序:ActiveMQ高性能方案的不足
那么有的读者可能会问,既然ActiveMQ的高性能方案中多个节点同时工作,在某个节点异常的情况下也不会影响其他节点的工作。这样看来,ActiveMQ的高性能方案已经避免了单点故障,那么我们为什么还需要讨论ActiveMQ的高可用方案呢?
为了回答这个问题,我们先回过头来看看ActiveMQ高性能方案的一些不足。假设如下的场景:ActiveMQ A和AcitveMQ B两个服务节点已建立了Network Bridge;并且Producer1 连接在ActiveMQ A上,按照一定周期发送消息(队列名:Queue/testC);但是当前并没有任何消费者Consumer连接在任何ActiveMQ服务节点上接收消息。整个场景如下图所示:
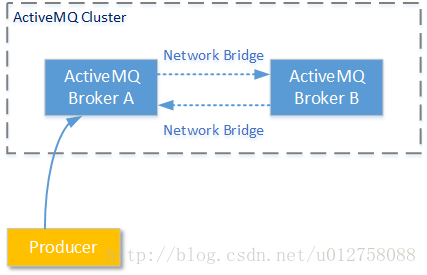
在发送了若干消息后,我们查看两个节点ActiveMQ服务节点的消息情况,发现ActiveMQ A并没有把队列Queue/testC中的消息同步到ActiveMQ B。原来AcitveMQ Network Bridge的工作原则是:只在服务节点间传输需要传输的消息,这样做的原因是为了尽量减少AcitveMQ集群网络中不必要的数据流量。在我们实验的这种情况下并没有任何消费者在任何ActiveMQ服务节点上监听/订阅队列Queue/testC中的消息,所以消息并不会进行同步。
那么这样的工作机制带来的问题是,当没有任何消费者在任何服务节点订阅ActiveMQ A中队列的消息时,一旦ActiveMQ A由于各种异常退出,后来的消费者就再也收不到消息,直到ActiveMQ A恢复工作。所以我们需要一种高可用方案,让某一个服务节点能够7 * 24小时的稳定提供消息服务。
ActiveMQ 热备方案
1、基于共享文件系统的热备方案
1.1、方案介绍
基于共享文件系统的热备方案可以说是ActiveMQ消息中间件中最早出现的一种热备方案。它的工作原理很简单:让若干个ActiveMQ服务节点,共享一个文件系统。当某一个ActiveMQ服务抢占到了这个文件系统的操作权限,就给文件系统的操作区域加锁;其它服务节点一旦发现这个文件系统已经被加锁(并且锁不属于本进程),就会自动进入Salve模式。
ActiveMQ早期的文件存储方案、KahaDB存储方案、LevelDB存储方案都支持这个工作模式。当某个ActiveMQ节点获取了文件系统的操作权限后,首先做的事情就是从文件系统中恢复内存索引结构:KahaDB恢复BTree结构;LevelDB恢复memTable结构。
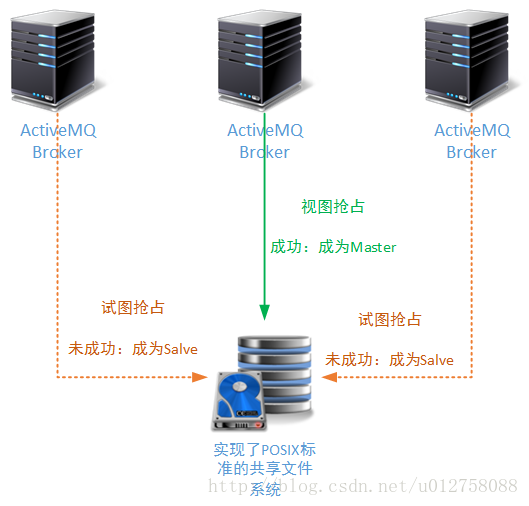
因为本专题讲解的技术体系都是工作在Linux操作系统上,所以为多个ActiveMQ提供共享文件系统方案的第三方文件系统都必须支持POSIX协议,这样Linux操作系统才能实现远程挂载。
幸运的是,这样的第三方系统多不胜举,例如:基于网络文件存储的NFS、NAS;基于对象存储的分布式文件系统Ceph、MFS、Swift(不是ios的编程语言)、GlusterFS(高版本);以及ActiveMQ官方推荐的网络块存储方案:SAN(就是成本有点高)。
我会在我另外一个专题——“系统存储”中,和大家深入讨论这些存储方案在性能、维护、扩展性、可用性上的不同。为了讲解简单,我们以下的讲解采用NFS实现文件系统的共享。NFS技术比较成熟,在很多业务领域都有使用案例。如果您的业务生产环境还没有达到滴滴、大众点评、美团那样对文件存储性能上的要求,也可以将NFS用于生产环境。
1.2、实例参考
