什么是Kafka
1.Apache Kafka是一个开源消息系统,由Scala写成。
2.Kafka是一个分布式消息队列。Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)称为broker。
3.无论是kafka集群,还是consumer都依赖于zookeeper集群保存一些meta信息,来保证系统可用性。
Kafka架构
kafka架构
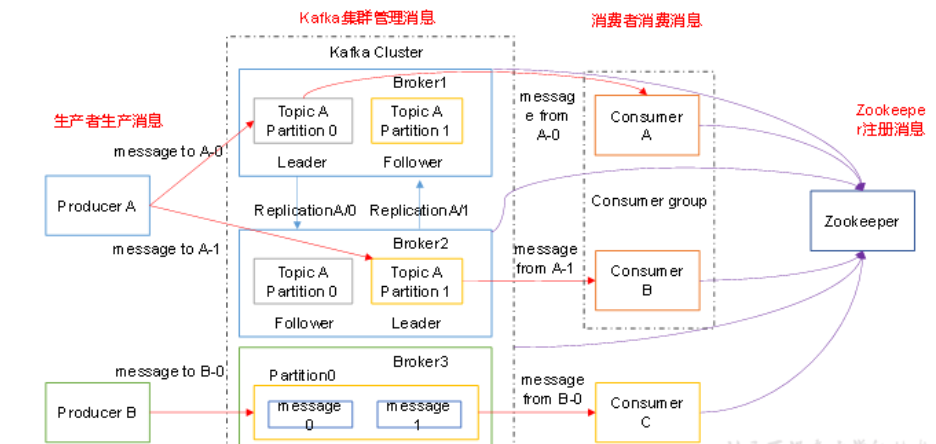
1)Producer :消息生产者,就是向kafka broker发消息的客户端;
2)Consumer :消息消费者,向kafka broker取消息的客户端;
3)Topic :可以理解为一个队列;
4) Consumer Group (CG):这是kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的手段。一个topic可以有多个CG。topic的消息会复制(不是真的复制,是概念上的)到所有的CG,但每个partion只会把消息发给该CG中的一个consumer。如果需要实现广播,只要每个consumer有一个独立的CG就可以了。要实现单播只要所有的consumer在同一个CG。用CG还可以将consumer进行自由的分组而不需要多次发送消息到不同的topic;
5)Broker :一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic;
6)Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序;
7)Offset:kafka的存储文件都是按照offset.kafka来命名,用offset做名字的好处是方便查找。例如你想找位于2049的位置,只要找到2048.kafka的文件即可。当然the first offset就是00000000000.kafka。
Kafka集群部署
1.集群规划
hadoop102 hadoop103 hadoop104
zk zk zk
kafka kafka kafka
2.jar包下载
http://kafka.apache.org/downloads.html

3.Kafka集群部署
1)解压安装包
[a@hadoop102 software]$ tar -zxvf kafka_2.11-0.11.0.0.tgz -C /opt/module/
2)修改解压后的文件名称
[a@hadoop102 module]$ mv kafka_2.11-0.11.0.0/ kafka
3)在/opt/module/kafka目录下创建logs文件夹
[a@hadoop102 kafka]$ mkdir logs
4)修改配置文件
[a@hadoop102 kafka]$ cd config/
[atguigu@hadoop102 config]$ vi server.properties
输入以下内容:
#broker的全局唯一编号,不能重复 broker.id=0 #删除topic功能使能 delete.topic.enable=true #处理网络请求的线程数量 num.network.threads=3 #用来处理磁盘IO的现成数量 num.io.threads=8 #发送套接字的缓冲区大小 socket.send.buffer.bytes=102400 #接收套接字的缓冲区大小 socket.receive.buffer.bytes=102400 #请求套接字的缓冲区大小 socket.request.max.bytes=104857600 #kafka运行日志存放的路径 log.dirs=/opt/module/kafka/logs #topic在当前broker上的分区个数 num.partitions=1 #用来恢复和清理data下数据的线程数量 num.recovery.threads.per.data.dir=1 #segment文件保留的最长时间,超时将被删除 log.retention.hours=168 #配置连接Zookeeper集群地址 zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181
5)配置环境变量
[@hadoop102 module]$ sudo vi /etc/profile
#KAFKA_HOME export KAFKA_HOME=/opt/module/kafka export PATH=$PATH:$KAFKA_HOME/bin
6)分发安装包
[a@hadoop102 module]$ xsync kafka/
注意:分发之后记得配置其他机器的环境变量
7)分别在hadoop103和hadoop104上修改配置文件/opt/module/kafka/config/server.properties中的broker.id=1、broker.id=2
注:broker.id不得重复
8)启动集群
依次在hadoop102、hadoop103、hadoop104节点上启动kafka
[a@hadoop102 kafka]$ bin/kafka-server-start.sh config/server.properties &
[a@hadoop103 kafka]$ bin/kafka-server-start.sh config/server.properties &
[a@hadoop104 kafka]$ bin/kafka-server-start.sh config/server.properties &
9)关闭集群
[a@hadoop102 kafka]$ bin/kafka-server-stop.sh stop
[a@hadoop103 kafka]$ bin/kafka-server-stop.sh stop
[a@hadoop104 kafka]$ bin/kafka-server-stop.sh stop


#/bin/bash case $1 in start) for i in hadoop102 hadoop103 hadoop104 do ssh $i "cd /opt/module/kafka/ && nohup bin/kafka-server-start.sh config/server.properties >/dev/null &" echo "----已启动$i----" done ;; stop) for i in hadoop102 hadoop103 hadoop104 do ssh $i "cd /opt/module/kafka/ && bin/kafka-server-stop.sh stop " echo "----已关闭$i----" done ;; *) echo "exit" esac
Kafka命令行操作
1)查看当前服务器中的所有topic
[a@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181 --list
2)创建topic
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181 --create --replication-factor 3 --partitions 1 --topic first
选项说明:
--topic 定义topic名
--replication-factor 定义副本数
--partitions 定义分区数
3)删除topic
[a@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181 --delete --topic first
需要server.properties中设置delete.topic.enable=true否则只是标记删除或者直接重启。
4)发送消息
[a@hadoop102 kafka]$ bin/kafka-console-producer.sh --broker-list hadoop102:9092 --topic first
>hello world
>deng
5)消费消息
[a@hadoop103 kafka]$ bin/kafka-console-consumer.sh --zookeeper hadoop102:2181 --from-beginning --topic first
--from-beginning:会把first主题中以往所有的数据都读取出来。根据业务场景选择是否增加该配置。
6)查看某个Topic的详情
