第6章 关系数据理论(重点)
了解
- “不好”的数据库模式
- 模式的插入异常和删除异常
- 规范化理论的重要意义
掌握
- 关系的形式化定义
- 数据依赖的基本概念(函数依赖、平凡/非平凡/部分/完全/传递函数依赖,码、候选码、外码、多值依赖)
- 范式的概念,1NF-4NF,规范化的含义和作用
- 4个范式的理解与应用
- 各个级别范式中存在的问题和解决方法(插入异常,删除异常,数据冗余)
- 根据应用语义完整地写出关系模式的数据依赖集合,根据数据依赖分析某一个关系模式属于第几范式
知识点
- 函数依赖、部分函数依赖、完全函数依赖、传递依赖、候选码、主码、外码、全码、1NF、2NF、3NF、BCNF、多值依赖、4NF
- 函数依赖:设R (U)是一个关系模式,U是R的属性集合,X和Y是U的子集。对于R (U)的任意一个可能的关系r,如果r中不存在两个元组,它们在X上的属性值相同, 而在Y上的属性值不同, 则称"X函数确定Y"或"Y函数依赖于X",记作X→Y
- 函数依赖是最基本的一种数据依赖,也是最重要的一种数据依赖。
- 函数依赖是属性之间的一种联系,体现在属性值是否相等。由上面的定义可以知道,如果X→Y,则r中任意两个元组,若它们在X上的属性值相同,那么在Y上的属性值一定也相同。
- 我们要从属性间实际存在的语义来确定他们之间的函数依赖,即函数依赖反映了(描述了)现实世界的一种语义。
- 函数依赖不是指关系模式R的在某个时刻的关系(值)满足的约束条件,而是指R任何时刻的一切关系均要满足的约束条件
- 完全函数依赖、部分函数依赖:在R(U)中,如果X→Y,并且对于X的任何一个真子集X,都有X′→Y,则称Y对X完全函数依赖;若X→Y,但Y不完全函数依赖于X,则称Y对X部分函数依赖
- 候选码、主码: 设K为R(U,F)中的属性或属性组合,若K → U则K为R的候选码。若候选码多于一个,则选定其中的一个为主码
- 外码:关系模式R中属性或属性组X并非R的码,但X是另一个关系模式的码,则称X是R的外部码也称外码
- 全码:整个属性组是码,称为全码(All-key)1NF:如果一个关系模式R的所有属性都是不可分的基本数据项,则R∈1NF
-
- 第一范式是对关系模式的最起码的要求。不满足第一范式的数据库模式不能称为关系数据库
- 2NF:若关系模式R∈1NF,并且每一个非主属性都完全依赖于R的码,则R∈2NF
- 3NF:关系模式R<U,F>中若不存在这样的码X,属性组Y及非主属性Z(Z不包含于Y)使得X→ Y,(Y不→ X),Y→ Z成立,则称R<U,F>∈3NF
- BCNF:关系模式R<U,F>∈1NF.若X→ Y且(Y不包含于X)时X必含有码,则R<U,F>∈BCNF
- 多值依赖:设R (U)是属性集U上的一个关系模式,X、Y、Z是U的子集,并且Z=U-X-Y。关系模式R(U)中多值依赖X→ → Y成立,当且仅当对R(U)的任一关系r,给定的一对(x,z)值,有一组Y的值,这组值仅仅决定于x值而与z值无关
- 4NF:关系模式R<U,F>∈1NF,如果对于R的每个非平凡多值依赖X→ → Y(Y不包含于X),X都含有码,则称R<U,F>∈4NF
建立一个关于系、学生、班级、学会等诸信息的关系数据库。 描述学生的属性有:学号、姓名、出生年月、系名、班号、宿舍区。 描述班级的属性有:班号、专业名、系名、人数、入校年份。 描述系的属性有:系名、系号、系办公室地点、人数。 描述学会的属性有:学会名、成立年份、地点、人数。 有关语义如下:一个系有若干专业,每个专业每年只招一个班,每个班有若干学生。一个系的学生住在同一宿舍区。每个学生可参加若干学会,每个学会有若干学生。学生参加某学会有一个入会年份。 请给出关系模式,写出每个关系模式的极小函数依赖集,指出是否存在传递函数依赖,对于函数依赖左部是多属性的情况讨论函数依赖是完全函数依赖,还是部分函数依赖。 指出各关系的候选码、外部码,有没有全码存在?- 关系模式
- 学生S(S#,SN,SB,DN,C#,SA)
