1 # -*- coding: utf-8 -*- 2 import requests 3 4 URL_IP = 'http://localhost:8000/ip' 5 URL_GET = 'http://localhost:8000/get' 6 7 8 def use_simple_requests(): 9 response = requests.get(URL_IP) 10 print '>>>>Response Headers:' 11 print response.headers 12 print '>>>>Response body:' 13 print response.text 14 15 16 def use_params_requests(): 17 params = {'param1': 'hello', 'param2': 'world'} 18 response = requests.get(URL_GET, params=params) 19 print '>>>>Response Headers:' 20 print response.headers 21 print '>>>>Status Code:' 22 print response.status_code 23 print '>>>>Reason:' 24 print response.reason 25 print '>>>>Request body:' 26 print response.text 27 28 if __name__ == '__main__': 29 print '>>>Use simple requests:' 30 use_simple_requests() 31 print '' 32 print '>>>Use params requests:' 33 use_params_requests()
1 # -*- coding: utf-8 -*- 2 import urllib 3 import urllib2 4 5 URL_IP = 'http://localhost:8000/ip' 6 URL_GET = 'http://localhost:8000/get' 7 8 9 def use_simple_urllib2(): 10 response = urllib2.urlopen(URL_IP) 11 print '>>>>Response Headers:' 12 print response.info() 13 print '>>>>Response body:' 14 print ''.join([line for line in response.readlines()]) 15 16 17 def use_params_urllib2(): 18 params = urllib.urlencode({'param1': 'hello', 'param2': 'world'}) 19 response = urllib2.urlopen('?'.join([URL_GET, '%s']) % params) 20 print '>>>>Response Headers:' 21 print response.info() 22 print '>>>>Status Code:' 23 print response.getcode() 24 print '>>>>Request body:' 25 print ''.join([line for line in response.readlines()]) 26 27 if __name__ == '__main__': 28 print '>>>Use simple urllib2:' 29 use_simple_urllib2() 30 print '' 31 print '>>>Use params urllib2:' 32 use_params_urllib2()
1 # -*- coding: utf-8 -*- 2 import json 3 import requests 4 from requests import exceptions 5 6 URL = 'https://api.github.com' 7 8 9 def build_uri(endpoint): 10 return '/'.join([URL, endpoint]) 11 12 13 def better_print(json_str): 14 return json.dumps(json.loads(json_str), indent=4) 15 16 17 def request_method(): 18 response = requests.get(build_uri('user/emails'), auth=('imoocdemo', 'imoocdemo123')) 19 print better_print(response.text) 20 21 22 def params_request(): 23 response = requests.get(build_uri('users'), params={'since': 11}) 24 print better_print(response.text) 25 print response.request.headers 26 print response.url 27 28 29 def json_request(): 30 # response = requests.patch(build_uri('user'), auth=('imoocdemo', 'imoocdemo123'), json={'name': 'babymooc2', 'email': 'hello-world@imooc.org'}) 31 response = requests.post(build_uri('user/emails'), auth=('imoocdemo', 'imoocdemo123'), json=['helloworld@github.com']) 32 print better_print(response.text) 33 print response.request.headers 34 print response.request.body 35 print response.status_code 36 37 38 def timeout_request(): 