下面我们来演示两个ActiveMQ节点建立在NFS网络文件存储上的 Master/Salve方案。关于怎么安装NFS软件就不进行介绍了,毕竟本部分内容的核心还是消息服务中间件,不清楚NFS安装的读者可以自行百度/Google。
以下是我们演示环境中的IP位置和功能:
| IP位置 | 作用 |
|---|---|
| 192.168.61.140 | NFS文件服务 |
| 192.168.61.139 | 独立的 ActiveMQ 节点 |
| 192.168.61.138 | 另一个独立的 ActiveMQ 节点 |
1)首先为两个ActiveMQ节点挂载NFS服务:
-- 在140上设置的NFS共享路径为/usr/nfs 挂载到139和138的/mnt/mfdir/路径下
-- 139和138上记得要安装nfs-utils的客户端模块
mount 192.168.61.140:/usr/nfs /mnt/mfdir/挂载后,可以通过df命令查询挂载在后的结果:
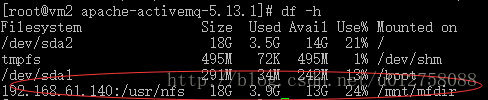
从上图中可以看到,192.168.61.140上提供的NFS共享目录通过mount命令挂载成为了138和139两个物理机上的本地磁盘路径。
2)然后更改138和139上ActiveMQ的主配置文件,主要目的是将使用的KahaDB/LevelDB的主路径设置为在共享文件系统的相同位置:
......
<persistenceAdapter>
<!--
这里使用KahaDB,工作路径设置在共享路径的kahaDB文件夹下
138和139都设置为相同的工作路径
-->
<kahaDB directory="/mnt/mfdir/kahaDB"/>
</persistenceAdapter>
......- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3)然后同时启动138和139上的ActiveMQ服务节点。这时我们可以看到某个节点出现以下的提示信息(记得是通过console模式进行观察):
......
jvm 1 | INFO | Using Persistence Adapter: KahaDBPersistenceAdapter[/mnt/mfdir/kahaDB]
jvm 1 | INFO | Database /mnt/mfdir/kahaDB/lock is locked by another server. This broker is now in slave mode waiting a lock to be acquired
......- 1
- 2
- 3
- 4
在本文的演示环境中,出现以上提示的是工作在139上的ActiveMQ服务节点。这说明这个节点发现主工作路径已经被其他ActiveMQ服务节点锁定了,所以自动进入了Slave状态。另外这还说明,另外运行在138物理机上的ActiveMQ服务抢占到了主目录的操作权。
接下来我们将工作在138上的ActiveMQ服务节点停止工作,这时139上的ActiveMQ Slave服务节点自动切换为Master状态:
......
jvm 1 | INFO | KahaDB is version 6
jvm 1 | INFO | Recovering from the journal @1:47632
jvm 1 | INFO | Recovery replayed 53 operations from the journal in 0.083 seconds.
