俗话说,自己写的代码,6个月后也是别人的代码……复习!复习!复习!涉及到的知识点总结如下:
- 一些JVM的跟踪参数的设置
- Java堆的分配参数
-
-Xmx 和 –Xms 应该保持一个什么关系,可以让系统的性能尽可能的好呢?是不是虚拟机内存越大越好?
- Java 7之前和Java 8的堆内存结构
- Java栈的分配参数
- GC算法思想介绍
–GC ROOT可达性算法–标记清除–标记压缩–复制算法
- 可触及性含义和在Java中的体现
- finalize方法理解
- Java的强引用,软引用,弱引用,虚引用
- GC引起的Stop-The-World现象
- 串行收集器
- 并行收集器
- CMS
记得JVM学习1里总结了一个例子,就是使用 -XX:+printGC参数来使能JVM的GC日志打印,让程序员可以追踪GC的踪迹。如例子:


1 public class OnStackTest { 2 /** 3 * alloc方法内分配了两个字节的内存空间 4 */ 5 public static void alloc(){ 6 byte[] b = new byte[2]; 7 b[0] = 1; 8 } 9 10 public static void main(String[] args) { 11 long b = System.currentTimeMillis(); 12 13 // 分配 100000000 个 alloc 分配的内存空间 14 for(int i = 0; i < 100000000; i++){ 15 alloc(); 16 } 17 18 long e = System.currentTimeMillis(); 19 System.out.println(e - b); 20 } 21 }
配置参数-XX:+printGC,再次运行会打印GC日志,截取一句:
[GC (Allocation Failure) 4416K->716K(15872K), 0.0018384 secs]
代表发生了GC,花费了多长时间,效果是GC之前为4M多,GC之后为716K,回收了将近4M内存空间,而堆的大小大约是16M(默认的)。
如果还嫌这些信息不够,JVM还提供了打印详细GC日志的参数:-XX:+PrintGCDetails
[GC (Allocation Failure) [DefNew: 4480K->0K(4992K), 0.0001689 secs] 5209K->729K(15936K), 0.0001916 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
会详细显示堆的各个代的GC信息,还详细的给出了耗时信息:user代表用户态cpu耗时,sys代表系统的cpu耗时,real代表实际经历时间。除此之外,-XX:+PrintGCDetails,还会在JVM退出前打印堆的详细信息:
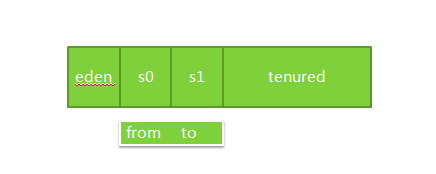
Heap def new generation total 4992K, used 4301K [0x03800000, 0x03d60000, 0x08d50000) eden space 4480K, 96% used [0x03800000, 0x03c33568, 0x03c60000) from space 512K, 0% used [0x03ce0000, 0x03ce0000, 0x03d60000) to space 512K, 0% used [0x03c60000, 0x03c60000, 0x03ce0000) tenured generation total 10944K, used 729K [0x08d50000, 0x09800000, 0x13800000) the space 10944K, 6% used [0x08d50000, 0x08e06700, 0x08e06800, 0x09800000) Metaspace used 103K, capacity 2248K, committed 2368K, reserved 4480K
def new generation total 4992K, used 3226K [0x03800000, 0x03d60000, 0x08d50000)
在对象出生的地方,也就是伊甸园,有4M空间,使用了72%
eden space 4480K, 72% used [0x03800000, 0x03b26830, 0x03c60000)
还有幸存代,from和to,他俩一定是相等的。
from space 512K, 0% used [0x03ce0000, 0x03ce0000, 0x03d60000)
to space 512K, 0% used [0x03c60000, 0x03c60000, 0x03ce0000)
最后还有一个老年代空间,总共有10M,使用了729K
tenured generation total 10944K, used 729K [0x08d50000, 0x09800000, 0x13800000)
最后是Java 8改进之后的元数据空间,其中还有些16进制数字,比如[0x08d50000, 0x09800000, 0x13800000),意思依次是低边界,当前边界,最高边界,代表内存分配的初始位置,当前分配到的位置,和最终能分配到的位置。
重定向GC日志的方法
{Heap before GC invocations=0 (full 0):
def new generation total 4928K, used 4416K [0x03c00000, 0x04150000, 0x09150000)
eden space 4416K, 100% used [0x03c00000, 0x04050000, 0x04050000)
