一、MySQL体系结构和存储引擎
尽管各个平台在底层(如线程)实现方面都各不相同,但MySQL基本上能保证在各个平台上的物理结构的一致性。因此,用户应该能很好的理解MySQL数据库在所有这些平台是如何运作的。
1.1 定义数据库和实例
数据库:物理操作系统文件或其他形式文件类型的集合。在MySQL数据库中,数据库文件可以是frm、myd、myi、ibd文件。NDB引擎,是存放于内存之中的文件,但定义不变。
实例:MySQL数据库由后台线程以及一个共享内存区组成。共享内存可以被运行的后台线程所共享。在集群情况下,可能存在一个数据库被多个数据实例使用的情况。
从概念上来讲,数据库是文件的集合,是按照某种数据模型组织起来并存放于二级存储器中的数据集合。
数据库实例是程序,是位于用户与操作系统之间的一层数据管理软件,用户对数据库数据的任何操作,包括数据库定义、数据查询、数据维护、数据库运行控制等都是在数据库实例下进行的,应用程序只有通过数据库实例才能和数据库打交道。
MySQL 是一个单进程多线程架构的数据库。
MySQL 数据库是按照 /etc/my.cnf -> /etc/myssql/my.cnf -> /usr/local/mysql/etc/my.cnf -> ~/.my.cnf 的顺序读取配置文件的。
如果几个配置文件中有相同的参数,MySQL数据库以最后读取到的一个配置文件中的参数为准。
1.2 MySQL 体系结构
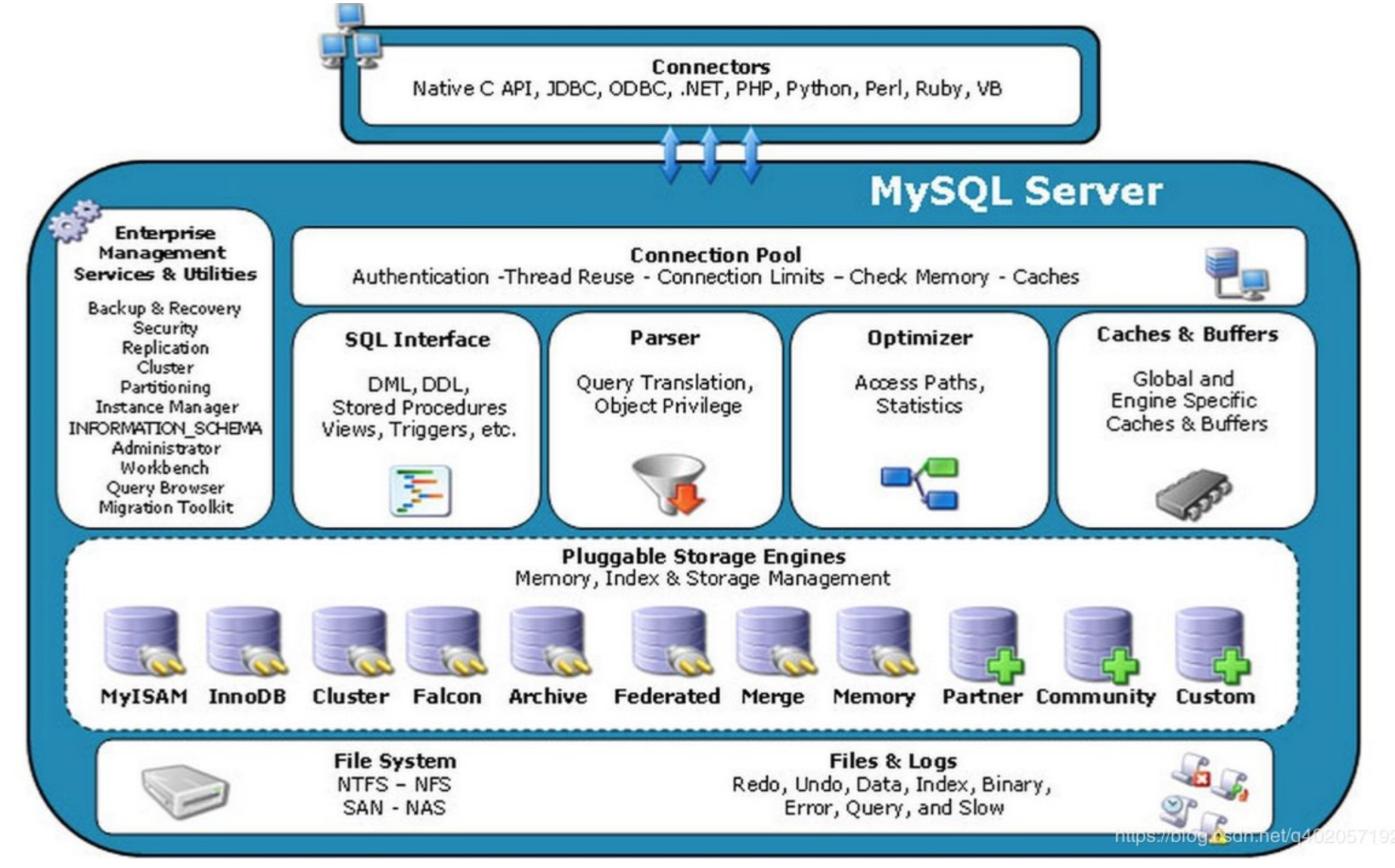
由图可知,MySQL由以下几部分组成:
- 连接池组件
- 管理服务和工具组件
- SQL接口组件
- 查询分析器组件
- 优化器组件
- 缓冲(Cache)组件
- 插件式存储引擎
- 物理文件
MySQL区别于其他数据库的最重要的一个特点就是插件式的表存储引擎,注意,存储引擎是基于表的。
1.3 MySQL存储引擎
1.3.1 InnoDB 存储引擎
其设计目标主要是面向在线事务处理(OLTP)的应用。其特点是支持事务、行锁设计、支持外键、非锁定读(MVCC,即默认读取操作不会产生锁)。在MySQL5.5.8以后,InnoDB是默认的存储引擎。
InnoDB通过使用多版本并发控制(MVCC)来获得高并发,并实现了四种隔离级别,默认是 REPEATABLE级别
