为什么需要熔断
微服务集群中,每个应用基本都会依赖一定数量的外部服务。有可能随时都会遇到网络连接缓慢,超时,依赖服务过载,服务不可用的情况,在高并发场景下如果此时调用方不做任何处理,继续持续请求故障服务的话很容易引起整个微服务集群雪崩。
比如高并发场景的用户订单服务,一般需要依赖一下服务:
- 商品服务
- 账户服务
- 库存服务
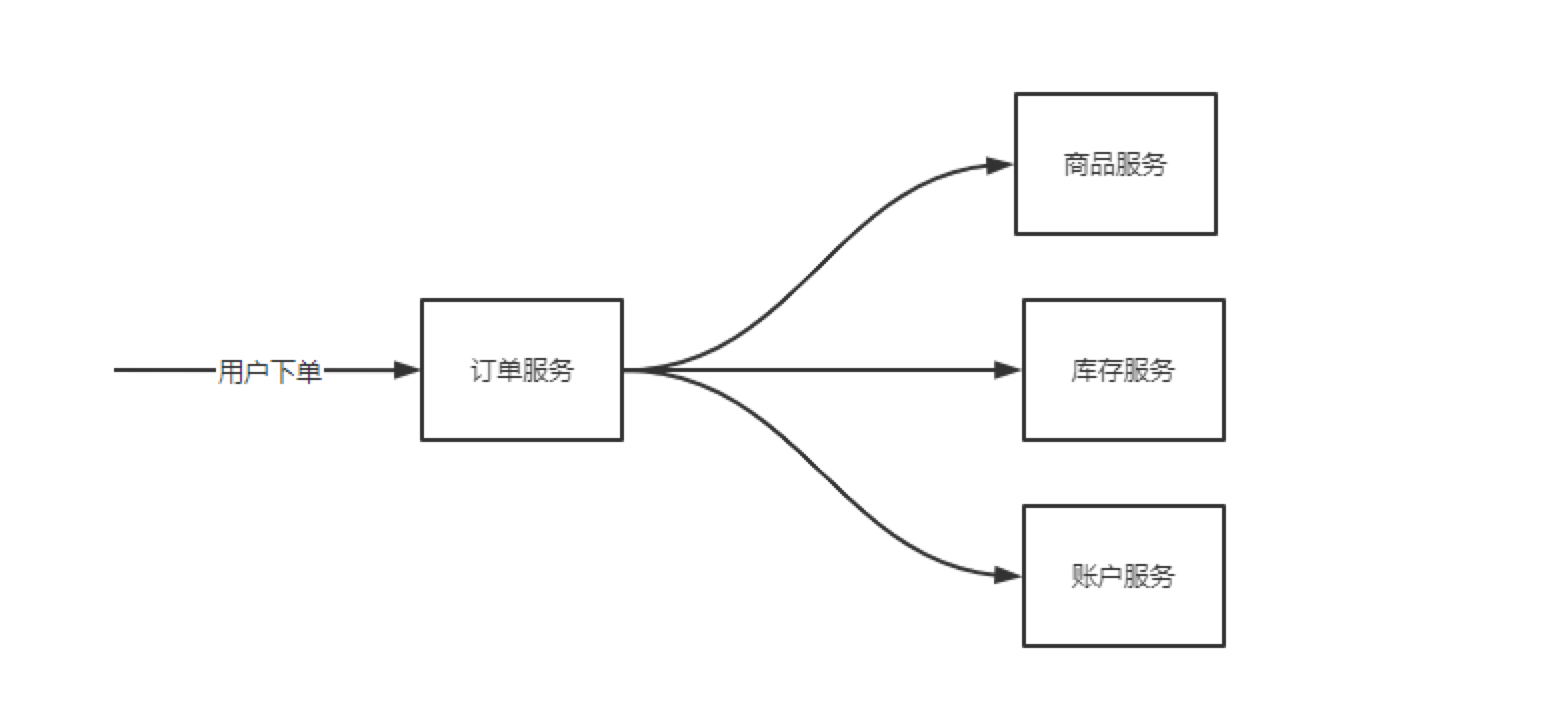
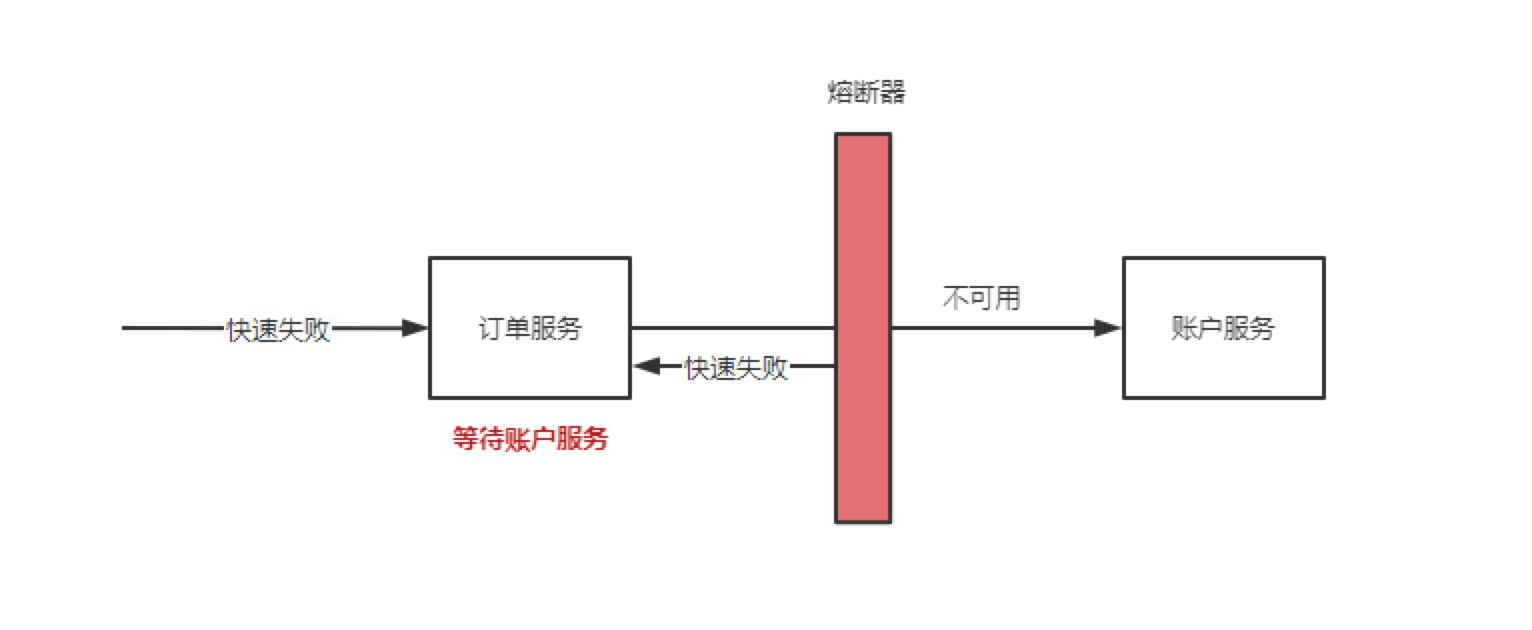
假如此时 账户服务 过载,订单服务持续请求账户服务只能被动的等待账户服务报错或者请求超时,进而导致订单请求被大量堆积,这些无效请求依然会占用系统资源:cpu,内存,数据连接...导致订单服务整体不可用。即使账户服务恢复了订单服务也无法自我恢复。

这时如果有一个主动保护机制应对这种场景的话订单服务至少可以保证自身的运行状态,等待账户服务恢复时订单服务也同步自我恢复,这种自我保护机制在服务治理中叫熔断机制。