from space 512K, 0% used [0x04050000, 0x04050000, 0x040d0000)
to space 512K, 0% used [0x040d0000, 0x040d0000, 0x04150000)
tenured generation total 10944K, used 0K [0x09150000, 0x09c00000, 0x13c00000)
the space 10944K, 0% used [0x09150000, 0x09150000, 0x09150200, 0x09c00000)
Metaspace used 1915K, capacity 2248K, committed 2368K, reserved 4480K
Heap after GC invocations=1 (full 0):
def new generation total 4928K, used 512K [0x03c00000, 0x04150000, 0x09150000)
eden space 4416K, 0% used [0x03c00000, 0x03c00000, 0x04050000)
from space 512K, 100% used [0x040d0000, 0x04150000, 0x04150000)
to space 512K, 0% used [0x04050000, 0x04050000, 0x040d0000)
tenured generation total 10944K, used 202K [0x09150000, 0x09c00000, 0x13c00000)
the space 10944K, 1% used [0x09150000, 0x09182950, 0x09182a00, 0x09c00000)
Metaspace used 1915K, capacity 2248K, committed 2368K, reserved 4480K
}
监控Java类的加载情况: -XX:+TraceClassLoading
监控系统中每一个类的加载,每一行代表一个类,主要用于跟踪调试程序。
监控类的使用情况:-XX:+PrintClassHistogram
在程序运行中,按下Ctrl+Break后,打印类的信息:截取发现程序使用了大量的hashmap:
num #instances #bytes class name ---------------------------------------------- 1: 2919 400528 [C 2: 173 77072 [B 3: 593 58016 java.lang.Class 4: 2552 40832 java.lang.String 5: 638 36280 [Ljava.lang.Object; 6: 827 26464 java.util.TreeMap$Entry
分别显示序号(按照空间占用大小排序)、实例数量、总大小、类型
下面看看Java堆的分配参数,指定最大堆和最小堆 -Xmx –Xms
-Xms 10m,表示JVM Heap(堆内存)最小尺寸10MB,最开始只有 -Xms 的参数,表示 `初始` memory size(m表示memory,s表示size),属于初始分配10m,-Xms表示的 `初始` 内存也有一个 `最小` 内存的概念(其实常用的做法中初始内存采用的也就是最小内存)。
-Xmx 10m,表示JVM Heap(堆内存)最大允许的尺寸10MB,按需分配。如果 -Xmx 不指定或者指定偏小,也许出现java.lang.OutOfMemory错误,此错误来自JVM不是Throwable的,无法用try...catch捕捉。
看下对JVM设置:-Xmx20m -Xms5m
public class OnStackTest { /** * alloc方法内分配了两个字节的内存空间 */ public static void alloc(){ byte[] b = new byte[10]; b[0] = 1; } public static void main(String[] args) { long b = System.currentTimeMillis(); // 分配 100000000 个 alloc 分配的内存空间 for(int i = 0; i < 100000000; i++){ alloc(); } System.out.print("Xmx ="); System.out.println(Runtime.getRuntime().maxMemory() / 1024.0 / 1024 + "M"); System.out.print("free mem ="); System.out.println(Runtime.getRuntime().freeMemory() / 1024.0 / 1024 + "M"); System.out.print("total mem ="); System.out.println(Runtime.getRuntime().totalMemory() / 1024.0 / 1024 + "M"); long e = System.currentTimeMillis(); System.out.println(e - b); } }
Xmx =19.375M
free mem =4.21685791015625M
total mem =5.875M
1032
记住:Java会尽量的维持在最小堆运行,即使设置的最大值很大,只有当GC之后也无法满足最小堆,才会去扩容。
-Xmx 和 –Xms 应该保持一个什么关系,可以让系统的性能尽可能的好呢?是不是虚拟机内存越大越好?