[a@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181 --describe --topic first
Kafka API实战
Kafka生产者
pom.xml文件
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>deng.com</groupId> <artifactId>flink_demo</artifactId> <version>1.0-SNAPSHOT</version> <properties> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> </properties> <dependencies> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>0.11.0.0</version> </dependency> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka_2.12</artifactId> <version>0.11.0.0</version> </dependency> </dependencies> </project>
1. 普通生产者
package com.deng.kfk.producer; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.clients.producer.RecordMetadata; import java.util.Properties; import java.util.concurrent.ExecutionException; public class MyProducer { public static void main(String[] args) throws ExecutionException, InterruptedException { //1.创建kafka生产者配置信息 Properties props = new Properties(); //2. 指定连接的kafka集群 props.put("bootstrap.servers", "hadoop104:9092"); //3.ACK应答级别 props.put("acks", "all"); //4.重试次数 props.put("retries", 3); // 批次大小 props.put("batch.size", 16384); // 等待时间 props.put("linger.ms", 1); //RecordAccumulator 缓冲区大小 props.put("buffer.memory", 3354432); props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // value序列化 props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 创建生产者对象 KafkaProducer<String, String> producer = new KafkaProducer<>(props); //发送数据 异步方式 for(int i=1;i<=10;i++){ producer.send(new ProducerRecord<String, String>("first", "deng_"+i)); } // 同步方式,调用get 方法 ,保证消息发送有序 for(int i=1;i<=10;i++){ RecordMetadata first = producer.send(new ProducerRecord<String, String>("first", "deng_" + i)).get(); } // 关闭资源 producer.close(); } }
2. 带回调的生产者
package com.deng.kfk.producer; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerRecord; import java.util.Properties; public class CallBackProducer { public static void main(String[] args) { //1. Properties props = new Properties(); //2. 指定连接的kafka集群 props.put("bootstrap.servers", "hadoop104:9092"); //3.ACK应答级别 props.put("acks", "all"); //4.重试次数 props.put("retries", 3); // 批次大小 props.put("batch.size", 16384); // 等待时间 props.put("linger.ms", 1); //RecordAccumulator 缓冲区大小 props.put("buffer.memory", 3354432); props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // value序列化 props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 创建生产者对象 KafkaProducer<String,String> producer = new KafkaProducer<>(props); for(int i=0;i<10;i++){ producer.send(new ProducerRecord<>("AA","deng","value1"),(metadata, e) ->{ if(e==null){ System.out.println(metadata.topic()+"----"+metadata.offset()+"----"+metadata.partition()); }else{ e.printStackTrace(); } } ); } producer.close(); } }
自定义分区器
package com.deng.kfk.partitioner; import org.apache.kafka.clients.producer.Partitioner; import org.apache.kafka.common.Cluster; import java.util.Map; // 自定义分区器 public class MyPartitioner implements Partitioner { @Override public int partition(String s, Object o, byte[] bytes, Object o1, byte[] bytes1, Cluster cluster) { // 根据业务自定分区逻辑 //此处分区为0号分区 return 0; } @Override public void close() { } @Override public void configure(Map<String, ?> map) { } }
3. 引入自定义分区器的生产者
package com.deng.kfk.producer; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerConfig; import org.apache.kafka.clients.producer.ProducerRecord; import java.util.Properties; public class PartitionerProducer { public static void main(String[] args) { //1.创建kafka生产者配置信息 Properties props = new Properties(); //2. 指定连接的kafka集群 props.put("bootstrap.servers", "hadoop104:9092"); //3.ACK应答级别 props.put("acks", "all"); //4.重试次数 props.put("retries", 3); // 批次大小 props.put("batch.size", 16384); // 等待时间 props.put("linger.ms", 1); //RecordAccumulator 缓冲区大小 props.put("buffer.memory", 3354432); props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // value序列化 props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 添加分区器 props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,"com.deng.kfk.partitioner.MyPartitioner"); // 创建生产者对象 KafkaProducer<String, String> producer = new KafkaProducer<>(props); //发送数据 for(int i=0;i<10;i++){ producer.send(new ProducerRecord<>("AA","deng","value1"),(metadata, e) ->{ if(e==null){ System.out.println(metadata.topic()+"----"+metadata.offset()+"----"+metadata.partition()); }else{ e.printStackTrace(); } } ); } producer.close(); } }
