spark是一个高性能的并发的计算平台,而netflow是一种一般来说数量级很大的数据。本文记录初步使用spark 计算netflow数据的大致过程。
本文包括以下过程:
1. spark环境的搭建
2. netflow数据的生成与处理
3. 通过spark 计算netflow数据
spark环境的搭建
spark环境的搭建主要分2部分。
- hadoop的环境的搭建
- spark的安装
hadoop的安装
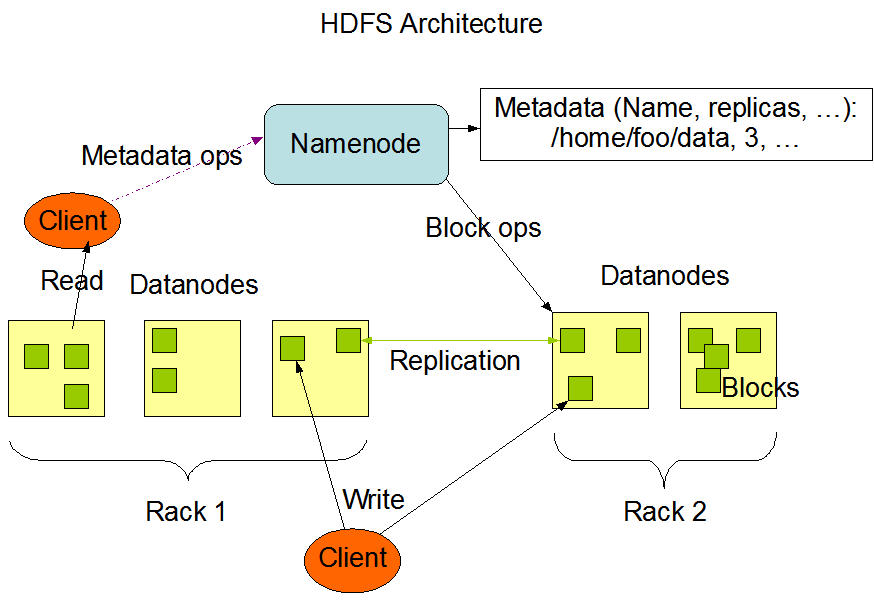
hadoop的安装包括,hdfs的安装和yarn的安装。 读本部分之前要先去查阅hdfs和yarn的概念。hdfs是hadoop的分布式文件系统。hdfs的架构为master/slave架构。cluster中有一个唯一的NameNode(master节点),剩下的节点为DataNodes(slave 节点),通常有多个。 hdfs把文件分成多个block,这些block存储在不同的DataNode上。NameNode负责执行对文件进行open,close,rename file&&directory 操作,也负责维护block和DataNode之间的map关系。DataNode则负责block级别 create delete read replication 等操作。 整个架构如下图所示:
YARN全称是yet another resource manager。 由于hadoop是一个分布式的架构,所以需要一个统一的资源管理器来调度分配各种资源。
spark的安装
如下
netflow数据的生成与处理
netflow是路由器设备在激活了netflow feature后生产的一些统计数据,这些数据会发给收集器如pmacct。 数据转换成csv格式大概如下:
TAG,IN_IFACE,OUT_IFACE,SRC_IP,DST_IP,SRC_PORT,DST_PORT,PROTOCOL,ip_dscp,flow_direction,PACKETS,BYTES 10001,1,1,42.120.83.100,42.120.85.157,12995,18193,ipv6-crypt,16,0,5,2042 10001,1,1,42.120.83.246,42.120.87.145,12517,19733,ospf,10,1,6,2294 10001,1,1,42.120.87.154,42.120.86.250,18757,11987,ipv6-auth,22,1,3,3236
具体请了解netflow。
这里说的处理是指做两件事:
1. 去掉第一行的TAG
2. 加入 timestamp 列
3. 把文件放入HDFS
通过spark 计算netflow数据
这里用spark计算我们需要的数据。