占坑,后续的GC机制来补充回答这个问题。首先并不是虚拟机内存越大就越好,大概原因是因为:内存越大,JVM 进行 Full GC 所需的时间越久,由于 Full GC 时 stop whole world 特性,如果是用于响应HTTP 请求的服务器,这个时候就表现为停止响应,对于需要低延迟的应用来说,这是不可接受的。对于需要高吞吐量的应用来说,可以不在乎这种停顿,比如一些后台的应用之类的,那么内存可以适当调大一些。需要根据具体情况权衡。
设置新生代大小,-Xmn参数,设置的是绝对值,30m就是30m,10m就是10m。还有一个参数 -XX:NewRatio,看名字就知道是按照比例来设置,意思是设置新生代(eden+2*s)和老年代(不包含永久区)的比值,比如-XX:NewRatio4 表示 新生代:老年代=1:4。
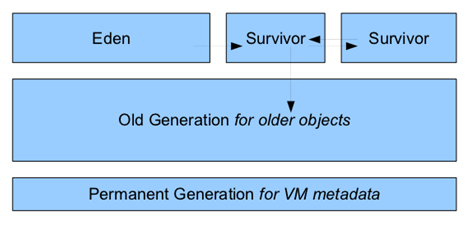
- 根据实际事情调整新生代和幸存代的大小
- 官方推荐新生代占堆的3/8
- 幸存代占新生代的1/10
- 在OOM时,记得Dump出堆,确保可以排查现场问题
- 性能,每次引用和去引用都要加减
- 循环引用问题
- 静态变量引用的对象
- 常量引用的对象
- 本地方法栈(JNI)引用的对象
- Java栈中引用的对象

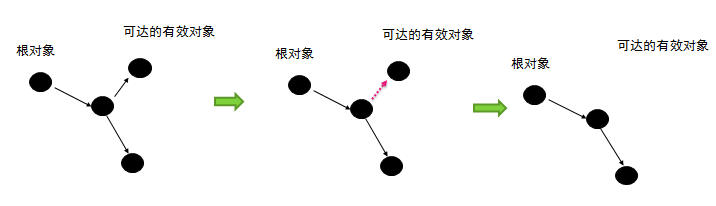
- 可触及的–从GC ROOT这个根节点对象,沿着引用的链条,可以触及到这个对象,该对象就叫可触及的,也就是之前说的可达性算法的思想。
- 可复活的–一旦所有引用被释放,就是可复活状态,因为在finalize()中可能复活该对象(finalize方法只会调用一次)。
- 不可触及的–在finalize()后,可能会进入不可触及状态,不可触及的对象不可能复活,就可以回收了。
GC准备释放内存的时候,会先调用finalize()。而调用了这个方法不代表对象一定会被回收。因为GC和finalize() 都是靠不住的,只要JVM还没有快到耗尽内存的地步,它是不会浪费时间进行垃圾回收的。
finalize()在什么时候被调用?
有三种情况
- 所有对象被Garbage Collection时自动调用,比如运行System.gc()的时候。
- 程序退出时为每个对象调用一次finalize方法。
- 显式的调用finalize方法。
finalize 是Object的 protected 方法,子类可以覆盖该方法以实现资源清理工作,GC在回收对象之前调用该方法。finalize与C++中的析构函数不是对应的。C++中的析构函数调用的时机是确定的(对象离开作用域或delete掉),但Java中的finalize的调用具有不确定性。
不建议用finalize方法完成“非内存资源”的清理工作,因为Java语言规范并不保证finalize方法会被及时地执行、而且根本不会保证它们会被执行,而且 finalize 方法可能会带来性能问题。因为JVM通常在单独的低优先级线程中完成finalize的执行,finalize方法中,可将待回收对象赋值给GC Roots可达的对象引用,从而达到对象再生的目的。finalize方法至多由GC执行一次(用户当然可以手动调用对象的finalize方法,但并不影响GC对finalize的行为)
但建议用于:
- 清理本地对象(通过JNI创建的对象);
- 作为确保某些非内存资源(如Socket、文件等)释放的一个补充:在finalize方法中显式调用其他资源释放方法。
- 强引用:类似我们常见的,比如 A a = new A();a就叫强引用。任何被强引用指向的对象都不能GC,这些对象都是在程序中需要的。
- 软引用:使用java.lang.ref.SoftReference类来表示,软引用可以很好的用来实现缓存,当JVM需要内存时,垃圾回收器就会回收这些只有被软引用指向的对象。如下:
Counter prime = new Counter(); SoftReference soft = new SoftReference(prime) ; //soft reference prime = null;
强引用置空之后,代码的第二行为对象Counter创建了一个软引用,该引用同样不能阻止垃圾回收器回收对象,但是可以延迟回收,软引用更适用于缓存机制,而弱引用更适用于存贮元数据。
- 弱引用:使用java.lang.ref.WeakReference 类来表示,弱引用非常适合存储元数据,例如:存储ClassLoader引用。如果没有类被加载,那么也没有指向ClassLoader的引用。一旦上一次的强引用被去除,只有弱引用的ClassLoader就会被回收。也就是说如果一个对象只有弱引用指向它,GC会立即回收该对象,这是一种急切回收方式。如:
Counter counter = new Counter(); // strong reference WeakReference<Counter> weakCounter = newWeakReference<Counter>(counter); //weak reference counter = null;
只要给强引用对象counter赋null,该对象就可以被垃圾回收器回收。因为该对象不再含有其他强引用,即使指向该对象的弱引用weakCounter也无法阻止垃圾回收器对该对象的回收。相反的,如果该对象含有软引用,Counter对象不会立即被回收,除非JVM需要内存。
另一个使用弱引用的例子是WeakHashMap,它是除HashMap和TreeMap之外,Map接口的另一种实现。WeakHashMap有一个特点:map中的键值(keys)都被封装成弱引用,也就是说一旦强引用被删除,WeakHashMap内部的弱引用就无法阻止该对象被垃圾回收器回收。
- 虚引用:没什么实际用处,就是一个标志,当GC的时候好知道。拥有虚引用的对象可以在任何时候GC。
ReferenceQueue refQueue = new ReferenceQueue(); DigitalCounter digit = new DigitalCounter(); PhantomReference<DigitalCounter> phantom = new PhantomReference<DigitalCounter>(digit, refQueue);
引用实例被添加在引用队列中,可以在任何时候通过查询引用队列回收对象。
现在我对一个对象的生命周期进行描述:
package wys.demo1; public class Demo1 { public static Demo1 obj; @Override protected void finalize() throws Throwable { super.finalize(); System.out.println("CanReliveObj finalize called"); obj = this;// 把obj复活了!!! } @Override public String toString(){ return "I am CanReliveObj"; } public static void main(String[] args) throws InterruptedException{ obj = new Demo1();// 强引用 obj = null; //不会被立即回收,是可复活的对象 System.gc();// 主动建议JVM做一次GC,GC之前会调用finalize方法,而我在里面把obj复活了!!! Thread.sleep(1000); if(obj == null){ System.out.println("obj 是 null"); }else{ System.out.println("obj 可用"); } System.out.println("第二次gc"); obj = null; //不可复活 System.gc(); Thread.sleep(1000); if(obj == null){ System.out.println("obj 是 null"); }else{ System.out.println("obj 可用"); } } }
结果:
CanReliveObj finalize called
obj 可用
第二次gc
obj 是 null
说明JVM不管程序员手动调用finalize,JVM它就是执行一次finalize方法。执行finalize方法完毕后,GC会再次进行二轮回收,去判断该对象是否可达,若不可达,才进行回收。
建议:避免使用finalize方法!
太复杂了,还是让系统照管比较好。可以定义其它的方法来释放非内存资源。建议使用try-catch-finally来替代它执行清理操作。
如果手动调用了finalize,很容易出错。且它执行的优先级低,何时被调用,不确定——也就是何时发生GC不确定,因为只有当内存告急时,GC才工作,即使GC工作,finalize方法也不一定得到执行,这是由于程序中的其他线程的优先级远远高于执行finalize()的线程优先级。 因此当finalize还没有被执行时,系统的其他资源,比如文件句柄、数据库连接池等已经消耗殆尽,造成系统崩溃。且垃圾回收和finalize方法的执行本身就是对系统资源的消耗,有可能造成程序的暂时停止,因此在程序中尽量避免使用finalize方法。