jvm 1 | INFO | PListStore:[/usr/apache-activemq-5.13.1/bin/linux-x86-64/../../data/activemq2/tmp_storage] started
jvm 1 | INFO | Apache ActiveMQ 5.13.1 (activemq2, ID:vm2-46561-1461220298816-0:1) is starting
......- 1
- 2
- 3
- 4
- 5
- 6
- 7
从以上的提示可以看到,139上的ActiveMQ节点在自己的内存区域恢复了KahaDB的索引信息,并切换为Master状态继续工作。需要注意的是,在139上的ActiveMQ节点切换为Master状态后,就算之前138上的ActiveMQ节点重新恢复工作,后者也不会再获得主目录的操作权限,只能进入Salve状态。
2、基于共享关系型数据库的热备方案
基于关系型数据库的热备方案它的工作原理实际上和基于共享文件系统的热备方案相似:
首先使用关系型数据库作为ActiveMQ的持久化存储方案时,在指定的数据库中会有三张数据表:activemq_acks,activemq_lock,activemq_msgs(有的情况下您生成的数据表名会是大写的,这是因为数据库自身设置的原因);
其中“activemq_lock”这张数据表记录了当前对数据库拥有操作权限的ActiveMQ服务的ID信息、Name信息。各个ActiveMQ服务节点从这张数据表识别当前哪一个节点是Master状态;
当需要搭建热备方案时,两个或者更多的ActiveMQ服务节点共享同一个数据服务。首先抢占到数据库服务的ActiveMQ节点,会将数据库中“activemq_lock”数据表的Master状态标记为自己,这样其它ActiveMQ服务节点就会进入Salve状态。
之前讲述了如何进行ActiveMQ服务的数据库存储方案的配置,这里就不再进行赘述。只需要将每个ActiveMQ服务节点的数据库连接设置成相同的位置,即可完成该热备方案的配置工作。
为了便于各位读者进行这种方案的配置实践,这里给出了关键的配置信息:实际上真的很简单,一定要首先确保您的数据库是可用的,并且每一个ActiveMQ节点都这样配置:
......
<broker xmlns="http://activemq.apache.org/schema/core">
......
<persistenceAdapter>
<!-- 设置使用的数据源 -->
<jdbcPersistenceAdapter dataSource="#mysql-ds"/>
</persistenceAdapter>
......
</broker>
......
<!-- 一定要确保数据库可用,且在ActiveMQ的lib目录中有必要的jar文件 -->
<bean id="mysql-ds" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://您的mysql连接url信息?relaxAutoCommit=true"/>
<property name="username" value="activemq"/>
<property name="password" value="activemq"/>
<property name="poolPreparedStatements" value="true"/>
</bean>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
3、LevelDB + Zookeeper的热备方案
从ActiveMQ V5.9.0+ 版本开始,ActiveMQ为使用者提供了一种新的Master/Salve热备方案。这个方案中,我们可以让每个节点都有自己独立的LevelDB数据库(不是像1小节那样共享LevelDB的工作目录),并且使用Zookeeper集群控制多个ActiveMQ节点的工作状态,完成Master/Salve状态的切换。工作模式如下图所示(摘自官网):
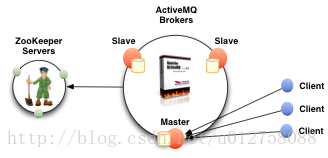
在这种新的工作模式下,Master节点和各个Salve节点通过Zookeeper进行工作状态同步,即使某个Salve节点新加入也没有问题。下面我们一起来看看如何使用LevelDB + Zookeeper的热备方案。下表中是我们将要使用的IP位置和相关位置的工作任务:
| IP位置 | 作用 |
|---|---|
| 192.168.61.140 | 单节点状态的zookeeper服务 |
| 192.168.61.139 | 独立的 ActiveMQ 节点 |
| 192.168.61.138 | 另一个独立的 ActiveMQ 节点 |
在这里的演示实例中我们使用单节点的ZK工作状态(但是正式生产环境中,建议至少有三个zookeeper节点)。
1)首先更改139和138上工作的ActiveMQ服务节点,让它们使用独立的LevelDB,并且都连接到zookeeper服务。
......
<!--
注意无论是master节点还是salve节点,它们的brokerName属性都必须一致
否则activeMQ集群就算连接到了zookeeper,也不会把他们当成一个Master/Salve组
-->
<broker xmlns="http://activemq.apache.org/schema/core" brokerName="activemq" dataDirectory="${activemq.data}">
......
<persistenceAdapter>
<replicatedLevelDB
directory="/usr/apache-activemq-5.13.1/data/levelDB"
replicas="1"
bind="tcp://0.0.0.0:61615"
zkAddress="192.168.61.140:2181"
zkPath="/activemq/leveldb"/>
</persistenceAdapter>
......