熔断
熔断是调用方自我保护的机制(客观上也能保护被调用方),熔断对象是外部服务。
降级
降级是被调用方(服务提供者)的防止因自身资源不足导致过载的自我保护机制,降级对象是自身。
熔断这一词来源时我们日常生活电路里面的熔断器,当负载过高时(电流过大)保险丝会自行熔断防止电路被烧坏,很多技术都是来自生活场景的提炼。
工作原理
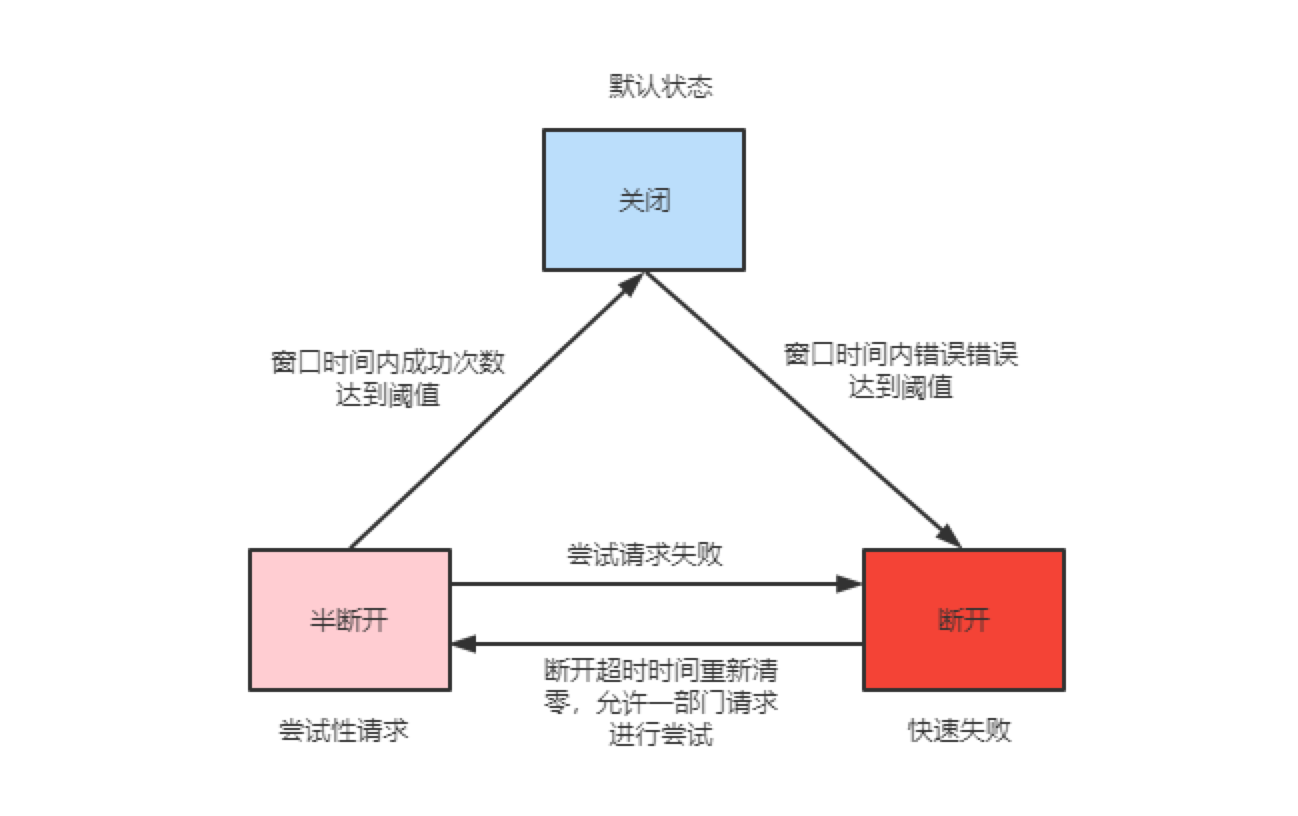
熔断器一般具有三个状态:
- 关闭:默认状态,请求能被到达目标服务,同时统计在窗口时间成功和失败次数,如果达到错误率阈值将会进入断开状态。
- 断开: 此状态下将会直接返回错误,如果有 fallback 配置则直接调用 fallback 方法。
- 半断开:进行断开状态会维护一个超市时间,到达超时时间开始进入 半断开 状态,尝试允许一部门请求正常通过并统计成功数量,如果请求正常则认为此时目标服务已恢复进入 关闭 状态,否则进入 断开 状态。半断开 状态存在的目的在于实现了自我修复,同时防止正在恢复的服务再次被大量打垮。
使用较多的熔断组件:
- hystrix circuit breaker(不再维护)
- hystrix-go
- resilience4j(推荐)
- sentinel(推荐)
什么是自适应熔断
基于上面提到的熔断器原理,项目中我们要使用好熔断器通常需要准备以下参数:
- 错误比例阈值:达到该阈值进入 断开 状态。
- 断开状态超时时间:超时后进入 半断开 状态。
- 半断开状态允许请求数量。
- 窗口时间大小。
实际上可选的配置参数还有非常非常多,参考 https://resilience4j.readme.io/docs/circuitbreaker
对于经验不够丰富的开发人员而言,这些参数设置多少合适心里其实并没有底。
那么有没有一种自适应的熔断算法能让我们不关注参数,只要简单配置就能满足大部分场景?