使用next-key locking 的策略来避免幻读现象
提供了插入缓冲(insert buffer)、二次写(double write)、自适应哈希索引(adaptive hash index)、预读(read ahead)等高性能和高可用的功能
对表中的数据采用聚集(clustered)方式,因此每张表都是按照主键的顺序进行存放,如果没有在表定义中指定主键,InnoDB存储引擎将会为每一行生成一个6字节的ROWID,并以此作为主键。
1.3.2 MyISAM存储引擎
不支持事务、表锁设计、支持全文索引,主要面向OLAP应用
MySQL 5.5.8 之前的默认存储引擎
缓冲池只缓存索引文件,不缓存数据文件。数据文件由操作系统本身来完成
1.3.3 NDB 存储引擎数据
省略
1.5 链接 MySQL
连接 MySQL操作是一个连接进程和MySQL数据库实例进行通信。从程序设计的角度的来看,本质是进程通信。常见的进程通信方式有
管道、命名管道、命名字、TCP/IP套接字、UNIX域套接字。
1.5.1 TCP/IP 通信
这种方式在 TCP/IP 连接上建立一个基于网络的连接请求,一般情况下,客户端在一台服务器,而MySQL实例(服务端)在另一台服务器,机器之间通过 TCP/IP 进行网络连接。
在通过TCP/IP 连接到MySQL 实例时,MySQL 数据库会先检查一张权限视图,用来判断发起请求的客户端是否允许连接到MySQL实例。
1.5.2 命名管道和共享内存
如果两个需要进程通信的进程在同一个服务器上,那么可以使用命名管道。MySQL 4.1 之后,还提供了共享内存的连接方式。
1.5.3 UNIX 域套接字
在Linux 和 UNIX环境下,还可以使用UNIX 域套接字。UNIX 套接在不是一个协议,所以只能在 MySQL 客户端和数据库实例在同一台服务器上的情况下使用。
问题:当表的数据量大于1000万时,MySQL性能会急剧下降吗?
随着行数的增加,性能会有所下降,但并不是线性下降,如果用户选择了正确的存储引擎,正确的配置,再多的数据量MySQL也能承受。如官方手册提及的,在InnoDB存储超过1TB的数据,处理插入、更新的操作平均 800次/秒。