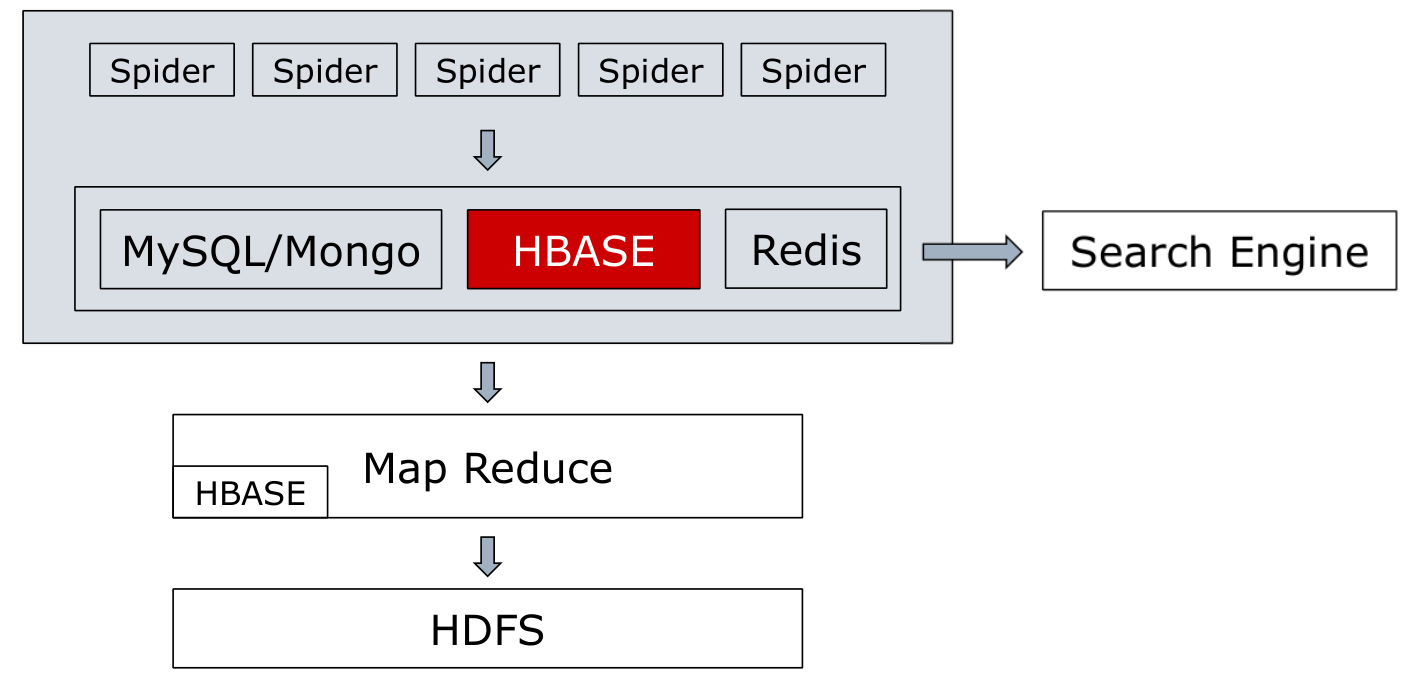
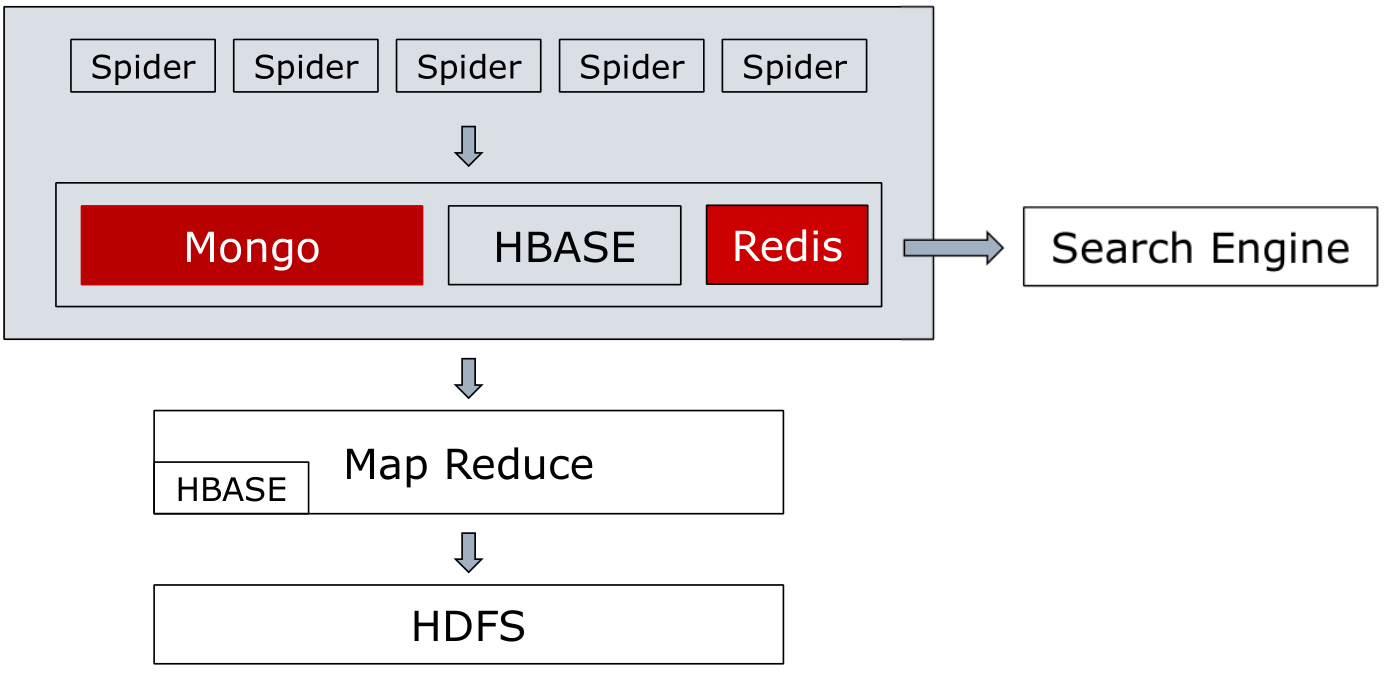
分布式爬虫系统
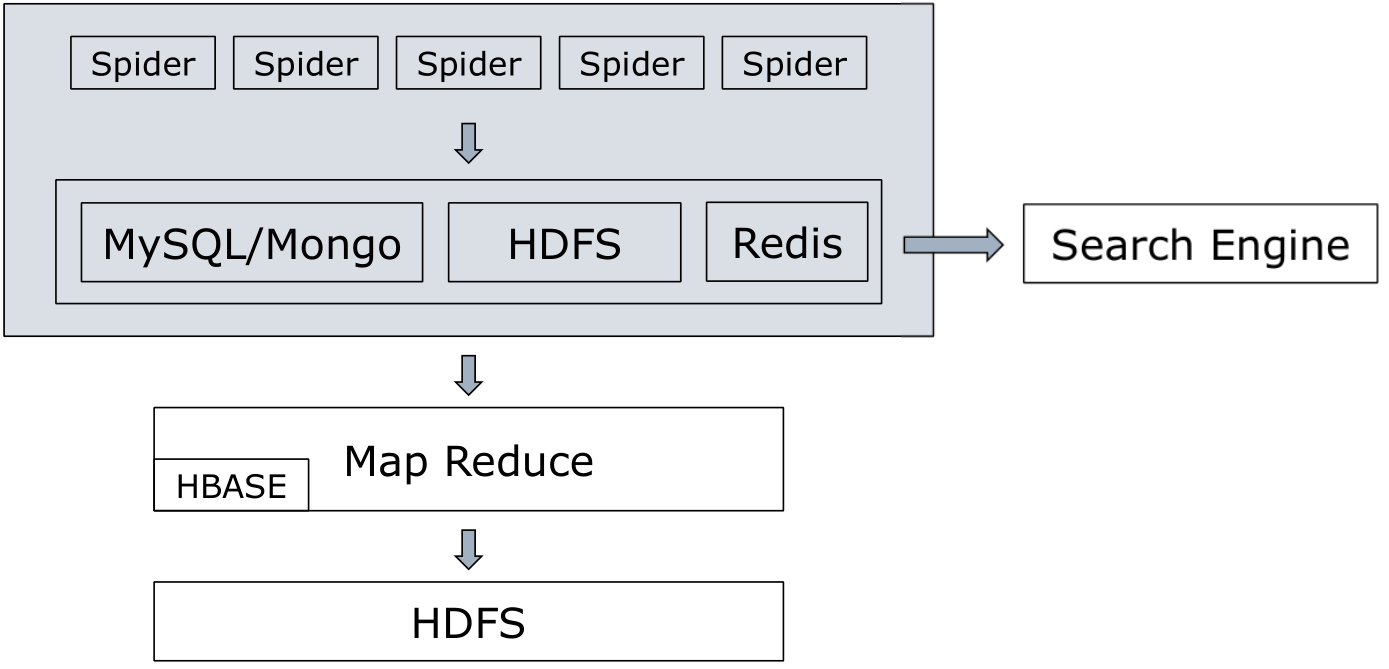
简单的分布式爬虫
分布式爬虫的作用:1.解决目标地址对IP访问频率的限制
2.利用更高的宽带,提高下载速度
3.大规模系统的分布式存储和备份
4.数据的扩展能力
将多进程爬虫部署到多台主机上
将数据库地址配置到统一的服务器上
将数据库设置仅允许特定IP来源的访问请求
设置防护墙,允许端口远程连接
分布式爬虫系统-爬虫
分布式存储
爬虫原数据存储特点
1.文件小,大量KB级别的文件