39 try: 40 response = requests.get(build_uri('user/emails'), timeout=10) 41 response.raise_for_status() 42 except exceptions.Timeout as e: 43 print e.message 44 except exceptions.HTTPError as e: 45 print e.message 46 else: 47 print response.text 48 print response.status_code 49 50 51 def hard_requests(): 52 from requests import Request, Session 53 s = Session() 54 headers = {'User-Agent': 'fake1.3.4'} 55 req = Request('GET', build_uri('user/emails'), auth=('imoocdemo', 'imoocdemo123'), headers=headers) 56 prepped = req.prepare() 57 print prepped.body 58 print prepped.headers 59 60 resp = s.send(prepped, timeout=5) 61 print resp.status_code 62 print resp.request.headers 63 print resp.text 64 65 if __name__ == '__main__': 66 hard_requests()
1 # -*- coding: utf-8 -*- 2 import requests 3 4 response = requests.get('https://api.github.com') 5 print "状态码,具体解释" 6 print response.status_code, response.reason 7 print "头部信息" 8 print response.headers 9 print "URL 信息" 10 print response.url 11 print "redirect 信息" 12 print response.history 13 print "耗费时长" 14 print response.elapsed 15 print "request 信息" 16 print response.request.method 17 18 print '----------------------' 19 20 print "编码信息" 21 print response.encoding 22 print "消息主体内容: byte" 23 print response.content, type(response.content) 24 print "消息主体内容: 解析" 25 print response.text, type(response.text) 26 print "消息主体内容" 27 print response.json(), type(response.json())
1 # -*- coding: utf-8 -*- 2 import requests 3 4 5 def get_key_info(response, *args, **kwargs): 6 """回调函数 7 """ 8 print response.headers['Content-Type'] 9 10 11 def main(): 12 """主程序 13 """ 14 requests.get('https://api.github.com', hooks=dict(response=get_key_info)) 15 16 main()
1 # -*- coding: utf -*- 2 import requests 3 4 5 def download_image(): 6 """demo: 下载图片, 文件 7 """ 8 headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.93 Safari/537.36'} 9 url = "http://img3.imgtn.bdimg.com/it/u=2228635891,3833788938&fm=21&gp=0.jpg" 10 response = requests.get(url, headers=headers, stream=True) 11 with open('demo.jpg', 'wb') as fd: 12 for chunk in response.iter_content(128): 13 fd.write(chunk) 14 15 16 def download_image_improved(): 17 """demo: 下载图片 18 """ 19 # 伪造headers信息 20 headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.93 Safari/537.36'} 21 # 限定url 22 url = "http://img3.imgtn.bdimg.com/it/u=2228635891,3833788938&fm=21&gp=0.jpg" 23 response = requests.get(url, headers=headers, stream=True) 24 from contextlib import closing 25 with closing(requests.get(url, headers=headers, stream=True)) as response: 26 # 打开文件 27 with open('demo1.jpg', 'wb') as fd: 28 # 每128写入一次 29 for chunk in response.iter_content(128): 30 fd.write(chunk) 31 32 download_image_improved()
session和cookie
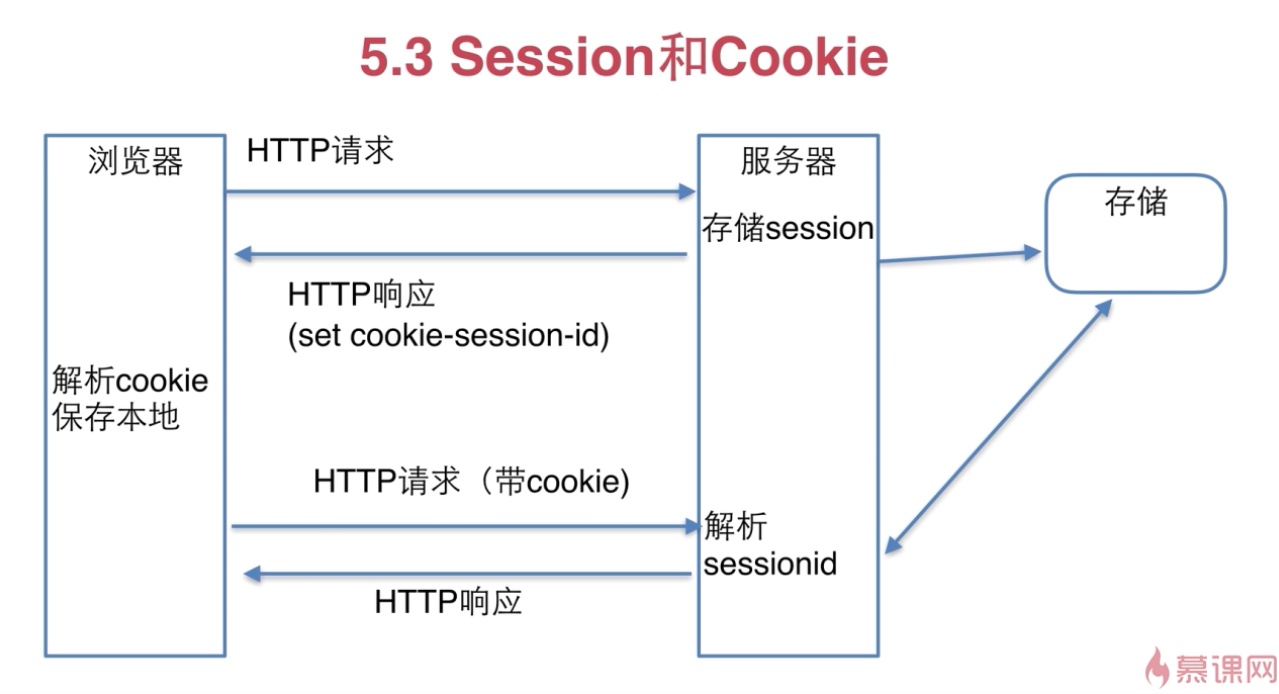

from:http://www.imooc.com/learn/736