S#—学号,SN—姓名,SB—出生年月,SA—宿舍区 - 班级C(C#,CS,DN,CNUM,CDATE)
C#—班号,CS—专业名,CNUM—班级人数,CDATE—入校年份 - 系 D(D#,DN,DA,DNUM)
D#—系号,DN—系名,DA—系办公室地点,DNUM—系人数 - 学会P(PN,DATE1,PA,PNUM)
PN—学会名,DATE1—成立年月,PA—地点,PNUM—学会人数 - 学生--学会SP(S#,PN,DATE2)
DATE2—入会年份
- S:S#→SN,S#→SB,S#→C#,C#→DN,DN→SA
- C:C#→CS,C#→CNUM,C#→CDATE,CS→DN,(CS,CDATE)→C#
- D:D#→DN,DN→D#,D#→DA,D#→DNUM
- P:PN→DATE1,PN→PA,PN→PNUM
- SP:(S#,PN)→DATE2
- S#→DN, S#→SA, C#→SA
- C#→DN
- (S#,PN)→DATE2
- (CS,CDATE)→C#
- 均为SP中的函数依赖,是完全函数依赖
- S S# C#,DN 无
- C C#,(CS,CDATE) DN 无
- D D#和DN 无 无
- P PN 无 无
- SP (S#,PN) S#,PN 无
- 学生S(S#,SN,SB,DN,C#,SA)
- 合并规则:若X→Z,X→Y,则有X→YZ
已知X→Z,由增广律知XY→YZ,又因为X→Y,可得XX→XY→YZ,最后根据传递律得X→YZ。 - 伪传递规则:由X→Y,WY→Z有XW→Z
已知X→Y,据增广律得XW→WY,因为WY→Z,所以XW→WY→Z,通过传递律可知XW→Z。 - 分解规则:X→Y,Z 包含于 Y,有X→Z
已知Z 包含于 Y,根据自反律知Y→Z,又因为X→Y,所以由传递律可得X→Z。
- 关系模式MSC(M,S,C)中,M表示专业,S表示学生,C表示该专业的必修课。假设每个专业有多个学生,有一组必修课。设同专业内所有学生的选修的必修课相同,实例关系如下。按照语义对于M的每一个值M i,S有一个完整的集合与之对应而不问C取何值,所以M→→S。由于C与S的完全对称性,必然有M→→C成立。
M S CM 1 S1 C1M 1 S1 C2M 1 S2 C1M 1 S2 C2…… …… …… - 关系模式ISA(I,S,A)中,I表示学生兴趣小组,S表示学生,A表示某兴趣小组的活动项目。假设每个兴趣小组有多个学生,有若干活动项目。每个学生必须参加所在兴趣小组的所有活动项目,每个活动项目要求该兴趣小组的所有学生参加。按照语义有I→→S,I→→A成立。
- 关系模式RDP(R,D,P)中,R表示医院的病房,D表示责任医务人员,P表示病人。假设每个病房住有多个病人,有多个责任医务人员负责医治和护理该病房的所有病人。按照语义有R→→D,R→→P成立。
- 任何一个二目关系都是属于3NF的。√
- 任何一个二目关系都是属于BCNF的。√
- 任何一个二目关系都是属于4NF的。√
- 当且仅当函数依赖A→B在R上成立,关系R(A,B,C)等于其投影R1(A,B)和R2(A,C)的连接 ×
当且仅当函数依赖A→→B在R上成立,关系R(A,B,C)等于其投影R1(A,B)和R2(A,C)的连接 - 若R.A→R.B,R.B→R.C,则R.A→R.C √
- 若R.A→R.B,R.A→R.C,则R.A→R.(B, C) √
- 若R.B→R.A,R.C→R.A,则R.(B, C)→R.A √
- 若R.(B, C)→R.A,则R.B→R.A,R.C→R.A ×
反例:关系模式 SC(S#,C#,G) (S#,C#)→G,但是S# → G,C#→G
- 函数依赖:设R (U)是一个关系模式,U是R的属性集合,X和Y是U的子集。对于R (U)的任意一个可能的关系r,如果r中不存在两个元组,它们在X上的属性值相同, 而在Y上的属性值不同, 则称"X函数确定Y"或"Y函数依赖于X",记作X→Y
- 证明