</broker>
......- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
我们介绍一下以上配置段落所使用的一些重要属性。通过LevelDB + Zookeeper组建的热备方案中肯定会有一个ActiveMQ节点充当Master节点,至于有多少个Salve节点就可以根据读者所在团队、项目、需求等因素来综合考虑了。这些Master节点和Salve节点的主配置文件中设置的brokerName属性必须一致,否则activeMQ集群就算连接到了zookeeper,也不会把他们当成一个Master/Salve组。
directory属性是LevelDB的基本设置,表示当前该节点使用的LevelDB所在的主工作目录,由于每个节点都有其独立运行的LevelDB,所以各个节点的directory属性设置的目录路径可以不一样。但是根据对正式环境的管理经验,建议还是将每个节点的directory属性设置成相同的目录路径,方便进行管理。
对于replicas属性,官方给出的解释如下:
The number of nodes that will exist in the cluster. At least (replicas/2)+1 nodes must be online to avoid service outage.(default:3)
这里的“number of nodes”包括了Master节点和Salve节点的总和。换句话说,如果您的集群中一共有3个ActiveMQ节点,且只允许最多有一个节点出现故障。那么这里的值可以设置为2(当然设置为3也行,因为整型计算中 3 / 2 + 1 = 2)。但如果您将replicas属性设置为4,就代表不允许3个节点的任何一个节点出错,因为:(4 / 2) + 1 = 3,也就是说3个节点是本集群能够允许的最小节点数。
一旦zookeeper发现当前集群中可工作的ActiveMQ节点数小于所谓的“At least (replicas/2)+1 nodes”,在ActiveMQ Master节点的日志中就会给出提示:“Not enough cluster members connected to elect a master.”,然后整个集群都会停止工作,直到有新的节点连入,并达到所规定的“At least (replicas/2)+1 nodes”数量。
bind属性指明了当本节点成为一个Master节点后,通过哪一个通讯位置进行和其它Salve节点的消息复制操作。注意这里配置的监听地址和端口不能在transportConnectors标签中进行重复配置,否则节点在启动时会报错。
When this node becomes a master, it will bind the configured address and port to service the replication protocol. Using dynamic ports is also supported.
zkAddress属性指明了连接的zookeeper服务节点所在的位置。在以上实例中由于我们只有一个zookeeper服务节点,所以只配置了一个位置。如果您有多个zookeeper服务节点,那么请依次配置这些zookeeper服务节点的位置,并以“,”进行分隔:
zkAddress="zoo1.example.org:2181,zoo2.example.org:2181,zoo3.example.org:2181"- 1
由于zookeeper服务使用树形结构描述数据信息,zkPath属性就是设置整个ActiveMQ 主/备方案集群在zookeeper存储数据信息的根路径的位置。当然这个属性有一个默认值“/default”,所以您也可以不进行设置。
- 在完成138和139两个节点的ActiveMQ服务配置后,我们同时启动这两个节点(注意,为了观察ActiveMQ的日志请使用console模式启动)。在其中一个节点上,可能会出现以下日志信息:
......
jvm 1 | INFO | Opening socket connection to server 192.168.61.140/192.168.61.140:2181
jvm 1 | INFO | Socket connection established to 192.168.61.140/192.168.61.140:2181, initiating session
jvm 1 | INFO | Session establishment complete on server 192.168.61.140/192.168.61.140:2181, sessionid = 0x1543b74a86e0002, negotiated timeout = 4000
jvm 1 | INFO | Not enough cluster members have reported their update positions yet.
jvm 1 | INFO | Promoted to master
jvm 1 | INFO | Using the pure java LevelDB implementation.
jvm 1 | INFO | Apache ActiveMQ 5.13.1 (activemq, ID:vm2-45190-1461288559820-0:1) is starting
jvm 1 | INFO | Master started: tcp://activemq2:61615
......- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
从以上的日志可以看到,这个节点连接上了zookeeper,并且分析了当前zookeeper上已连接的其它节点状态后(实际上这个时候,还没有其它节点进行连接),将自己“提升为Master”状态。在另外一个AcitveMQ的节点日志中,读者可以发现另一种形式的日志提示,类似如下:
......
jvm 1 | INFO | Opening socket connection to server 192.168.61.140/192.168.61.140:2181
jvm 1 | INFO | Socket connection established to 192.168.61.140/192.168.61.140:2181, initiating session
jvm 1 | INFO | Session establishment complete on server 192.168.61.140/192.168.61.140:2181, sessionid = 0x1543b74a86e0005, negotiated timeout = 4000
jvm 1 | INFO | Slave started
......- 1
- 2
- 3
- 4
- 5
- 6
从日志中可以看到,这个节点成为了一个Slave状态的节点。
- 接下来我们尝试停止当前Master节点的工作,并且观察当前Salve节点的状态变化。注意,如上文所述,replicas属性的值一定要进行正确的设置:如果当Master节点停止后,当前还处于活动状态的节点总和小于“(replicas/2)+1”,那么整个集群都会停止工作!
