一、KD树
https://zhuanlan.zhihu.com/p/45346117
二、代码理解
2.1 首先定义KD树中的节点类
class Node(object):
def __init__(self):
"""Node class to build tree leaves.
"""
self.father = None
self.left = None
self.right = None
self.feature = None
self.split = None
def __str__(self):
return "feature: %s, split: %s" % (str(self.feature), str(self.split))
@property
def brother(self):
"""Find the node's brother.
Returns:
node -- Brother node.
"""
if not self.father:
ret = None
else:
if self.father.left is self:
ret = self.father.right
else:
ret = self.father.left
return ret
1、每个节点,有如下属性:
父节点,左子树,右子树,用于切分的特征,切分点。
2、str,打印树节点的时候返回特征和切分点。
3、节点的兄弟节点
2.2 KD树类
class KDTree(object):
def __init__(self):
"""KD Tree class to improve search efficiency in KNN.
Attributes:
root: the root node of KDTree.
"""
self.root = Node()
def __str__(self):
"""Show the relationship of each node in the KD Tree.
Returns:
str -- KDTree Nodes information.
"""
ret = []
i = 0
que = [(self.root, -1)]
while que:
nd, idx_father = que.pop(0)
ret.append("%d -> %d: %s" % (idx_father, i, str(nd)))
if nd.left:
que.append((nd.left, i))
if nd.right:
que.append((nd.right, i))
i += 1
return "
".join(ret)
打印KDtree的时候的展示样式。
2.3 生成KDTree
def build_tree(self, X, y):
"""Build a KD Tree. The data should be scaled so as to calculate variances.
Arguments:
X {list} -- 2d list object with int or float.
y {list} -- 1d list object with int or float.
"""
# 初始化根节点,所有样本的索引,一个que作为临时变量保存当前需要处理的节点。
nd = self.root
idxs = range(len(X))
que = [(nd, idxs)]
while que:
nd, idxs = que.pop(0) # 为当前节点的各个属性赋值,其属性值通过后续计算得到。
n = len(idxs) # 此次循环要处理的样本总数。当只有一个样本的时候,就不用再分了。
# Stop split if there is only one element in this node
if n == 1:
nd.split = (X[idxs[0]], y[idxs[0]])
continue
# Split
feature = self._choose_feature(X, idxs) # 输入样本X和其索引idxs,返回0或者1,因为是二维特征,表示对哪个维度进行分割。
median_idx = self._get_median_idx(X, idxs, feature) # 返回需要切分的列中的中值的索引。
idxs_left, idxs_right = self._split_feature(
X, idxs, feature, median_idx) # 根据切分维度和索引把x分为两组,小于阈值的为左子树,大于等于阈值的为右子树。[[左子树索引组成的列表], [右子树索引组成的列表]]。
# 所有属性都get之后,进行赋值更新当前节点。
nd.feature = feature
nd.split = (X[median_idx], y[median_idx]) # 根据哪个值进行切分。
# Put children of current node in que 确定其左右子节点。即把一个空节点的父节点设为该节点。
if idxs_left != []:
nd.left = Node()
nd.left.father = nd
que.append((nd.left, idxs_left)) # 下次循环左节点,把该节点,和左子树索引列表保存到临时列表que中。相当于深度优先遍历。
if idxs_right != []:
nd.right = Node()
nd.right.father = nd
que.append((nd.right, idxs_right))
最好KDTree保存了所有节点的信息。
2.4搜索函数
搜索KD Tree中与目标元素距离最近的节点,使用广度优先搜索来实现。
- 从根节点开始,根据目标在分割特征中是否小于或大于当前节点,向左或向右移动。
- 一旦算法到达叶节点,它就将该叶子节点保存为“当前最佳”。
- 回溯,即从叶节点再返回到根节点
- 如果当前节点比当前最佳节点更接近,那么它就成为当前最好的。
- 如果目标距离当前节点的父节点所在的将数据集分割为两份的超平面的距离更接近,说明当前节点的兄弟节点所在的子树有可能包含更近的点。因此需要对这个兄弟节点递归执行1-4步。
def nearest_neighbour_search(self, Xi):
"""Nearest neighbour search and backtracking.