其实是有的,google sre提供了一种自适应熔断算法来计算丢弃请求的概率:

算法参数:
- requests: 窗口时间内的请求总数
- accepts:正常请求数量
- K:敏感度,K 越小越容易丢请求,一般推荐 1.5-2 之间
算法解释:
- 正常情况下 requests=accepts,所以概率是 0。
- 随着正常请求数量减少,当达到 requests == K* accepts 继续请求时,概率 P 会逐渐比 0 大开始按照概率逐渐丢弃一些请求,如果故障严重则丢包会越来越多,假如窗口时间内 accepts==0 则完全熔断。
- 当应用逐渐恢复正常时,accepts、requests 同时都在增加,但是 K*accepts 会比 requests 增加的更快,所以概率很快就会归 0,关闭熔断。
代码实现
接下来思考一个熔断器如何实现。
初步思路是:
- 无论什么熔断器都得依靠指标统计来转换状态,而统计指标一般要求是最近的一段时间内的数据(太久的数据没有参考意义也浪费空间),所以通常采用一个 滑动时间窗口 数据结构 来存储统计数据。同时熔断器的状态也需要依靠指标统计来实现可观测性,我们实现任何系统第一步需要考虑就是可观测性,不然系统就是一个黑盒。
- 外部服务请求结果各式各样,所以需要提供一个自定义的判断方法,判断请求是否成功。可能是 http.code 、rpc.code、body.code,熔断器需要实时收集此数据。
- 当外部服务被熔断时使用者往往需要自定义快速失败的逻辑,考虑提供自定义的 fallback() 功能。
下面来逐步分析 go-zero 的源码实现:
core/breaker/breaker.go
熔断器接口定义
兵马未动,粮草先行,明确了需求后就可以开始规划定义接口了,接口是我们编码思维抽象的第一步也是最重要的一步。
核心定义包含两种类型的方法:
Allow():需要手动回调请求结果至熔断器,相当于手动挡。
DoXXX():自动回调请求结果至熔断器,相当于自动挡,实际上 DoXXX() 类型方法最后都是调用
DoWithFallbackAcceptable(req func() error, fallback func(err error) error, acceptable Acceptable) error
// 自定义判定执行结果
Acceptable func(err error) bool
// 手动回调
Promise interface {
// Accept tells the Breaker that the call is successful.
// 请求成功
Accept()
// Reject tells the Breaker that the call is failed.
