基于HADOOP3.0+Centos7.0的yarn基础配置;
执行步骤:(1)配置集群yarn (2)启动、测试集群(3)在yarn上执行wordcount案例
一、配置yarn集群
1.配置yarn-env.sh
添加:export JAVA_HOME=/opt/module/jdk1.8.0_144
2.配置yarn-site.xml
1 <!-- reducer获取数据的方式--> 2 <property> 3 <name>yarn.nodemanager.aux-services</name> 4 <value>mapreduce_shuffle</value> 5 </property> 6 7 <!-- 指定YARN的ResourceManager的地址--> 8 <property> 9 <name>yarn.resourcemanager.hostname</name> 10 <value>hadoop101</value> 11 </property> 12 13 <!--在etc/hadoop/yarn-site.xml文件中,修改检查虚拟内存的属性为false--> 14 <property> 15 <name>yarn.nodemanager.vmem-check-enabled</name> 16 <value>false</value> 17 </property> 18 19 <!--引入hadoop路径--> 20 <property> 21 <name>yarn.application.classpath</name> 22 23 <value> 24 /opt/hadoop-2.6.0/etc/hadoop, 25 /opt/hadoop-2.6.0/share/hadoop/common/*, 26 /opt/hadoop-2.6.0/share/hadoop/common/lib/*, 27 /opt/hadoop-2.6.0/share/hadoop/hdfs/*, 28 /opt/hadoop-2.6.0/share/hadoop/hdfs/lib/*, 29 /opt/hadoop-2.6.0/share/hadoop/mapreduce/*, 30 /opt/hadoop-2.6.0/share/hadoop/mapreduce/lib/*, 31 /opt/hadoop-2.6.0/share/hadoop/yarn/*, 32 /opt/hadoop-2.6.0/share/hadoop/yarn/lib/* 33 </value> 34 </property>
3.配置:mapred-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
4.配置mapred-site.xml
<!-- 指定mr运行在yarn上--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>yarn.application.classpath</name> <value> /opt/hadoop-2.6.0/etc/hadoop, /opt/hadoop-2.6.0/share/hadoop/common/*, /opt/hadoop-2.6.0/share/hadoop/common/lib/*, /opt/hadoop-2.6.0/share/hadoop/hdfs/*, /opt/hadoop-2.6.0/share/hadoop/hdfs/lib/*, /opt/hadoop-2.6.0/share/hadoop/mapreduce/*, /opt/hadoop-2.6.0/share/hadoop/mapreduce/lib/*, /opt/hadoop-2.6.0/share/hadoop/yarn/*, /opt/hadoop-2.6.0/share/hadoop/yarn/lib/* </value> </property>
二、启动集群
1.启动hdfs集群(namenode+datanode)
2.启动yarn集群(resourceManger+nodeManager)
sbin/start-yarn.sh or pasting
yarn --daemon start resourcemanager
yarn --daemon start nodemanager
3.jps+回车 查看进程
访问 http://192.168.1.101:8088/cluster
三、运行案例
1.删除文件系统上原来的output文件
hdfs dfs -rm -R /user/atguigu/output
2.执行mapreduce程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/atguigu/input /user/atguigu/output
3.查看运行结果
hdfs dfs -cat /user/atguigu/output/*
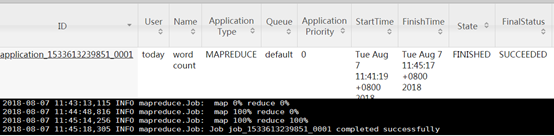

历史服务器配置
配置mapred-site.xml
<property> <name>mapreduce.jobhistory.address</name> <value>0.0.0.0:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>0.0.0.0:19888</value> </property>
启动命令:
mapred --daemon stop historyserver
or
sbin/mr-jobhistory-daemon.sh start historyserver
访问地址: http://ip:19888/jobhistory