2.文件数量大
3.增量方式一次性写入,极少需要修改
4.顺序读取
5.并发的文件读写
6.可扩展
Googls FS
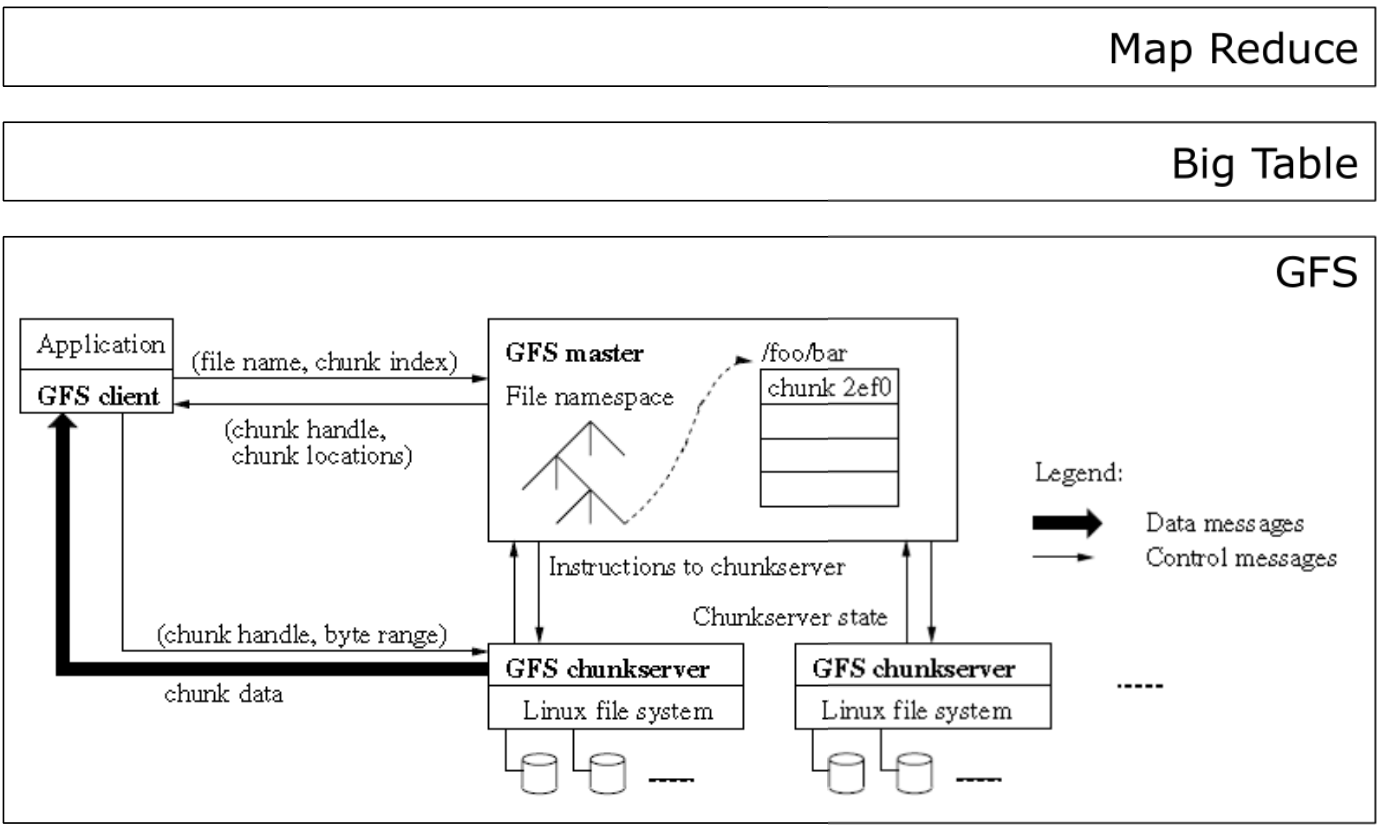
HDFS
Distributed,Scalable,Portable,File System
Written in Java
Not fully POSIX-compliant
Replication : 3 copies by default
Designed for immutable files
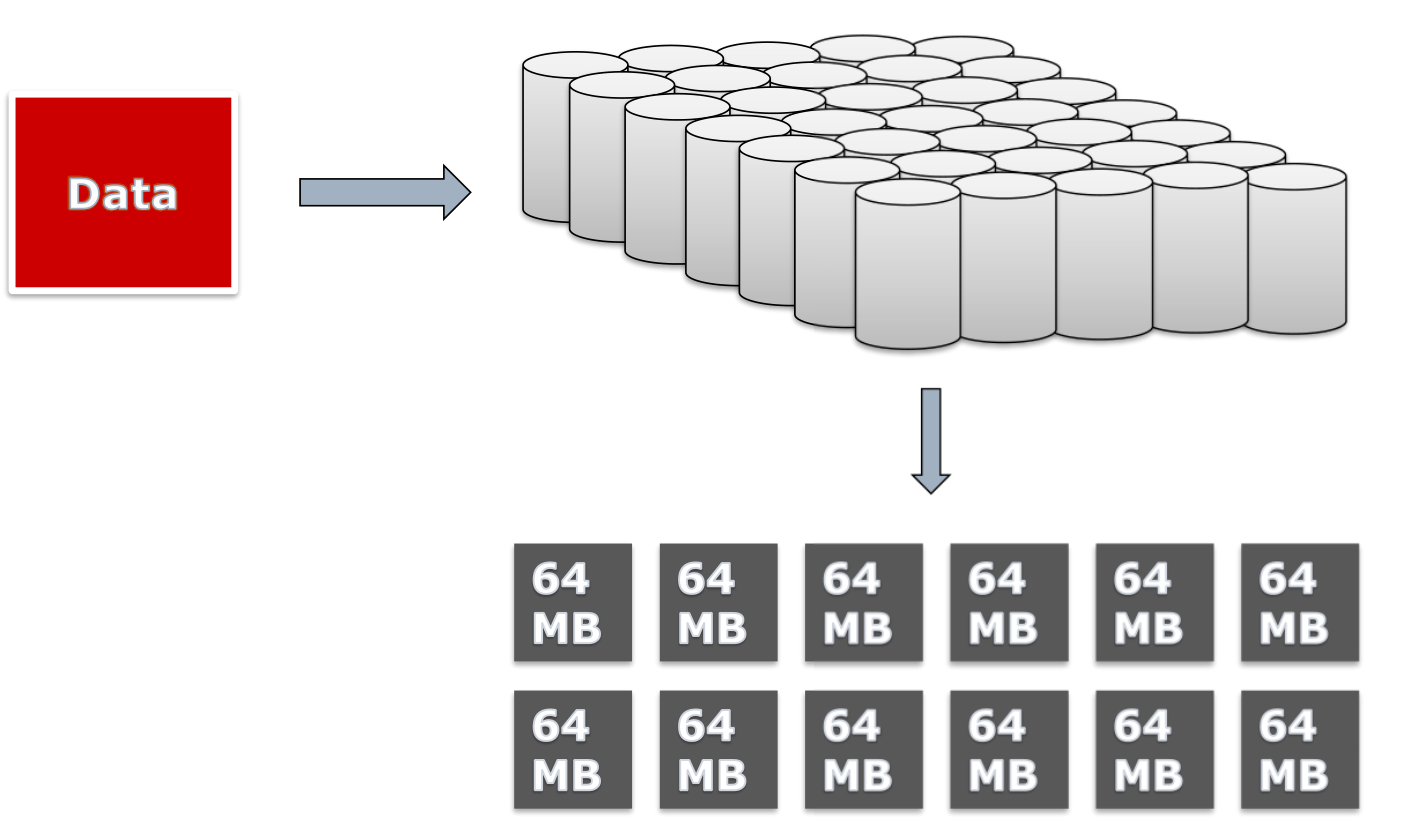
Files are cached and chunked ,chunk size 64MB

Python hdfs module
Installation : pip install hdfs
Methods : Desc
read() read a file
write() write a file
delete() Remove a file or directory from HDFS
rename() Move a file or folder
download() Download a file or folder from HDFS and save it locally
list() Return names of files contained in a remote folder
makedirs() Create a remote directory , recursively if necessary
resolve() Return absolute , normalized path , with special markers expanded
upload() Upload a file or directory to HDFS
walk() Depth-first walk of remote filesystem
存储到HDFS
from hdfs import *
from hdfs.util import HdfsError
hdfs_client=InsecureClient ('[ host ] : [ port ]',user='user')
with hdfs_client.write('/htmls/mfw/%s.html'%(filename)) as writer :
writer.write(html_page)
except HdfsError,Arguments :
print Arguments
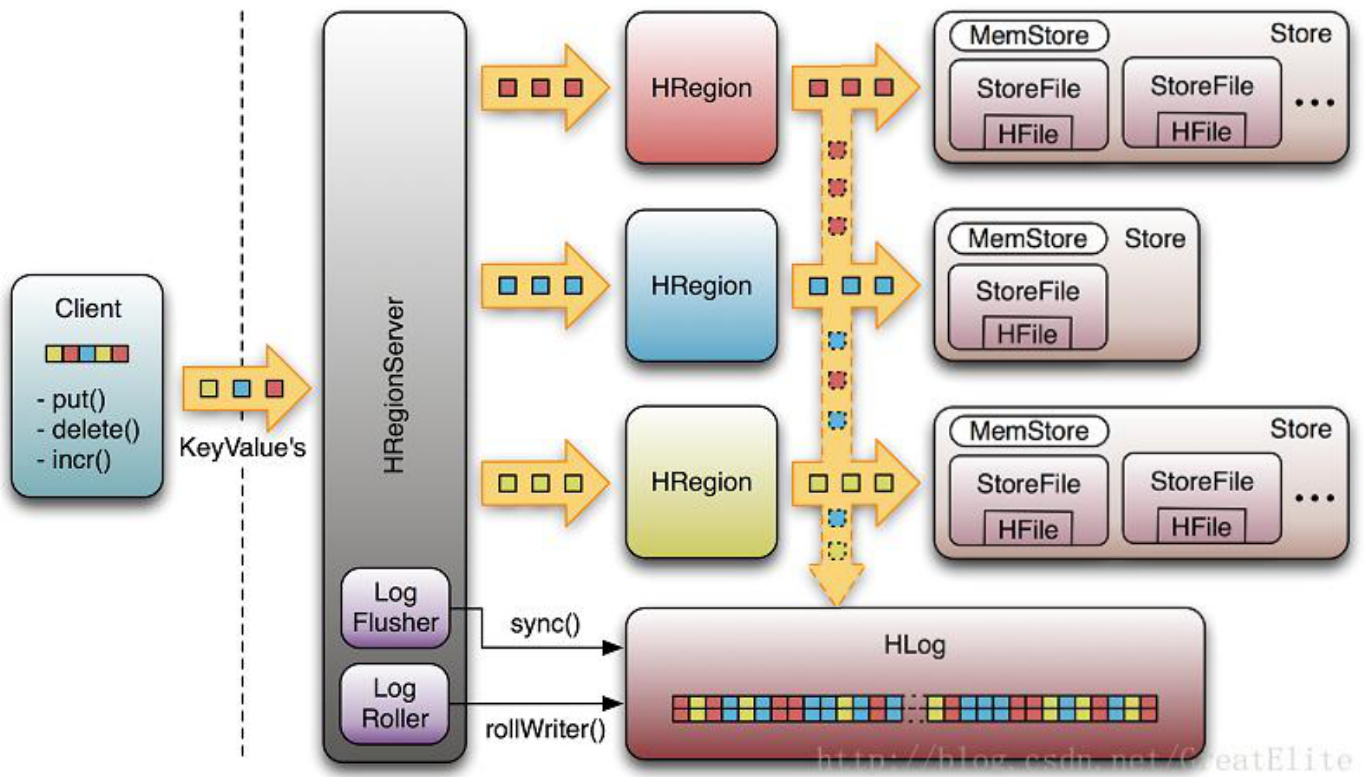
HBASE
on top of HDFS
Column-oriented database
Can store huge size raw data
KEY-VALUE