// 请求失败
Reject(reason string)
}
Breaker interface {
// 熔断器名称
Name() string
// 熔断方法,执行请求时必须手动上报执行结果
// 适用于简单无需自定义快速失败,无需自定义判定请求结果的场景
// 相当于手动挡。。。
Allow() (Promise, error)
// 熔断方法,自动上报执行结果
// 自动挡。。。
Do(req func() error) error
// 熔断方法
// acceptable - 支持自定义判定执行结果
DoWithAcceptable(req func() error, acceptable Acceptable) error
// 熔断方法
// fallback - 支持自定义快速失败
DoWithFallback(req func() error, fallback func(err error) error) error
// 熔断方法
// fallback - 支持自定义快速失败
// acceptable - 支持自定义判定执行结果
DoWithFallbackAcceptable(req func() error, fallback func(err error) error, acceptable Acceptable) error
}
熔断器实现
circuitBreaker 继承 throttle,实际上这里相当于静态代理,代理模式可以在不改变原有对象的基础上增强功能,后面我们会看到 go-zero 这样做的原因是为了收集熔断器错误数据,也就是为了实现可观测性。
熔断器实现采用静态代理模式,看起来稍微有点绕脑。

// 熔断器结构体
circuitBreaker struct {
name string
// 实际上 circuitBreaker熔断功能都代理给 throttle来实现
throttle
}
// 熔断器接口
throttle interface {
// 熔断方法
allow() (Promise, error)
// 熔断方法
// DoXXX()方法最终都会该方法
doReq(req func() error, fallback func(err error) error, acceptable Acceptable) error
}
func (cb *circuitBreaker) Allow() (Promise, error) {
return cb.throttle.allow()
}
func (cb *circuitBreaker) Do(req func() error) error {
return cb.throttle.doReq(req, nil, defaultAcceptable)
}
func (cb *circuitBreaker) DoWithAcceptable(req func() error, acceptable Acceptable) error {
return cb.throttle.doReq(req, nil, acceptable)
}
func (cb *circuitBreaker) DoWithFallback(req func() error, fallback func(err error) error) error {
return cb.throttle.doReq(req, fallback, defaultAcceptable)
}
func (cb *circuitBreaker) DoWithFallbackAcceptable(req func() error, fallback func(err error) error,
acceptable Acceptable) error {
return cb.throttle.doReq(req, fallback, acceptable)
}
throttle 接口实现类:
loggedThrottle 增加了为了收集错误日志的滚动窗口,目的是为了收集当请求失败时的错误日志。
// 带日志功能的熔断器
type loggedThrottle struct {
// 名称
name string
// 代理对象
internalThrottle
// 滚动窗口,滚动收集数据,相当于环形数组
errWin *errorWindow
}
// 熔断方法
func (lt loggedThrottle) allow() (Promise, error) {
promise, err := lt.internalThrottle.allow()
return promiseWithReason{
promise: promise,
errWin: lt.errWin,
}, lt.logError(err)
}
// 熔断方法
func (lt loggedThrottle) doReq(req func() error, fallback func(err error) error, acceptable Acceptable) error {
return lt.logError(lt.internalThrottle.doReq(req, fallback, func(err error) bool {
accept := acceptable(err)
if !accept {
lt.errWin.add(err.Error())
}
return accept
}))
}
func (lt loggedThrottle) logError(err error) error {
if err == ErrServiceUnavailable {
// if circuit open, not possible to have empty error window
stat.Report(fmt.Sprintf(
"proc(%s/%d), callee: %s, breaker is open and requests dropped\nlast errors:\n%s",
proc.ProcessName(), proc.Pid(), lt.name, lt.errWin))
}
return err
}
错误日志收集 errorWindow
errorWindow 是一个环形数组,新数据不断滚动覆盖最旧的数据,通过取余实现。
// 滚动窗口
type errorWindow struct {
reasons [numHistoryReasons]string
index int
count int
lock sync.Mutex
}
// 添加数据