Arguments:
Xi {list} -- 1d list with int or float. 需要查找的目标值。
Returns:
node -- The nearest node to Xi.
"""
# The leaf node after searching Xi.
dist_best = float("inf") # 首先定义一个无穷大的距离。
nd_best = self._search(Xi, self.root) # 从根节点开始,找到“当前最佳”叶子节点。即1,2。
que = [(self.root, nd_best)] # 同样一个临时列表变量保存信息
while que:
nd_root, nd_cur = que.pop(0)
# 计算目标值xi和根节点的距离
dist = self._get_eu_dist(Xi, nd_root)
# Update best node and distance.
if dist < dist_best:
dist_best, nd_best = dist, nd_root # 更新当前最小距离,根节点为最合适节点。
while nd_cur is not nd_root: # 如果当前节点不是根节点
# Calculate distance between Xi and current node
dist = self._get_eu_dist(Xi, nd_cur) # 计算目标值xi和当前节点的距离。
# Update best node, distance and visit flag.
if dist < dist_best:
dist_best, nd_best = dist, nd_cur
# If it's necessary to visit brother node.
if nd_cur.brother and dist_best > self._get_hyper_plane_dist(Xi, nd_cur.father): # 计算目标值和当前节点的父节点所在的将数据集分割为两份的超平面的距离
_nd_best = self._search(Xi, nd_cur.brother) # 从其兄弟节点找到最小距离节点。
que.append((nd_cur.brother, _nd_best))
# Back track.
nd_cur = nd_cur.father # 找到当钱节点的父节点,继续计算距离。
return nd_best # 最终返回和目标值xi距离最小的节点
三、第三章习题
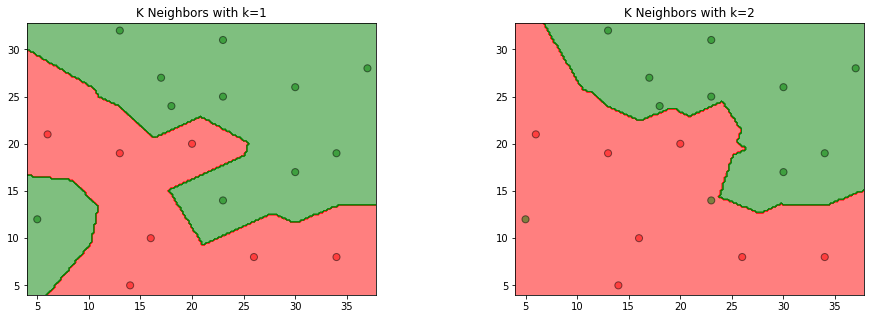
3.1 参照图3.1,在二维空间中给出实例点,画出kk为1和2时的k近邻法构成的空间划分,并对其进行比较,体会k值选择与模型复杂度及预测准确率的关系。
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
data = np.array([[5, 12, 1],
[6, 21, 0],
[14, 5, 0],
[16, 10, 0],
[13, 19, 0],
[13, 32, 1],
[17, 27, 1],
[18, 24, 1],
[20, 20, 0],
[23, 14, 1],
[23, 25, 1],
[23, 31, 1],
[26, 8, 0],
[30, 17, 1],
[30, 26, 1],
[34, 8, 0],
[34, 19, 1],
[37, 28, 1]])
X_train = data[:, 0:2]
y_train = data[:, 2]
models = (KNeighborsClassifier(n_neighbors=1, n_jobs=-1),
KNeighborsClassifier(n_neighbors=2, n_jobs=-1)) # 在训练集中找到与该实例最邻近的k个实例
models = (clf.fit(X_train, y_train) for clf in models)
titles = ('K Neighbors with k=1',
'K Neighbors with k=2')
fig = plt.figure(figsize=(15, 5))
plt.subplots_adjust(wspace=0.4, hspace=0.4) # 为子图之间的空间保留的宽度和高度。
X0, X1 = X_train[:, 0], X_train[:, 1]
x_min, x_max = X0.min() - 1, X0.max() + 1
y_min, y_max = X1.min() - 1, X1.max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.2),
np.arange(y_min, y_max, 0.2)) # 生成网格采样点
for clf, title, ax in zip(models, titles, fig.subplots(1, 2).flatten()):
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
colors = ('red', 'green', 'lightgreen', 'gray', 'cyan')
cmap = ListedColormap(colors[:len(np.unique(Z))]) # 选择颜色