补充
-
- 1.


- 2.


- 3.



- 4.
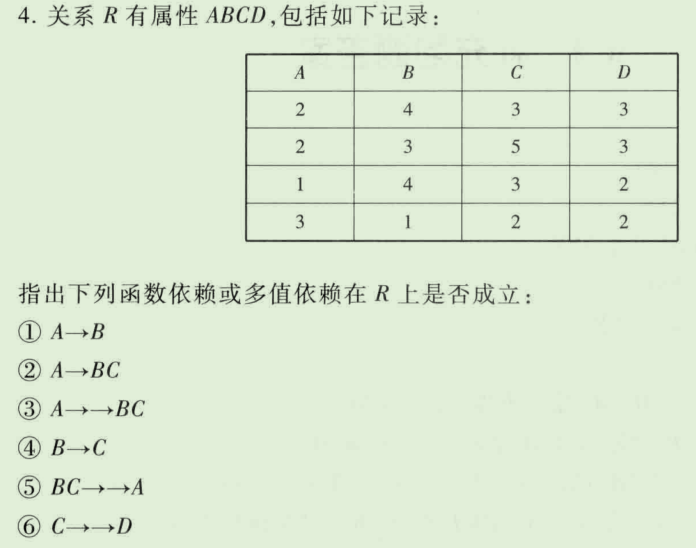

- 5.


- 6.


- 7.