- Dump线程
- JVM的死锁检查
- 堆的Dump。
先不说了,先看看JVM的垃圾回收器吧,先看一种最古老的收集器——串行收集器
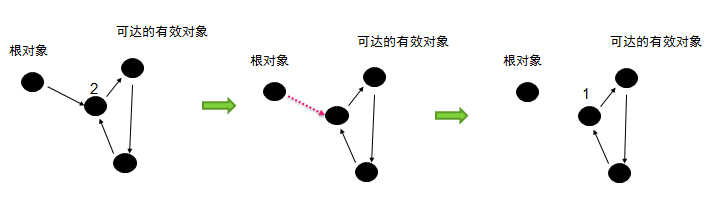
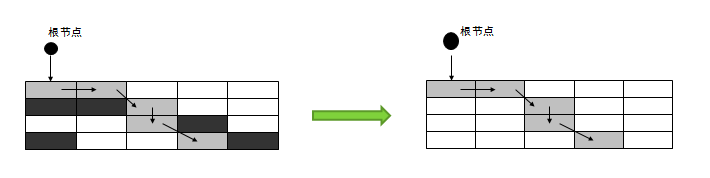
最古老,最稳定,效率高,但是串行的最大问题就是停顿时间很长!因为串行收集器只使用一个线程去回收,可能会产生较长的停顿现象。我们可以使用参数-XX:+UseSerialGC,设置新生代、老年代使用串行回收,此时新生代使用复制算法,老年代使用标记-压缩算法(标记-压缩算法首先需要从根节点开始,对所有可达对象做一次标记。但之后,它并不简单的清理未标记的对象,而是将所有的存活对象压缩到内存的一端。之后,清理边界外所有的空间。有效解决内存碎片问题)。
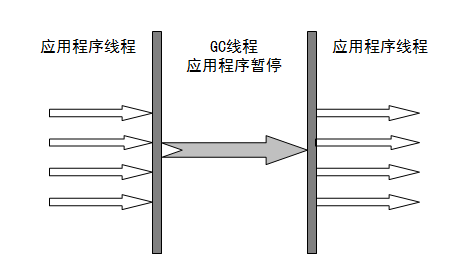
因为串行收集器只使用一个线程去回收,可能会产生较长的停顿现象。
还有一种收集器叫并行收集器(两种并行收集器)
- 一种是ParNew并行收集器。使用JVM参数设置XX:+UseParNewGC,设置之后,那么新生代就是并行回收,而老年代依然是串行回收,也就是并行回收器不会影响老年代,它是Serial收集器在新生代的并行版本,新生代并行依然使用复制算法,但是是多线程,需要多核支持,我们可以使用JVM参数: XX:ParallelGCThreads 去限制线程的数量。如图:
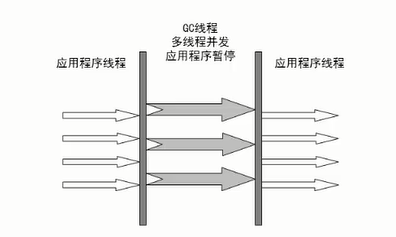
注意:新生代的多线程回收不一定快!看在多核还是单核,和具体环境。、
- 还有一种是Parallel收集器,它类似ParNew,但是更加关注JVM的吞吐量!同样是在新生代复制算法,老年代使用标记压缩算法,可以使用JVM参数XX:+UseParallelGC设置使用Parallel并行收集器+ 老年代串行,或者使用XX:+UseParallelOldGC,使用Parallel并行收集器+ 并行老年代。也就是说,Parallel收集器可以同时让新生代和老年代都并行收集。如图:
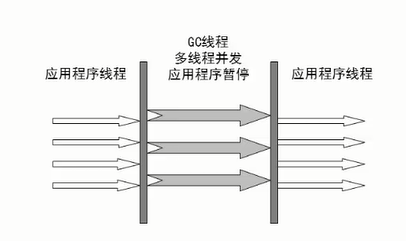
最后看一个很重要的收集器-CMS(并发标记清除收集器Concurrent Mark Sweep)收集器
顾名思义,它在老年代使用的是标记清除算法,而不是标记压缩算法,也就是说CMS是老年代收集器(新生代使用ParNew),所谓并发标记清除就是CMS与用户线程一起执行。标记-清除算法与标记-压缩相比,并发阶段会降低吞吐量,使用参数-XX:+UseConcMarkSweepGC打开。
CMS运行过程比较复杂,着重实现了标记的过程,可分为:
- 初始标记,标记GC ROOT 根可以直接关联到的对象(会产生全局停顿),但是初始标记速度快。
- 并发标记(和用户线程一起),主要的标记过程,标记了系统的全部的对象(不论垃圾不垃圾)。
- 重新标记,由于并发标记时,用户线程依然运行(可能产生新的对象),因此在正式清理前,再做一次修正,会产生全局停顿。
- 并发清除(和用户线程一起),基于标记结果,直接清理对象。这也是为什么使用标记清除算法的原因,因为清理对象的时候用户线程还能执行!标记压缩算法的压缩过程涉及到内存块移动,这样会有冲突。
- 并发重置,为下一次GC做准备工作。

- 在用户线程运行过程中,分一半CPU去做GC,系统性能在GC阶段,反应速度就下降一半。
- 清理不彻底。因为在清理阶段,用户线程还在运行,会产生新的垃圾,无法清理。
- 因为和用户线程基本上是一起运行的,故不能在空间快满时再清理。
可以使用-XX:CMSInitiatingOccupancyFraction设置触发CMS GC的阈值,设置空间内存占用到多少时,去触发GC,如果不幸内存预留空间不够,就会引起concurrent mode failure。
可以使用-XX:+ UseCMSCompactAtFullCollection, Full GC后,进行一次整理,而整理过程是独占的,会引起停顿时间变长。
从三个方面考虑:
- 软件如何设计架构
- 代码如何写
- 堆空间如何分配
欢迎关注
dashuai的博客是终身学习践行者,大厂程序员,且专注于工作经验、学习笔记的分享和日常吐槽,包括但不限于互联网行业,附带分享一些PDF电子书,资料,帮忙内推,欢迎拍砖!