......
jvm 1 | INFO | Not enough cluster members have reported their update positio ns yet.
jvm 1 | INFO | Slave stopped
jvm 1 | INFO | Not enough cluster members have reported their update positio ns yet.
jvm 1 | INFO | Promoted to master
jvm 1 | INFO | Using the pure java LevelDB implementation.
jvm 1 | Replaying recovery log: 5.364780% done (956,822/17,835,250 bytes) @ 1 03,128.23 kb/s, 0 secs remaining.
jvm 1 | Replaying recovery log: 9.159451% done (1,633,611/17,835,250 bytes) @ 655.68 kb/s, 24 secs remaining.
jvm 1 | Replaying recovery log: 23.544615% done (4,199,241/17,835,250 bytes) @ 2,257.21 kb/s, 6 secs remaining.
jvm 1 | Replaying recovery log: 89.545681% done (15,970,696/17,835,250 bytes) @ 11,484.08 kb/s, 0 secs remaining.
jvm 1 | Replaying recovery log: 100% done
jvm 1 | INFO | Master started: tcp://activemq1:61615
......- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
从以上的日志片段可以看到,Salve节点接替了之前Master节点的工作状态,并恢复之前已同步的LevelDB文件到本节点的本地内存中,继续进行工作。
我们在这篇文章做的演示只有两个ActiveMQ服务节点和一个Zookeeper服务节点,主要是为了向读者介绍ActiveMQ下 LevelDB + Zookeeper的高可用方案的配置和切换过程,说明ActiveMQ高可用方案的重要性。实际生产环境下,这样的节点数量配置会显得很单薄,特别是zookeeper服务节点只有一个的情况下是不能保证整个集群稳定工作的。正式环境下, 建议至少使用三个zookeeper服务节点和三个ActiveMQ服务节点,并将replicas属性设置为2。
4、ActiveMQ客户端的故障转移
以上三种热备方案,都已向各位读者介绍。细心的读者会发现一个问题,因为我们没有使用类似Keepalived那样的第三方软件支持浮动IP。那么无论以上三种热备方案的哪一种,虽然服务端可以无缝切换提供连续的服务,但是对于客户端来说连接服务器的IP都会发生变化。也就是说客户端都会因为连接异常脱离正常工作状态。
为了解决这个问题,AcitveMQ的客户端连接提供了配套的解决办法:连接故障转移。开发人员可以预先设置多个可能进行连接的IP位置(这些位置不一定同时都是可用的),ActiveMQ的客户端会从这些连接位置选择其中一个进行连接,当连接失败时自动切换到另一个位置连接。使用方式类似如下:
......