- 为了设计出性能较优的关系模式,必须进行规范化,规范化主要的理论依据是【关系规范化理论】
- 规范化理论是关系数据库进行逻辑设计的理论依据,根据这个理论,关系数据库中的关系必须满足:每一个属性都是【不可分解的】
- 已知关系模式R(A,B,C,D,E)及其上的函数相关性集合F={A→D,B→C ,E→A },该关系模式的候选关键字是【BE】
- 设学生关系S(SNO,SNAME,SSEX,SAGE,SDPART)的主键为SNO,学生选课关系SC(SNO,CNO,SCORE)的主键为SNO和CNO,则关系R(SNO,CNO,SSEX,SAGE,SDPART,SCORE)的主键为SNO和CNO,其满足【1NF】
- 设有关系模式W(C,P,S,G,T,R),其中各属性的含义是:C表示课程,P表示教师,S表示学生,G表示成绩,T表示时间,R表示教室,根据语义有如下数据依赖集:D={ C→P,(S,C)→G,(T,R)→C,(T,P)→R,(T,S)→R },关系模式W的一个关键字是【(T,S)】
- 关系模式中,满足2NF的模式【必定是1NF】
- 关系模式R中的属性全是主属性,则R的最高范式必定是【3NF】
- 消除了部分函数依赖的1NF的关系模式,必定是【2NF】
- 如果A->B ,那么属性A和属性B的联系是【多对一】
- 关系模式的候选关键字可以有1个或多个,而主关键字有【1个】
- 候选关键字的属性可以有【1个或多个】
- 关系模式的任何属性【不可再分】
- 设有关系模式W(C,P,S,G,T,R),其中各属性的含义是:C表示课程,P表示教师,S表示学生,G表示成绩,T表示时间,R表示教室,根据语义有如下数据依赖集:D={ C→P,(S,C)→G,(T,R)→C,(T,P)→R,(T,S)→R },若将关系模式W分解为三个关系模式W1(C,P),W2(S,C,G),W2(S,T,R,C),则W1的规范化程序最高达到【BCNF】
- 在关系数据库中,任何二元关系模式的最高范式必定是【BCNF】
- 在关系规范式中,分解关系的基本原则是【实现无损连接、保持原有的依赖关系】
- 不能使一个关系从第一范式转化为第二范式的条件是【每一个非属性都部分函数依赖主属性】
- 任何一个满足2NF但不满足3NF的关系模式都不存在【非主属性对键的传递依赖】
- 设数据库关系模式R=(A,B,C,D,E),有下列函数依赖:A→BC,D→E,C→D;下述对R的分解中,哪些分解是R的无损连接分解【(A,B,C)(C,D,E) 】【(A,B)(A,C,D,E)】
- 设U是所有属性的集合,X、Y、Z都是U的子集,且Z=U-X-Y。下面关于多值依赖的叙述中,不正确的是【若X→→Y,且Y′∈Y,则X→→Y′】 ,正确的是【若X→→Y,则X→→Z 】【若X→Y,则X→→Y 】【若Z=∮,则X→→Y 】
- 若关系模式R(U,F)属于3NF,则【仍存在一定的插入和删除异常】
- 下列说法不正确的是【任何一个包含三个属性的关系模式一定满足3NF】
- 设关系模式R(A,B,C),F是R上成立的FD集,F={B→C},则分解P={AB,BC}相对于F【是无损联接,也是保持FD的分解】
- 关系数据库规范化是为了解决关系数据库中【插入、删除和数据冗余】的问题而引入的。
- 关系的规范化中,各个范式之间的关系是【1NF∈2NF∈3NF】
- 数据库中的冗余数据是指可【由基本数据导出】的数据
- 学生表(id,name,sex,age,depart_id,depart_name),存在函数依赖是id→name,sex,age,depart_id;dept_id→dept_name,其满足【2NF】
- 设有关系模式R(S,D,M),其函数依赖集:F={S→D,D→M},则关系模式R的规范化程度最高达到【2NF】
- 设有关系模式R(A,B,C,D),其数据依赖集:F={(A,B)→C,C→D},则关系模式R的规范化程度最高达到【2NF】
- 下列关于函数依赖的叙述中,哪一条是不正确的【由X→YZ,则X→Y, Y→Z】,正确的是【由X→Y,Y→Z,则X→YZ】【由X→Y,WY→Z,则XW→Z 】【由X→Y,Z∈Y,则X→Z】
- X→Y,当下列哪一条成立时,称为平凡的函数依赖【Y∈X】
- 关系数据库的规范化理论指出:关系数据库中的关系应该满足一定的要求,最起码的要求是达到1NF,即满足【每个属性都是不可分解的】
- 根据关系数据库规范化理论,关系数据库中的关系要满足第一范式,部门(部门号,部门名,部门成员,部门总经理)关系中,因哪个属性而使它不满足第一范式【部门成员】
- 有关系模式A(C,T,H,R,S),其中各属性的含义是:
- C:课程 T:教员 H:上课时间 R:教室 S:学生
- 根据语义有如下函数依赖集:
- F={C→T,(H,R)→C,(H,T)RC,(H,S)→R}
- 关系模式A的码是【(H,S)】
- 关系模式A的规范化程度最高达到【2NF】
- 现将关系模式A分解为两个关系模式A1(C,T),A2(H,R,S),则其中A1的规范化程度达到【BCNF】
- 数据库外模式在【数据库逻辑结构设计】阶段设计
- 生成DBMS系统支持的数据模型在【数据库逻辑结构设计】阶段完成
- 根据应用需求建立索引在【数据库物理设计】阶段完成
- 员工性别取值“男”女”/“1”“0”属于【属性冲突】
- 数据库设计方法包括【新奥尔良方法】【基于E-R模型的方法】【3NF的设计方法】【面向对象的设计方法】【统一建模语言(UML)方法】
- 数据库设计的基本步骤包括【需求分析】【概念结构设计】【逻辑结构设计】【物理结构设计】【数据库实施】【数据库运行和维护】
- 集成E-R图要分两个步骤【合并、修改】和【重构】
- 数据库常见存取方法【索引】【聚簇】【Hash方法】
- 在进行概念结构设计时,将事物作为属性的基本准则是什么
- 作为属性,不能再具有需要描述的性质,属性必须是不可分的数据项,不能包含其他属性
- 属性不能与其他实体具有联系,即E-R图中所表示的联系是实体之间的联系
- 将E-R图转换为关系模式时,可以如何处理实体型间的联系
- 1.