ax.contourf(xx, yy, Z, cmap=cmap, alpha=0.5) # 轮廓填充
ax.scatter(X0, X1, c=y_train, s=50, edgecolors='k', cmap=cmap, alpha=0.5) # 散点图
ax.set_title(title)
plt.show()
3.2 利用例题3.2构造的kd树求点(x=(3,4.5)^T) 的最近邻点。
import numpy as np
from sklearn.neighbors import KDTree
train_data = np.array([(2, 3), (5, 4), (9, 6), (4, 7), (8, 1), (7, 2)])
tree = KDTree(train_data, leaf_size=2)
dist, ind = tree.query(np.array([(3, 4.5)]), k=1)
x1 = train_data[ind[0]][0][0]
x2 = train_data[ind[0]][0][1]
print("x点的最近邻点是({0}, {1})".format(x1, x2))
3.3 参照算法3.3,写出输出为(x)的(k)近邻的算法
解答:
算法:用kd树的kk近邻搜索
输入:已构造的kd树;目标点(x);
输出:(x)的最近邻
- 在kdkd树中找出包含目标点xx的叶结点:从根结点出发,递归地向下访问树。若目标点xx当前维的坐标小于切分点的坐标,则移动到左子结点,否则移动到右子结点,直到子结点为叶结点为止;
- 如果“当前kk近邻点集”元素数量小于kk或者叶节点距离小于“当前kk近邻点集”中最远点距离,那么将叶节点插入“当前k近邻点集”;
- 递归地向上回退,在每个结点进行以下操作:
(a)如果“当前kk近邻点集”元素数量小于kk或者当前节点距离小于“当前kk近邻点集”中最远点距离,那么将该节点插入“当前kk近邻点集”。
(b)检查另一子结点对应的区域是否与以目标点为球心、以目标点与于“当前kk近邻点集”中最远点间的距离为半径的超球体相交。如果相交,可能在另一个子结点对应的区域内存在距目标点更近的点,移动到另一个子结点,接着,递归地进行最近邻搜索;如果不相交,向上回退; - 当回退到根结点时,搜索结束,最后的“当前kk近邻点集”即为xx的最近邻点。
# 构建kd树,搜索待预测点所属区域
from collections import namedtuple
import numpy as np
# 建立节点类
class Node(namedtuple("Node", "location left_child right_child")):
def __repr__(self):
return str(tuple(self))
# kd tree类
class KdTree():
def __init__(self, k=1):
self.k = k
self.kdtree = None
# 构建kd tree
def _fit(self, X, depth=0):
try:
k = self.k
except IndexError as e:
return None
# 这里可以展开,通过方差选择axis
axis = depth % k
X = X[X[:, axis].argsort()]
median = X.shape[0] // 2
try:
X[median]
except IndexError:
return None
return Node(
location=X[median],
left_child=self._fit(X[:median], depth + 1),
right_child=self._fit(X[median + 1:], depth + 1)
)
def _search(self, point, tree=None, depth=0, best=None):
if tree is None:
return best
k = self.k
# 更新 branch
if point[0][depth % k] < tree.location[depth % k]:
next_branch = tree.left_child
else:
next_branch = tree.right_child
if not next_branch is None:
best = next_branch.location
return self._search(point, tree=next_branch, depth=depth + 1, best=best)
def fit(self, X):
self.kdtree = self._fit(X)
return self.kdtree
def predict(self, X):
res = self._search(X, self.kdtree)
return res
KNN = KdTree()
X_train = np.array([[2, 3],
[5, 4],
[9, 6],
[4, 7],
[8, 1],
[7, 2]])
KNN.fit(X_train)
X_new = np.array([[3, 4.5]])
res = KNN.predict(X_new)
x1 = res[0]
x2 = res[1]
print("x点的最近邻点是({0}, {1})".format(x1, x2))