kafka 拦击器
package com.deng.kfk.interceptor; import org.apache.kafka.clients.producer.ProducerInterceptor; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.clients.producer.RecordMetadata; import java.util.Map; public class CountInterceptor implements ProducerInterceptor<String,String> { int successNum; int errorNum; @Override public void configure(Map<String, ?> map) { } @Override public ProducerRecord onSend(ProducerRecord<String,String> record) { return record; } @Override public void onAcknowledgement(RecordMetadata recordMetadata, Exception e) { if (recordMetadata !=null){ // 统计成功的数据 successNum++; }else{ // 统计失败的数据 errorNum++; } } @Override public void close() { //打印统计后的结果 System.out.println("successNum="+successNum+",errorNum="+errorNum); } }
package com.deng.kfk.interceptor; import org.apache.kafka.clients.producer.ProducerInterceptor; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.clients.producer.RecordMetadata; import java.util.Map; public class TimeInterceptor implements ProducerInterceptor<String,String> { @Override public void configure(Map<String, ?> map) { } @Override public ProducerRecord onSend(ProducerRecord<String,String> record) { // 1. 构建新的vaule值 String newVaule=System.currentTimeMillis()+record.value(); // 2. 创建一个ProducerRecord的匿名对象,并返回 return new ProducerRecord<String,String>(record.topic(),record.partition(),record.key(),newVaule); } @Override public void onAcknowledgement(RecordMetadata recordMetadata, Exception e) { } @Override public void close() { } }
生产者添加自定义拦击器
package com.deng.kfk.producer; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerConfig; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.clients.producer.RecordMetadata; import java.util.ArrayList; import java.util.Properties; public class InterceptorProducer { public static void main(String[] args) { //1.创建kafka生产者配置信息 Properties props = new Properties(); //2. 指定连接的kafka集群 props.put("bootstrap.servers", "hadoop104:9092"); //3.ACK应答级别 props.put("acks", "all"); //4.重试次数 props.put("retries", 3); // 批次大小 props.put("batch.size", 16384); // 等待时间 props.put("linger.ms", 1); //RecordAccumulator 缓冲区大小 props.put("buffer.memory", 3354432); props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // value序列化 props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 添加拦击器 ArrayList<String> interceptors = new ArrayList<>(); interceptors.add("com.deng.kfk.interceptor.TimeInterceptor"); interceptors.add("com.deng.kfk.interceptor.CountInterceptor"); props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,interceptors); // 创建生产者对象 KafkaProducer<String, String> producer = new KafkaProducer<>(props); //发送数据 异步方式 for(int i=1;i<=10;i++){ producer.send(new ProducerRecord<String, String>("first","my_key" ,"deng_"+i)); } // 关闭资源 producer.close(); } }
Kafka消费者
1. 消费者(自动提交offset)
