在这种情况下,我们发现有个取巧的地方,虽然浏览器阻止直接使用Ajax请求,但使用<script>标签可以获取远程站点的JS文件。例如:
<script src="https://code.jquery.com/jquery-1.12.4.js"></script>
使用script标签来引入远程JS文件的时候,浏览器并没有阻止。
那么,我们可以利用script这个后门,来达到我们获取数据的目的。
前提,我们请求的网站(提供数据的站点),要主动提供相应的内容(也就是要主动配合满足JSONP协定)。
HTML代码:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>JSONP</title> </head> <body> <input type="button" value="获取数据" onclick="get_data();"/> <script src="/static/js/jquery-1.12.4.js"></script> <script> function get_data(){ var tag = document.createElement('script'); tag.src = 'http://xxxx.com/data.html?callback=data_list&k1=v1'; // 将这个script标签加入到head标签中,加入后,浏览器马上就会从这个src去获取数据 document.head.appendChild(tag); // 获取了src的数据后,马上删除这个script标签 document.head.removeChild(tag); } </script> </body> </html>
我们可以看到,我们点击"获取数据"按钮的时候,触发get_data事件函数,然后在head标签中添加了一个script标签,浏览器帮我们请求了其中的数据(数据需要是能执行的JS代码),请求完后马上删除了标签。
这个请求让我们可以拿到合法的JS代码。这就需要让跨域网站将数据包含在合法的JS代码中。
我们观察一下<script>标签请求的URL,其中包含了一个GET参数callback=data_list,这个参数的值,要么跨域站点指定,要么我们任意传(要看跨域站点后台怎么处理)。
当跨域网站的后台获取到这个参数后,就可以使用以下方式来返回数据:
data_list(JSON数据);
将data_list作为函数名,将想要提供的数据(JSON格式的字符串)作为参数,然后返回。
此时,我们拿到的JS代码就是data_list(JSON数据)。这段代码的意思就是调用本地的data_list(arg)函数,如果我们本地有这个函数,则可以运行,并且能拿到这些参数(也就是想要获取的数据)。
实现本地data_list函数:
function data_list(arg){ // 打印拿到的参数(数据) console.log(arg) }
这样,跨域站点提供的JSON数据就通过这种方式到达了我们的浏览器。并打印在了console中。
总结:这种利用<script>标签请求JS代码来偷渡JSON的数据,称为JSONP。
3.利用jQuery发送JSONP(常用)
在2.中,我们使用的是手工添加删除<script>的形式来使用JSONP。
而利用jQuery的Ajax也可以发送JSONP:
function get_data(){ $.ajax({ url: 'http://xxxx.com/data.html?k1=v1', type: "POST", dataType: 'jsonp', jsonp:'callback', jsonpCallback:'data_list' }) }
通过jsonp和jsonpCallback两个参数,就相当于我们URL中的"callback=data_list"。
jQuery这种使用JSONP的方式,底层和前面我们手工添加删除<script>的方式是一样的。
五、CORS跨域资源共享
在第四节中,之所以我们要使用JSONP,是因为浏览器会阻止我们从跨域站点获取的数据。
但是如果跨域站点服务器直接在响应头中进行设置,允许我们的域名获取数据,那么浏览器就不会阻止了。
跨站服务器设置响应头:
set_header('Access-Control-Allow-Origin', "http://www.xxx.com")
http://www.xxx.com是我们的域名。
参照博客:
https://www.cnblogs.com/wupeiqi/articles/5703697.html
https://www.cnblogs.com/loveis715/p/4592246.html
六、XSS过滤
1.XSS问题
当用户在textarea框(例如kindeditor)中输入一些特殊的标签,例如<script>标签,则需要将其过滤掉。
def kind(request): if request.method == 'GET': return render(request, 'kind.html') if request.method == 'POST': content = request.POST.get("content") print(content) return HttpResponse(content)
我们从后台获取到kindeditor的内容(content)。
如果有人在kindeditor中输入以下内容:
这是恶意添加的代码:
<script>alert(123)</script>
kindeditor会自动帮我们转换为:

所以,我们在后台拿到数据其实是:<script>alert(123)</script>
但是,如果用户直接在源码编辑框中写入<script>标签,后台就能够收到未经处理的标签:

此时,如果将内容返回给页面显示,则会运行该<script>标签中的JS代码。如下图:

为了避免这种恶意操作的出现,我们需要将后台收到的数据进行防XSS攻击处理。
2.使用BeautifulSoup过滤标签
安装BeautifulSoup4:
pip3 install beautifulsoup4
使用beautifulsoup4:
def kind(request): if request.method == 'GET': return render(request, 'kind.html') if request.method == 'POST': content = request.POST.get("content") print(content) from bs4 import BeautifulSoup # 导入bs4 soup = BeautifulSoup(content, 'html.parser') # 将content解析成一个对象 tag = soup.find('script') # 从soup中查找<script>标签 print(tag) # 输出<script>alert(123)</script> tag.clear() # 将<script>标签的内容清除掉 content = soup.decode() # 重新将soup解码成字符串 print(content) # 输出<script></script> return HttpResponse(content)
从上述代码中可以看到,我们利用bs4将文本形式的html内容转换为对象soup。然后在利用find()方法找到对应的特殊恶意标签,然后使用clear()将其内容清空。最后重新转换为文本,返回给页面。
如果想将<script>彻底删除,可以使用tag.hidden = True:
tag = soup.find('script') # 从soup中查找<script>标签 print(tag) # 输出<script>alert(123)</script> tag.hidden = True # 将整个<script>标签删除掉 tag.clear()
bs4的其他用法
某个标签的属性:
span_tag = soup.find('span') print(span_tag.attrs) # 打印该标签的所有属性
删除其中一个属性:
span_tag = soup.find('span') print(span_tag.attrs) del span_tag.attrs['style'] # 删除style属性
3.利用bs4设置一个白名单
假设我们希望文本中能够生效的标签有<p><div><span><a>,而其他类似<script>标签都是危险标签。
则,我们可以设置一个白名单:
white_list = ["p", "div", "span", "a"]
然后使用bs4进行过滤,只保证白名单中的标签可用:
from bs4 import BeautifulSoup # 导入bs4 soup = BeautifulSoup(content, 'html.parser') # 将content解析成一个对象 tags = soup.find_all() for tag in tags: # 遍历所有的标签 if tag.name in white_list: # 如果标签名在白名单中,则什么都不做 pass else: # 如果不在白名单中,则删除标签及内容 tag.hidden = True # 删除标签 tag.clear() # 删除内容
以上这种白名单只能过滤标签,如果我们还想过滤标签的属性,则修改白名单:
white_list = {"p": ['class'],
"div": ['class', 'id'],
"span": ['class', 'id'],
"a": ['class', 'id', 'href']
}
然后我们在修改过滤部分的代码:
from bs4 import BeautifulSoup # 导入bs4 soup = BeautifulSoup(content, 'html.parser') # 将content解析成一个对象 tags = soup.find_all() for tag in tags: # 遍历所有的标签 if tag.name in white_list: # 如果标签名在白名单中,则什么都不做 print(tag.attrs) for k in list(tag.attrs.keys()): if k in white_list[tag.name]: pass else: del tag.attrs[k] else: # 如果不在白名单中,则删除标签及内容 tag.hidden = True # 删除标签 tag.clear() # 删除内容
4.将过滤功能封装成XSSFilter类
参考:https://www.cnblogs.com/lei0213/p/6434648.html
from bs4 import BeautifulSoup class XSSFilter(object): __instance = None def __init__(self): # XSS白名单 self.valid_tags = { "font": ['color', 'size', 'face', 'style'], 'b': [], 'div': [], "span": [], "table": [ 'border', 'cellspacing', 'cellpadding' ], 'th': [ 'colspan', 'rowspan' ], 'td': [ 'colspan', 'rowspan' ], "a": ['href', 'target', 'name'], "img": ['src', 'alt', 'title'], 'p': [ 'align' ], "pre": ['class'], "hr": ['class'], 'strong': [] } def __new__(cls, *args, **kwargs): """ 单例模式 :param cls: :param args: :param kwargs: :return: """ if not cls.__instance: obj = object.__new__(cls, *args, **kwargs) cls.__instance = obj return cls.__instance def process(self, content): soup = BeautifulSoup(content, 'html.parser') # 遍历所有HTML标签 for tag in soup.find_all(recursive=True): # 判断标签名是否在白名单中 if tag.name not in self.valid_tags: tag.hidden = True if tag.name not in ['html', 'body']: tag.hidden = True tag.clear() continue # 当前标签的所有属性白名单 attr_rules = self.valid_tags[tag.name] keys = list(tag.attrs.keys()) for key in keys: if key not in attr_rules: del tag[key] return soup.decode()
调用方式:
content = form.cleaned_data.pop('content') # 移出 content需要在表ArticleDetail上手动添加、关联Article content = XSSFilter().process(content) # 对content进行数据过滤 过滤到script等标签
七、单例模式
在第六节中,XSSFilter类使用了单例模式。
1.low版
class Foo(object): instance = None def __init__(self): pass @classmethod def get_instance(cls): if cls.instance: return cls.instance else: cls.instance = cls() return cls.instance def process(self): print("process") if __name__ == '__main__': obj1 = Foo.get_instance() obj2 = Foo.get_instance() print(id(obj1), id(obj2))
这个版本,我们要使用Foo.get_instance()来获得实例,对用户不友好。
2.高级版
class Foo(object): instance = None def __init__(self): pass def __new__(cls, *args, **kwargs): if cls.instance: return cls.instance else: cls.instance = object.__new__(cls, *args, **kwargs) return cls.instance def process(self): print("process") if __name__ == '__main__': obj1 = Foo() obj2 = Foo() print(id(obj1), id(obj2))
这个版本,换成了用Foo()来获取实例,和非单例模式是一样的方式,屏蔽了底层细节,对用户友好。
3.基于模块导入机制的单例模型(仅限于python)
核心概念:模块只被导入一次
当我们在导入一个模块时,python会编译生成一个pyc文件,这个文件会在模块的第一次导入时生成。
当pyc存在的时候,例如第二次导入模块,则不会在运行模块中的代码,而是直接使用内存中的pyc。
所以,利用这一特性,我们可以构建单例模型:
# mysingleton.py class MySingleton(object): def foo(self): print("foo...") my_singleton = MySingleton()
在mysingleton模块中,定义了MySingleton类,并获取了一个实例对象。
在另一个模块中,对mysingleton模块进行导入:
# other.py # 第一次导入my_singleton from mysingleton import my_singleton # 第二次导入my_singleton from mysingleton import my_singleton as my_singleton_2 print(id(my_singleton)) print(id(my_singleton_2))
输出结果是两个对象的id相同,即两个对象实际上是同一个对象。
这是因为第一次导入的my_singleton处于内存中,当第二次导入同样的模块时,发现内存中已经存在,则直接引用了内存中的my_singleton对象。
这样就实现了基于模块的单例模型。
≧◔◡◔≦