func (ew *errorWindow) add(reason string) {
ew.lock.Lock()
// 添加错误日志
ew.reasons[ew.index] = fmt.Sprintf("%s %s", timex.Time().Format(timeFormat), reason)
// 更新index,为下一次写入数据做准备
// 这里用的取模实现了滚动功能
ew.index = (ew.index + 1) % numHistoryReasons
// 统计数量
ew.count = mathx.MinInt(ew.count+1, numHistoryReasons)
ew.lock.Unlock()
}
// 格式化错误日志
func (ew *errorWindow) String() string {
var reasons []string
ew.lock.Lock()
// reverse order
for i := ew.index - 1; i >= ew.index-ew.count; i-- {
reasons = append(reasons, ew.reasons[(i+numHistoryReasons)%numHistoryReasons])
}
ew.lock.Unlock()
return strings.Join(reasons, "\n")
}
看到这里我们还没看到实际的熔断器实现,实际上真正的熔断操作被代理给了 internalThrottle 对象。
internalThrottle interface {
allow() (internalPromise, error)
doReq(req func() error, fallback func(err error) error, acceptable Acceptable) error
}
internalThrottle 接口实现 googleBreaker 结构体定义
type googleBreaker struct {
// 敏感度,go-zero中默认值为1.5
k float64
// 滑动窗口,用于记录最近一段时间内的请求总数,成功总数
stat *collection.RollingWindow
// 概率生成器
// 随机产生0.0-1.0之间的双精度浮点数
proba *mathx.Proba
}
可以看到熔断器属性其实非常简单,数据统计采用的是滑动时间窗口来实现。
RollingWindow 滑动窗口
滑动窗口属于比较通用的数据结构,常用于最近一段时间内的行为数据统计。
它的实现非常有意思,尤其是如何模拟窗口滑动过程。
先来看滑动窗口的结构体定义:
RollingWindow struct {
// 互斥锁
lock sync.RWMutex
// 滑动窗口数量
size int
// 窗口,数据容器
win *window
// 滑动窗口单元时间间隔
interval time.Duration
// 游标,用于定位当前应该写入哪个bucket
offset int
// 汇总数据时,是否忽略当前正在写入桶的数据
// 某些场景下因为当前正在写入的桶数据并没有经过完整的窗口时间间隔
// 可能导致当前桶的统计并不准确
ignoreCurrent bool
// 最后写入桶的时间
// 用于计算下一次写入数据间隔最后一次写入数据的之间
// 经过了多少个时间间隔
lastTime time.Duration
}

window 是数据的实际存储位置,其实就是一个数组,提供向指定 offset 添加数据与清除操作。
数组里面按照 internal 时间间隔分隔成多个 bucket。
// 时间窗口
type window struct {
// 桶
// 一个桶标识一个时间间隔
buckets []*Bucket
// 窗口大小
size int
}
// 添加数据
// offset - 游标,定位写入bucket位置
// v - 行为数据
func (w *window) add(offset int, v float64) {
w.buckets[offset%w.size].add(v)
}
// 汇总数据
// fn - 自定义的bucket统计函数
func (w *window) reduce(start, count int, fn func(b *Bucket)) {
for i := 0; i < count; i++ {
fn(w.buckets[(start+i)%w.size])
}
}
// 清理特定bucket
func (w *window) resetBucket(offset int) {
w.buckets[offset%w.size].reset()
}
// 桶
type Bucket struct {
// 当前桶内值之和
Sum float64
// 当前桶的add总次数
Count int64
}
// 向桶添加数据
func (b *Bucket) add(v float64) {
// 求和
b.Sum += v
// 次数+1
b.Count++
}
// 桶数据清零
func (b *Bucket) reset() {
b.Sum = 0
b.Count = 0
}
window 添加数据:
- 计算当前时间距离上次添加时间经过了多少个 时间间隔,实际上就是过期了几个 bucket。
- 清理过期桶的数据
- 更新 offset,更新 offset 的过程实际上就是在模拟窗口滑动
- 添加数据

// 添加数据
func (rw *RollingWindow) Add(v float64) {
rw.lock.Lock()
defer rw.lock.Unlock()
// 获取当前写入的下标
rw.updateOffset()
// 添加数据
rw.win.add(rw.offset, v)
}
// 计算当前距离最后写入数据经过多少个单元时间间隔
// 实际上指的就是经过多少个桶
func (rw *RollingWindow) span() int {
offset := int(timex.Since(rw.lastTime) / rw.interval)
if 0 <= offset && offset < rw.size {
return offset
}
// 大于时间窗口时 返回窗口大小即可
return rw.size
}
// 更新当前时间的offset
// 实现窗口滑动
func (rw *RollingWindow) updateOffset() {
// 经过span个桶的时间
span := rw.span()
// 还在同一单元时间内不需要更新
if span <= 0 {
return
}
offset := rw.offset
// 既然经过了span个桶的时间没有写入数据
// 那么这些桶内的数据就不应该继续保留了,属于过期数据清空即可
// 可以看到这里全部用的 % 取余操作,可以实现按照下标周期性写入
// 如果超出下标了那就从头开始写,确保新数据一定能够正常写入
// 类似循环数组的效果
for i := 0; i < span; i++ {
rw.win.resetBucket((offset + i + 1) % rw.size)
}
// 更新offset
rw.offset = (offset + span) % rw.size
now := timex.Now()
// 更新操作时间
// 这里很有意思
rw.lastTime = now - (now-rw.lastTime)%rw.interval
}
window 统计数据:
// 归纳汇总数据
func (rw *RollingWindow) Reduce(fn func(b *Bucket)) {
rw.lock.RLock()
defer rw.lock.RUnlock()
var diff int
span := rw.span()
// 当前时间截止前,未过期桶的数量
if span == 0 && rw.ignoreCurrent {
diff = rw.size - 1
} else {
diff = rw.size - span
}
if diff > 0 {
// rw.offset - rw.offset+span之间的桶数据是过期的不应该计入统计
offset := (rw.offset + span + 1) % rw.size
// 汇总数据
rw.win.reduce(offset, diff, fn)
}
}
googleBreaker 判断是否应该熔断
- 收集滑动窗口内的统计数据
- 计算熔断概率
// 按照最近一段时间的请求数据计算是否熔断
func (b *googleBreaker) accept() error {
// 获取最近一段时间的统计数据
accepts, total := b.history()
// 计算动态熔断概率
weightedAccepts := b.k * float64(accepts)
// https://landing.google.com/sre/sre-book/chapters/handling-overload/#eq2101
dropRatio := math.Max(0, (float64(total-protection)-weightedAccepts)/float64(total+1))
// 概率为0,通过
if dropRatio <= 0 {
return nil
}
// 随机产生0.0-1.0之间的随机数与上面计算出来的熔断概率相比较
// 如果随机数比熔断概率小则进行熔断
if b.proba.TrueOnProba(dropRatio) {
return ErrServiceUnavailable
}
return nil
}
googleBreaker 熔断逻辑实现
熔断器对外暴露两种类型的方法
- 简单场景直接判断对象是否被熔断,执行请求后必须需手动上报执行结果至熔断器。
func (b *googleBreaker) allow() (internalPromise, error)
- 复杂场景下支持自定义快速失败,自定义判定请求是否成功的熔断方法,自动上报执行结果至熔断器。
func (b *googleBreaker) doReq(req func() error, fallback func(err error) error, acceptable Acceptable) error
Acceptable 参数目的是自定义判断请求是否成功。
Acceptable func(err error) bool
// 熔断方法
// 返回一个promise异步回调对象,可由开发者自行决定是否上报结果到熔断器
func (b *googleBreaker) allow() (internalPromise, error) {
if err := b.accept(); err != nil {
return nil, err
}
return googlePromise{
b: b,
}, nil
}
// 熔断方法
// req - 熔断对象方法
// fallback - 自定义快速失败函数,可对熔断产生的err进行包装后返回
// acceptable - 对本次未熔断时执行请求的结果进行自定义的判定,比如可以针对http.code,rpc.code,body.code
func (b *googleBreaker) doReq(req func() error, fallback func(err error) error, acceptable Acceptable) error {
// 判定是否熔断
if err := b.accept(); err != nil {
// 熔断中,如果有自定义的fallback则执行
if fallback != nil {
return fallback(err)
}
return err
}
// 如果执行req()过程发生了panic,依然判定本次执行失败上报至熔断器
defer func() {
if e := recover(); e != nil {
b.markFailure()
panic(e)
}
}()
// 执行请求
err := req()
// 判定请求成功
if acceptable(err) {
b.markSuccess()
} else {
b.markFailure()
}
return err
}
// 上报成功
func (b *googleBreaker) markSuccess() {
b.stat.Add(1)
}
// 上报失败
func (b *googleBreaker) markFailure() {
b.stat.Add(0)
}
// 统计数据
func (b *googleBreaker) history() (accepts, total int64) {
b.stat.Reduce(func(b *collection.Bucket) {
accepts += int64(b.Sum)
total += b.Count
})
return
}
资料
项目地址
https://github.com/zeromicro/go-zero
欢迎使用 go-zero 并 star 支持我们!