1:自定义数据集

[注]每一个文件中对应弄干张相同种类但是不同状态的图片。比如:若干张不同状态小狗的图片。
(1.1)初始化

class Pokemon(Dataset):
def __int__(self,root,resize,mode):


【注】上图中第二张图片,sorted的位置错误,应该用在sorted(os.listdir(os.path.join(root)))
【注】os.listdir()可以将根目录下包括目录名以及文件名都列出来(注顺序是随机的)。os.path.isdir(os.path.join(root,name))判断文件名是否是目录文件名。
【注】sorted()可以对所有可迭代对象进行排序操作。sort()是针对于list的排序操作。
【注】初始化参数name2label是一个映射表(【注】其存储以字典的形式存储):将string类型的label映射成一个与之对应的编号表。例如:原始lable为[cat,dog,fish],映射成lable[0,1,2],将其对应关系以{'cat':0,'dog':1,'fish',2}字典的形式存储。
(1.2)加载数据
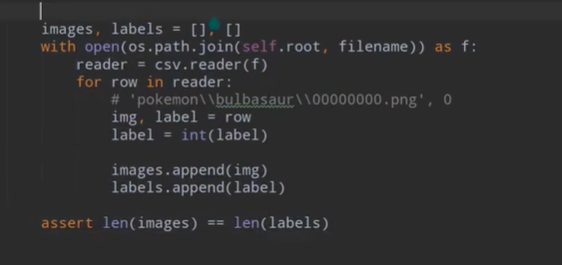
if:需要的指定的csv文件不存在,得需要先对数据路径进行保存,形成指定格式(path<数据路径> lable<为int类型>)的.csv文件然后进行加载。

[注]'os.sep'为\
最终结果生成指定类型文件的数据,数据格式为(数据,标签):
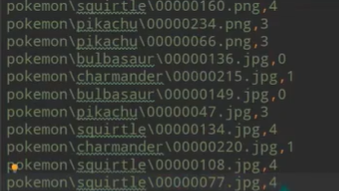

else :内容格式为:path(数据存储路径) lable(为int类型)的文件存在,则直接可以进行数据加载
(1.3)数据的划分:train 60%,val 20%,test 20%.

(1.4):数据处理,将数据进行变形(以达到数据增强的目的),增强数据并且转换成可以用pytorch处理的tensor类型。

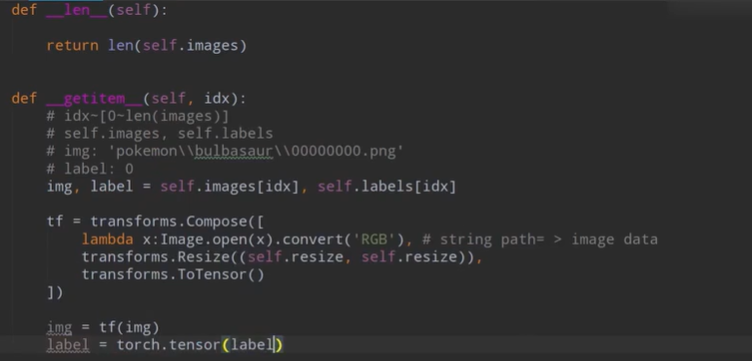
return img,label
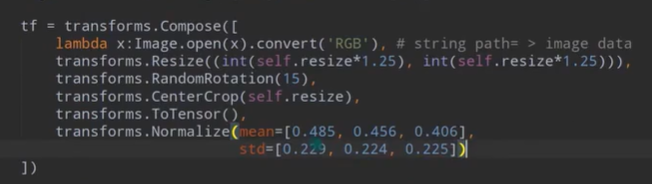
【注】数据的变形(增强)操作:Resize()放大缩小,RandomRotation()旋转,CenterCrop()中心裁剪,ToTenser(),Normalize()规范化将数据压缩到-1,1之间
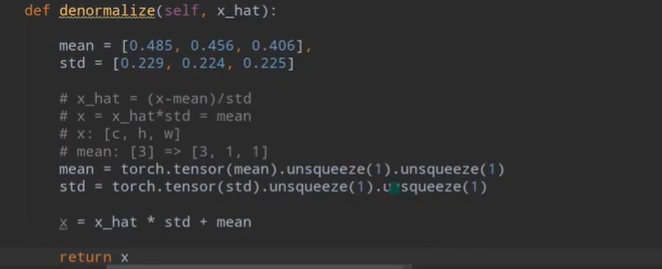
【注】Normalize()之后,可视化会出现问题,所以要进行denormalize()
【注】transforms.Compose{}转换器.lambda pa1:主体 左边为指定输入参数pa1,右边为lambda的主体。
【注】Python图像处理 PIL中convert(‘L’)函数原理,PIL有九种不同模式: 1,L,P,RGB,RGBA,CMYK,YCbCr,I,F。
img=img.convert()可以把图片转为指定格式的图片。https://blog.csdn.net/fanlily913/article/details/106571186详细参考该篇博客。
【注】mean=[0.485,0.456,0.406]三个值分别为R,G,B三个通道上的均值。std=[0.229,0.224,0.225]分别为R,G,B三个通道上的方差。
(1.5)通过可视化进行验证
未进行normalize()的可视化验证

进行了normalize()的可视化验证

[注]需要开启visdom进程:python -m visdom.server
(1.6)批量(batch)加载数据

【注】需要导入:from torch.utils.data import Dataset,DataLoader
2:使用如下代码也能完成数据集的加载工作
(2.1)一行代码完成数据加载

【注】这只能完成按照比较常规的目录存储的数据
【注】当用cpu时,可以通过DataLoader(db,batch_size=,num_workers=)开启多线程。
(2.2)如何查看成员变量:自动编码的表格
