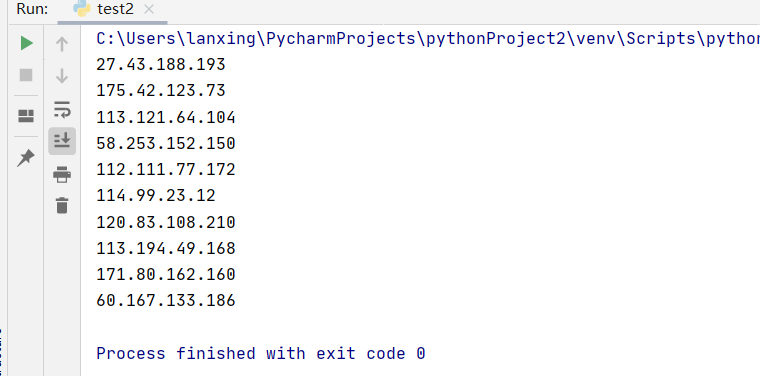
最近在学习python爬虫,找到一个有趣的xpath库,记录一下啊
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
| 路径表达式 | 结果 |
|---|---|
| bookstore | 选取 bookstore 元素的所有子节点。 |
| /bookstore |
选取根元素 bookstore。 注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素。 |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置。 |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 |
| //@lang | 选取名为 lang 的所有属性。 |
需求,我要爬一下啊这个网站的免费代理ip,又想来点简单爬虫。嗯

找到ip,定位一下,复制xpath路径
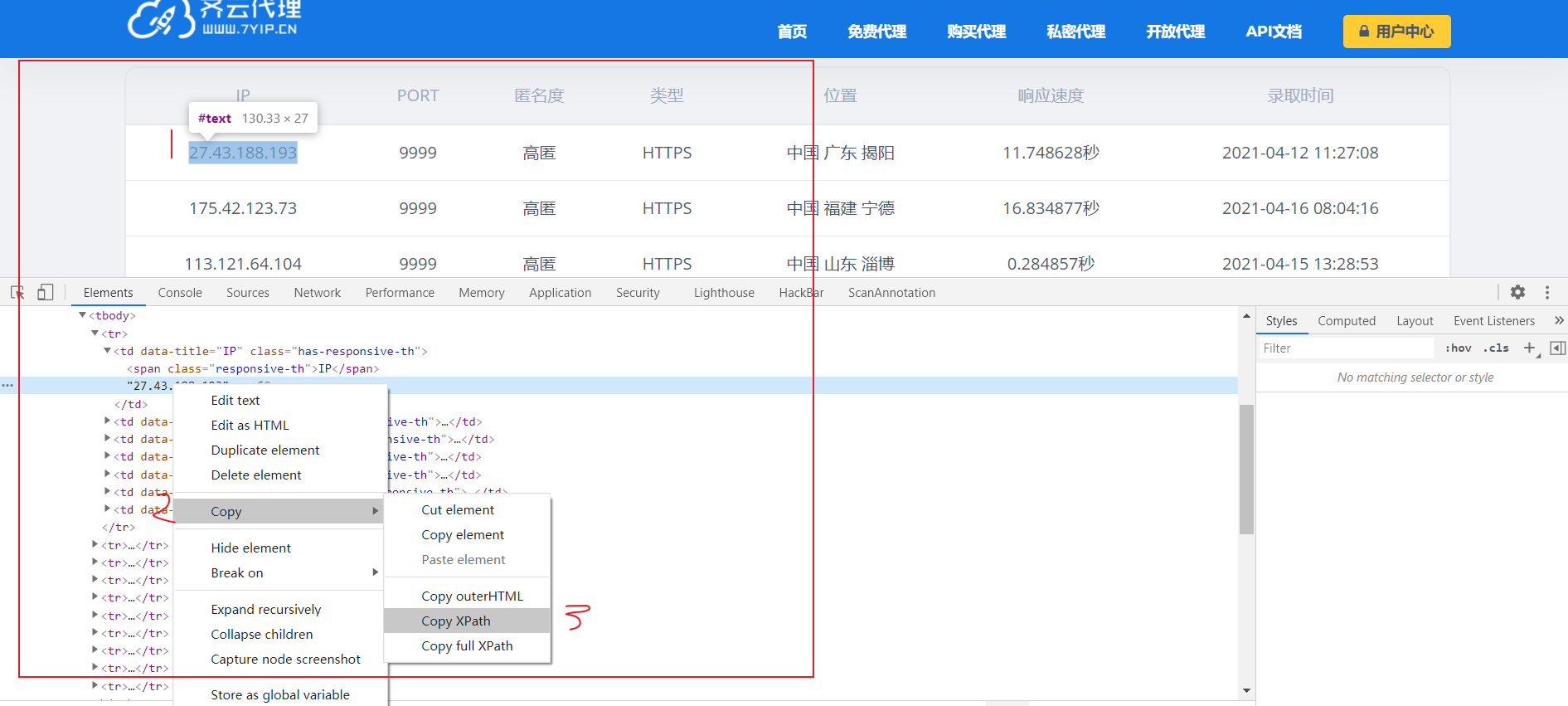
到google插件xpath插件,可以提取到ip

根据规则,提取这页ip可以这样写
//*[@id="content"]/section/div[2]/table/tbody/tr/td[1]/text()

1 import requests 2 from lxml import html 3 etree = html.etree 4 5 headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:87.0) Gecko/20100101 Firefox/87.0'} 6 7 url = 'https://www.7yip.cn/free/?action=china&page=1' 8 html = requests.get(url,headers=headers,timeout=10) 9 xhtml = etree.HTML(html.content.decode('utf-8')) #解析网页 10 node = xhtml.xpath('//*[@id="content"]/section/div[2]/table/tbody/tr/td[1]/text()') #填入要获取的xapth地址 11 #把表里面的ip排序一下 12 for i in node: 13 print(i) 14