package com.deng.kfk.consumer; import org.apache.kafka.clients.consumer.*; import java.util.ArrayList; import java.util.Arrays; import java.util.Properties; public class MyConsumer { public static void main(String[] args) { //创建消费者配置信息 Properties prop = new Properties(); // 1. 连接kafka 集群 prop.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092"); // 2. 开启自动提交 prop.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,true); // 3. 自动提交延时 1s prop.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,1000); // 4. KEY, VAULE 反序列化 prop.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer"); prop.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer"); // 5. 消费者组 prop.put(ConsumerConfig.GROUP_ID_CONFIG,"bigdata"); // 6 . 创建消费者 KafkaConsumer<String,String> consumer = new KafkaConsumer<>(prop); // 7. 订阅主题 consumer.subscribe(Arrays.asList("first","second")); while (true) { // 8. 获取数据 ConsumerRecords<String, String> consumerRecords = consumer.poll(100); // 9. 解析并打印 for (ConsumerRecord<String, String> consumerRecord : consumerRecords) { String key = consumerRecord.key(); String value = consumerRecord.value(); System.out.println("key=" + key + ",value=" + value); } } } }
如何重新消费一个主题的数据?
换组 同时 设置auto.offset.reset="earliest"
package com.deng.kfk.consumer; import org.apache.kafka.clients.consumer.*; import java.util.ArrayList; import java.util.Arrays; import java.util.Properties; public class MyConsumer { public static void main(String[] args) { //创建消费者配置信息 Properties prop = new Properties(); // 1. 连接kafka 集群 prop.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092"); // 2. 开启自动提交 prop.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,true); // 3. 自动提交延时 1s prop.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,1000); // 4. KEY, VAULE 反序列化 prop.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer"); prop.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer"); // 5. 消费者组 prop.put(ConsumerConfig.GROUP_ID_CONFIG,"bigdata"); // 重置消费者offset prop.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest"); // 6 . 创建消费者 KafkaConsumer<String,String> consumer = new KafkaConsumer<>(prop); // 7. 订阅主题 consumer.subscribe(Arrays.asList("first","second")); while (true) { // 8. 获取数据 ConsumerRecords<String, String> consumerRecords = consumer.poll(100); // 9. 解析并打印 for (ConsumerRecord<String, String> consumerRecord : consumerRecords) { String key = consumerRecord.key(); String value = consumerRecord.value(); System.out.println("key=" + key + ",value=" + value); } } } }
2. 消费者(手动提交offset)
package com.deng.kfk.consumer; import org.apache.kafka.clients.consumer.*; import org.apache.kafka.common.TopicPartition; import java.util.Arrays; import java.util.Map; import java.util.Properties; public class MyConsumer2 { public static void main(String[] args) { //创建消费者配置信息 Properties prop = new Properties(); // 1. 连接kafka 集群 prop.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092"); // 2. 关闭自动提交 prop.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false); // 3. 自动提交延时 1s // prop.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,1000); // 4. KEY, VAULE 反序列化 prop.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer"); prop.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer"); // 5. 消费者组 prop.put(ConsumerConfig.GROUP_ID_CONFIG,"bigdata"); // 重置消费者offset prop.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest"); // 6 . 创建消费者 KafkaConsumer<String,String> consumer = new KafkaConsumer<>(prop); // 7. 订阅主题 consumer.subscribe(Arrays.asList("first","second")); while (true) { // 8. 获取数据 ConsumerRecords<String, String> consumerRecords = consumer.poll(100); // 9. 解析并打印 for (ConsumerRecord<String, String> consumerRecord : consumerRecords) { String key = consumerRecord.key(); String value = consumerRecord.value(); System.out.println("key=" + key + ",value=" + value+",offset="+consumerRecord.offset()); // 手动异步提交offset consumer.commitAsync(new OffsetCommitCallback() { @Override public void onComplete(Map<TopicPartition, OffsetAndMetadata> map, Exception e) { if(e != null){ // 提交失败 System.out.println("offset commit fail"+ consumerRecord.offset()); } } }); } } } }
3. 消费者(自定存储offset) 和mysql做事务。