//这样的设置,即使在发送/接收消息的过程中出现问题,客户端连接也会进行自动切换
ActiveMQConnectionFactory connectionFactory = new ActiveMQConnectionFactory("failover:(tcp://192.168.61.138:61616,tcp://192.168.61.139:61616)");
......- 1
- 2
- 3
- 4
这样的连接设置下,客户端的连接就可以随服务端活动节点的切换完成相应的转换。
5、形成生产环境方案
ActiveMQ中主要的高性能、高可用方案到此就为各位读者介绍完了。可以看到在ActiveMQ单个节点性能配置已优化的前提下,ActiveMQ集群的高性能方案可能会出现节点失效消息服务停止的情况;而ActiveMQ集群的高可用性方案中,由于一次只有一个节点是Master状态可以提供消息服务外,其他Salve节点都不能提供服务,所以并不能提高整个ActiveMQ集群的性能。
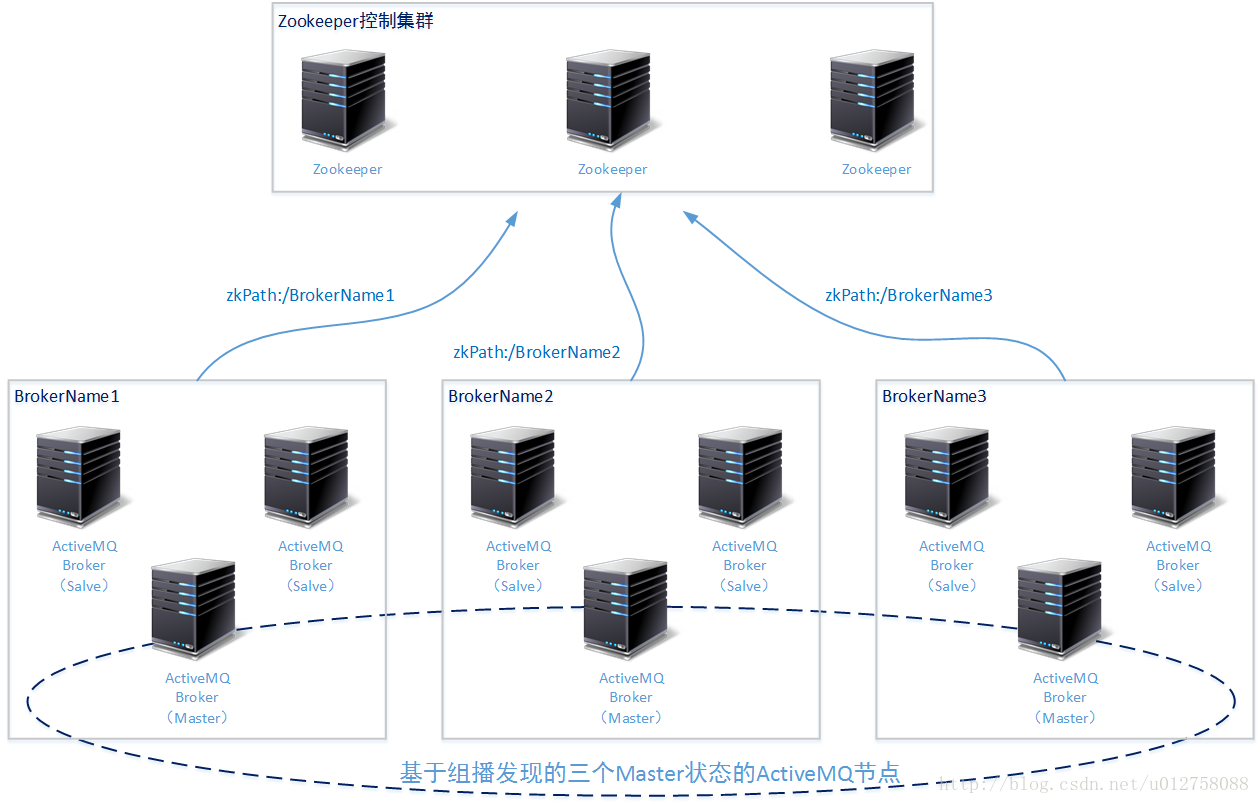
因为两种方案都有其限制因素,所以在实际工作中将ActiveMQ应用到生产环境时,除非您的业务环境有特殊要求的情况,一般建议将ActiveMQ的高性能方案和高可用方案进行结合。以下向各位读者提供一种ActiveMQ高性能和高可用性结合的方案:
将9个ActiveMQ节点分为三组(brokerName1、brokerName2、brokerName3),每组都有三个ActiveMQ服务节点。另外准备三个节点的zookeeper服务集群,所有三个组九个ActiveMQ服务都共享这三个zookeeper服务节点(只是每组ActiveMQ所设置的zkPath属性不一样);
将每组的三个ActiveMQ服务节点做LevelDB + Zookeeper的热备方案(且设置replicas=2)。保证每组只有一个节点在一个时间内为Master状态。这样整个集群中的九个ActiveMQ服务节点就同时会有三个ActiveMQ服务节点处于Master状态;
将整个集群中所有ActiveMQ服务节点的高性能方案设置为“组播发现”,并都采用一个相同的组播地址(可以采用默认的组播地址)。这样三个处于Master状态的ActiveMQ服务节点就会形成一个高性能方案(处于Salve状态的节点不会发出组播消息)。整个设计结构如下图所示: