什么是Service Mesh?
Service Mesh是一种用来在分布式应用程序的不同组件之间共享数据的平台。要理解Service Mesh,必须要理解三个问题:
- 为什么要构建分布式应用程序?
- 不同组件之间共享数据有什么挑战?
- Service Mesh如何解决这些挑战?
Cloud Native 云原生
Cloud Native是设计分布式应用的一种Best Practice。我们可以试图从理解Cloud Native来对分布式应用有一个更直观的了解。根据CNCF(Cloud Native Computing Foundation)的定义,Cloud Native是指在云上构建可弹性扩展,易于管理和监控,松耦合的应用。从实际场景来看,一个Cloud Native应用通常有以下特征:
- 应用的各个组件独立存在、演进,并通过某种服务发现方式找到彼此
- 应用的各个组件通过API(例如REST,gRPC)来交互合作
- 应用的各个组件并不要求使用同一种编程语言开发,不绑定操作系统
- 应用的各个组件封装在轻量容器中,并且不绑定服务器(除非对特定的硬件有需求,例如SSD, GPU)
- 整个应用部署在弹性的云基础架构上,并且支持自动管理和策略驱动
一个Cloud Native应用如下图所示,应用的每个组件有时也被称为Microservice(微服务)。
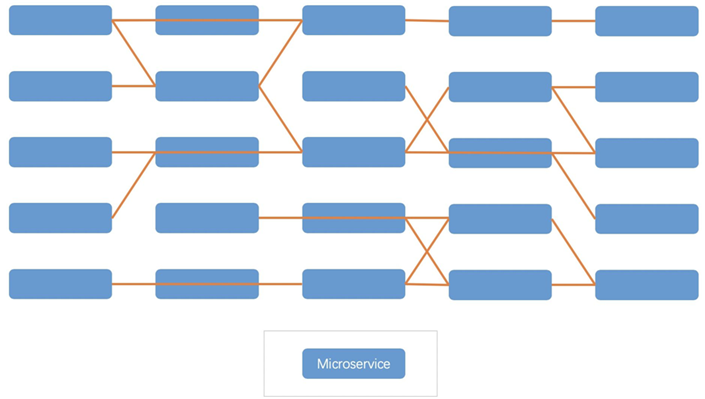
分布式应用相比集中式应用来说有很多优点,比如:
- 更敏捷。应用程序每个微服务可以由不同的团队开发,每个微服务甚至可以用不同的编程语言来开发。
- 易于水平扩展。集中式应用的扩展通常只能增加服务器的资源(垂直扩展),但是一方面服务器的配置最终会有上限,另一方面增加单个服务器资源性价比较低。而分布式应用只需要在更多小型机服务器上运行相应的微服务就可以完成扩展。
- 更好的隔离性。每个微服务的数据都是相对独立,并且每个微服务都是个独立的错误域。
尽管有以上优点,分布式应用同样的也带来了一些问题。并且这些问题随着分布式应用规模变大,相应的会变得更加严重:
- 更加复杂。应用程序单个微服务可能比较简单,但是组合起来之后会比同等的集中式应用更复杂。
- 数据一致性。每多拆分一个微服务,就要考虑这个微服务的数据是否始终正确以及如何保持正确。这在实际开发中是个比较头疼的问题。
- 管理和发布。应用程序的每个微服务都是独立开发,这就需要不同的发布和管理策略。
- 网络管理更加复杂。应用程序拆分成多个微服务之后,如上图所示,会导致更多的跨服务器交互,使得网络传输更加复杂,负载更大;另一方面服务链变长以后,例如A访问B,B再访问C,会增加额外的延时。
那如何解决分布式应用带来的问题?对于使用分布式架构的场景,可以借助一些容器的编排工具,例如Kubernetes,在发布管理,复杂性上缓解分布式应用带来的问题。但是涉及到网络,原生Kubernetes也没有提供一个有效的解决方案。
Service Mesh
回到最开始,Service Mesh是一种用来在分布式应用程序的不同组件之间共享数据的平台。如果只是共享数据,那有一万种方法。Service Mesh的特点在于,它可以用来解决分布式应用的各个微服务组件之间,复杂的网络管理问题。具体有哪些问题呢?
Service Discovery
分布式应用的不同组件很大概率是运行在不同的主机上,各个组件之间需要交互数据,那必须要知道彼此的位置。但是考虑到灵活性和扩展性,某个组件通常不会固定在某个或者某一些固定的服务器上,也就是组件或者微服务的位置可能会“飘”。这里就需要有某种机制来确定组件的实际位置。
传统上来说,这是DNS或者Load Balancer的工作。例如,DNS接收一个域名,返回对应的IP地址,服务的位置迁移需要更新DNS的域名和IP地址对应记录。又例如,Load Balancer暴露一个VIP,再将发送到VIP的请求转发到后端提供服务的Real Server,服务的位置迁移需要更新Load Balancer中Real Server的记录。DNS和Load Balancer 都以某种形式屏蔽了服务位置的变化,Client只需要管理一个统一的查询接口即可。
然而,在大规模的分布式应用中,因为组件数量较多,关系也更复杂,同样的问题会更加复杂。比如,组件A需要与多个组件B通信,为了考虑负载分担可以用一个Load Balancer来管理组件B。但是当类似的组件数量变多时,为每一个组件都添加独立的Load Balancer显得过于复杂且不切实际。在这种场景下需要做client-side LB,也就是组件A需要自己考虑如何完成到组件B的负载分担。为了实现这个目标,组件A需要确切的知道组件B在什么位置,哪些位置的还可以正常提供服务,对应的负载是多少。再比如,某个组件是多机房部署,那其他组件在使用该组件的时候,预期是优先使用同机房的组件。
所有的这些需求使得传统的DNS和LB不再能满足需求。现在需要一个更加灵活的Service Discovery机制,它接收各种查询条件,并返回满足查询条件的组件位置和其他信息。例如组件A,要查询版本号是1的组件B,通过Service Discovery就可以找到组件B的位置,进而与B进行数据交互。
Circuit Breaker
熔断机制(Circuit Breaker),是一种应用程序的保护机制。它是指,当某个微服务返回的失败达到一定阈值时,其他微服务在访问它的时候,Client端微服务直接生成错误,而不实际将请求发送到Server端微服务。这样可以避免已经过载的微服务承受更多的负载。一个微服务过载,除了本身的计算能力超载以外,还包括一些网络因素。下面是一些可能影响微服务可用性的网络因素:
- 网络传输存在延时
- 网络带宽是有限的
- 尽管有TCP/IP协议栈的存在,但是因为种种因素的存在,网络不一定是稳定的
Circuit Breaker可以避免向已经拥挤的网络里面增加更多不必要(因为大概率注定是失败)的请求。
解决问题
要解决这些问题,也并不是一定要依赖Service Mesh。至少有以下几种方式:
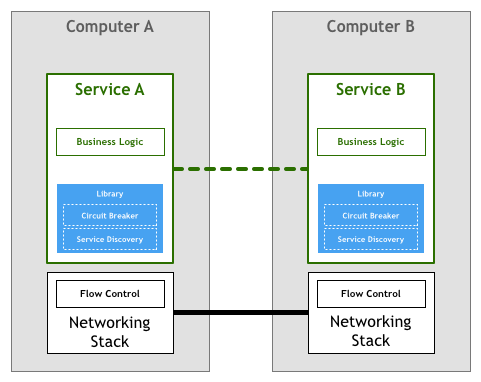
(1)可以在各个微服务中编写程序来各自解决这些问题,如下图所示。但是一方面Service Discovery和Circuit Breaker实现起来并不简单;另一方面,这并不是业务逻辑,在微服务中实现的话增加了开发的难度和工作量,相当于每个微服务都需要重复造”轮子“。

(2)为了避免重复造轮子,可以将Service Discovery和Circuit Breaker以Library的形式封装起来。这样不同的微服务可以直接调用Library来处理微服务组件之间的数据交互,如下图所示。这种方式的问题在于,微服务的开发现在受限于Library的编程语言限制,而Cloud Native的原则是可以使用不同的编程语言开发不同的微服务。
Service Mesh
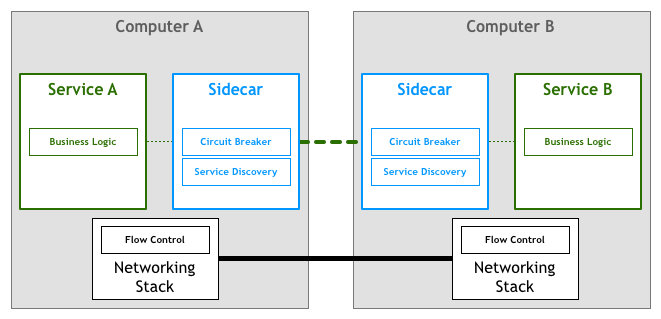
Service Mesh的做法是,为每个微服务提供一个proxy,在这个proxy里面实现了Service Discovery和Circuit Breaker。所有的微服务之间数据通信通过proxy完成。这样,微服务本身可以更加关注业务逻辑,并且proxy独立于微服务运行,使得微服务不依赖于proxy的实现,微服务仍然可以任意方式进行开发。如下图所示。通常,这个proxy被称为sidecar。
所以,在引入Service Mesh之后,一个分布式应用如下图所示。Service Mesh专门用来解决分布式应用不同组件之间数据共享的问题。
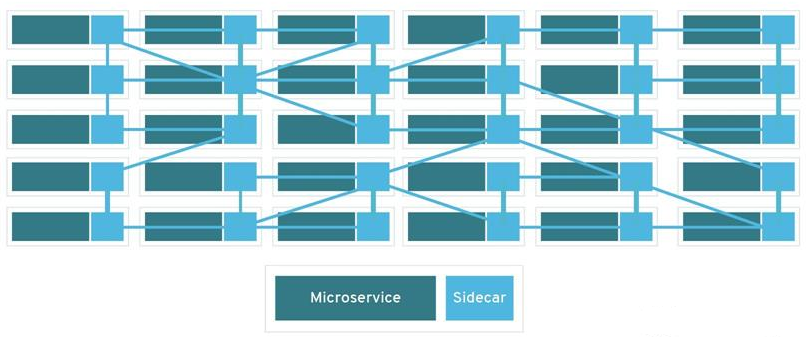
如果抛开微服务本身,只看sidecar,如下图所示,这就是一个mesh网络。这是Service Mesh名字的由来。
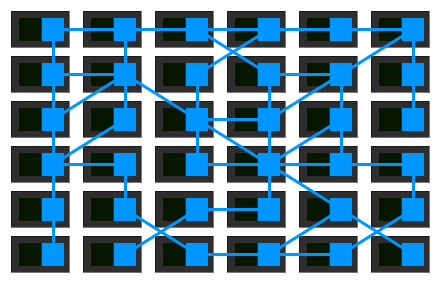
Service Mesh通常由控制面和数据面组成。数据面由伴随着微服务运行的sidecar组成;控制面是用来配置,监控,展示数据面网络流量的一组程序。如果你对SDN架构比较了解,你会发现,这里的架构与SDN架构一模一样。细节上来看,SDN的数据面是一个个的网络转发设备,网络转发设备处理的是workload(服务器,虚拟机,容器)的网络数据转发。而Service Mesh的数据面是一个个sidecar应用程序,sidecar处理的是微服务的网络数据转发。SDN更侧重于2-4层的网络数据的控制和转发,而Service Mesh更侧重于应用程序级别的数据控制和转发。
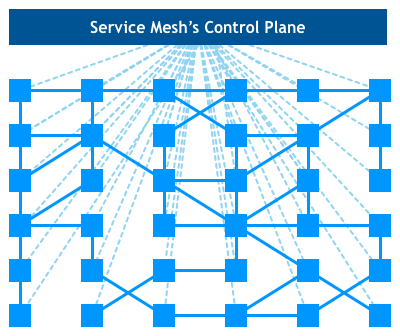
实际应用
现实中,有多个项目实现了Service Mesh。目前应用的最广泛的就是Istio。Istio使用另一个项目Enovy作为sidecar的实现。当Istio与Kubernetes一起用来构建Cloud Native应用时,sidecar本身作为Kubernetes Pod中的一个容器运行。因为Kubernetes的Pod本身就是多个容器共享一个网络空间构成,这样尽管使用了Service Mesh,从集群角度来看,网络通信还是发生在Pod之间。并且不需要再部署上做太多额外的工作。
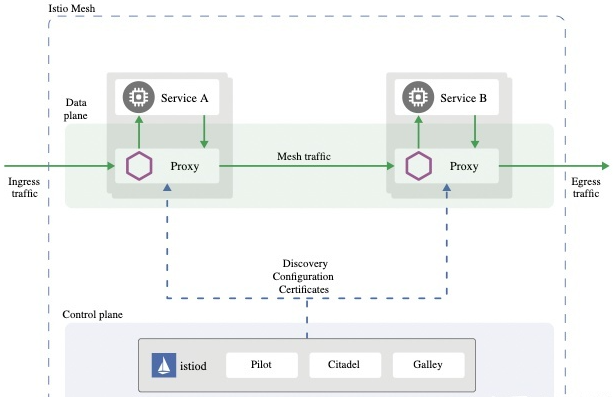
除了基本的微服务之间数据共享之外,由于所有的微服务之间网络流量都经过Sidecar转发,Istio可以提供更多的功能,使得一个分布式Cloud Native应用的运维和管理更加简单。例如:微服务流量管理,微服务之间的安全认证,微服务之间的流量策略,微服务的监控日志等等。