在运行 MapReduce 程序时,输入的文件格式包括:基于行的日志文件、二进制格式文件、数据库表等。那么,针对不同的数据类型,MapReduce 是如何读取这些数据?
FileInputFormat 用来读取数据,其本身为一个抽象类,继承自 InputFormat 抽象类,针对不同的类型的数据有不同的子类来处理。 FileInputFormat 常见的接口实现类包括:TextInputFormat、KeyValueTextInputFormat、NLinelnputFormat、CombineTextInputFormat 和自定义 ImputFormat 等。
1.TextInputFormat 与 CombineTextInputFormat 类似,都是按行读取,键为偏移量,值为当前行的类容,只是切片机制不同。
2.KeyValueTextInputFormat 也是按行读取,当前行内容被分隔符分为 key 和 value。默认分隔符为 tab( ),可设置。
测试数据

按照空格分割,控制台日志(会取第一个匹配字符进行分割)

测试代码,统计重复 key 的次数


import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.KeyValueLineRecordReader; import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.log4j.BasicConfigurator; import java.io.IOException; public class KVDriver { static { try { // 设置 HADOOP_HOME 环境变量 System.setProperty("hadoop.home.dir", "D://DevelopTools/hadoop-2.9.2/"); // 日志初始化 BasicConfigurator.configure(); // 加载库文件 System.load("D://DevelopTools/hadoop-2.9.2/bin/hadoop.dll"); } catch (UnsatisfiedLinkError e) { System.err.println("Native code library failed to load. " + e); System.exit(1); } } public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { args = new String[]{"D:\tmp\input2", "D:\tmp\456"}; Configuration conf = new Configuration(); // 设置分隔符 conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR, " "); Job job = Job.getInstance(conf); job.setJarByClass(KVDriver.class); job.setMapperClass(KVMapper.class); job.setReducerClass(KVReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 设置 FileInputFormat job.setInputFormatClass(KeyValueTextInputFormat.class); FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } } class KVMapper extends Mapper<Text, Text, Text, IntWritable> { IntWritable v = new IntWritable(1); @Override protected void map(Text key, Text value, Context context) throws IOException, InterruptedException { // 查看 k-v System.out.println(key + "===" + value); context.write(key, v); } } class KVReducer extends Reducer<Text, IntWritable, Text, IntWritable> { IntWritable v = new IntWritable(); @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable value : values) { sum += value.get(); } v.set(sum); context.write(key, v); } }
3.NLinelnputFormat 与 TextInputFormat 和 CombineTextInputFormat 类似,但切片机制不同。
每个 map 进程处理的 InputSplit 不再按 Blok 块去划分,而是按 NlinelnputFormat 指定的行数 N 来划分。即(输入文件的总行数/N=切片数),如果不整除,切片数=商+1。
同样的测试数据,设置一行为一个切片
k-v 值
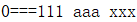
切片数

测试代码,统计单词数量
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.NLineInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.log4j.BasicConfigurator; import java.io.IOException; public class NLineDriver { static { try { // 设置 HADOOP_HOME 环境变量 System.setProperty("hadoop.home.dir", "D://DevelopTools/hadoop-2.9.2/"); // 日志初始化 BasicConfigurator.configure(); // 加载库文件 System.load("D://DevelopTools/hadoop-2.9.2/bin/hadoop.dll"); } catch (UnsatisfiedLinkError e) { System.err.println("Native code library failed to load. " + e); System.exit(1); } } public static void main(String[] args) throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException { args = new String[]{"D:\tmp\input2", "D:\tmp\456"}; Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); job.setJarByClass(NLineDriver.class); job.setMapperClass(NLineMapper.class); job.setReducerClass(NLineReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 使用 NLineInputFormat 处理记录数 job.setInputFormatClass(NLineInputFormat.class); // 设置每个切片 InputSplit 中划分一条记录 NLineInputFormat.setNumLinesPerSplit(job, 1); FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true); } } class NLineMapper extends Mapper<LongWritable, Text, Text, IntWritable> { Text k = new Text(); IntWritable v = new IntWritable(1); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 查看 k-v System.out.println(key + "===" + value); // 获取一行 String line = value.toString(); // 切割 String[] words = line.split(" "); // 循环写出 for (String word : words) { k.set(word); context.write(k, v); } } } class NLineReducer extends Reducer<Text, IntWritable, Text, IntWritable> { IntWritable v = new IntWritable(); @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable value : values) { sum += value.get(); } v.set(sum); context.write(key, v); } }