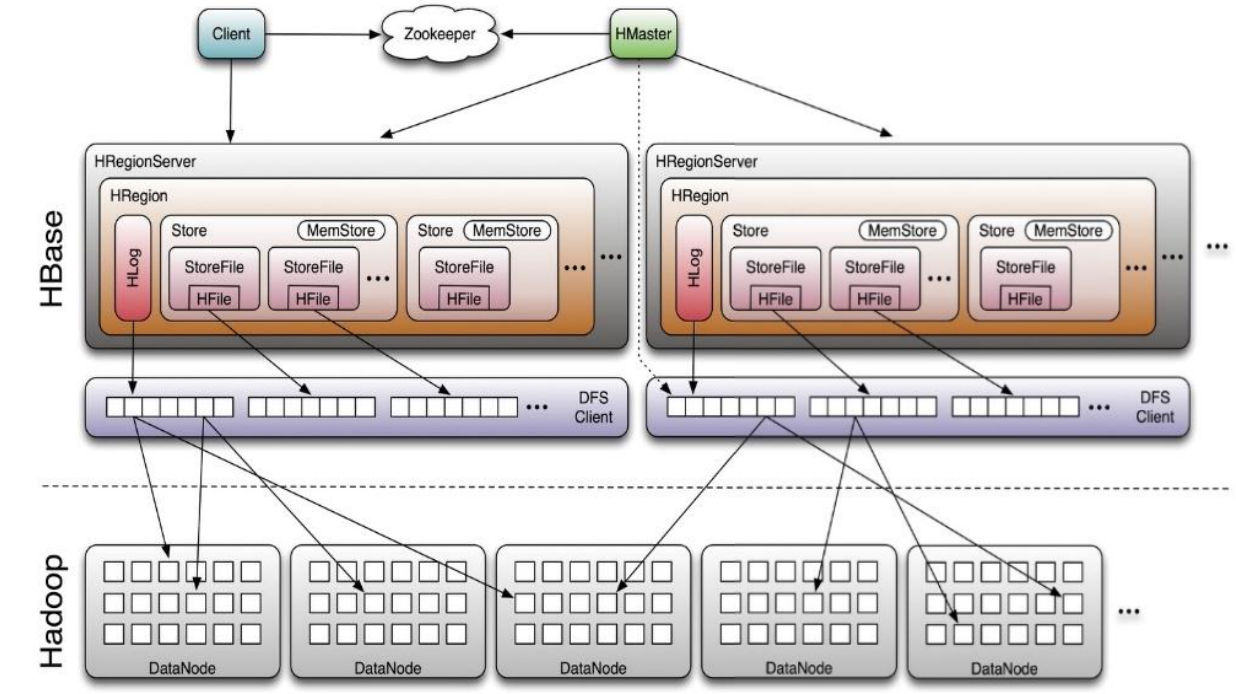
HDFS 和 HBASE

HBASE
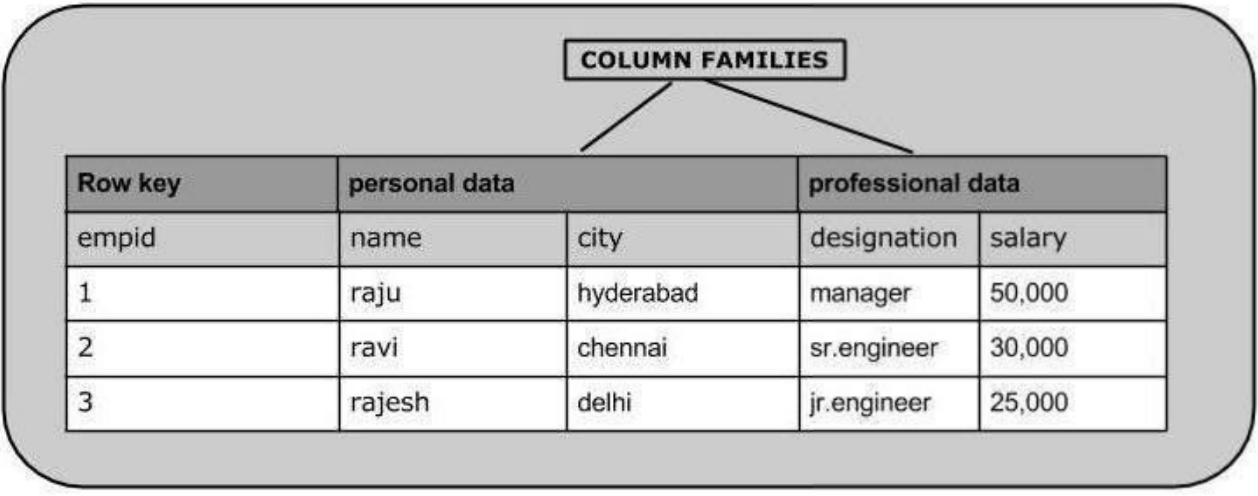
HBase is a column-oriented database and the tables in it are sorted by row. The table schema defines only column families,which are the key value pairs.
A table have multiple column families and each column family can have any number of column. Subsequent column values are stored contiguously on the
disk . Each cell value of the table has a timestamp. In short, in an HBase :
1.Table is a collection of rows
2.Row is a collection of column families
3.Column family is a collection of columns
4.Column is a collection of key value pairs
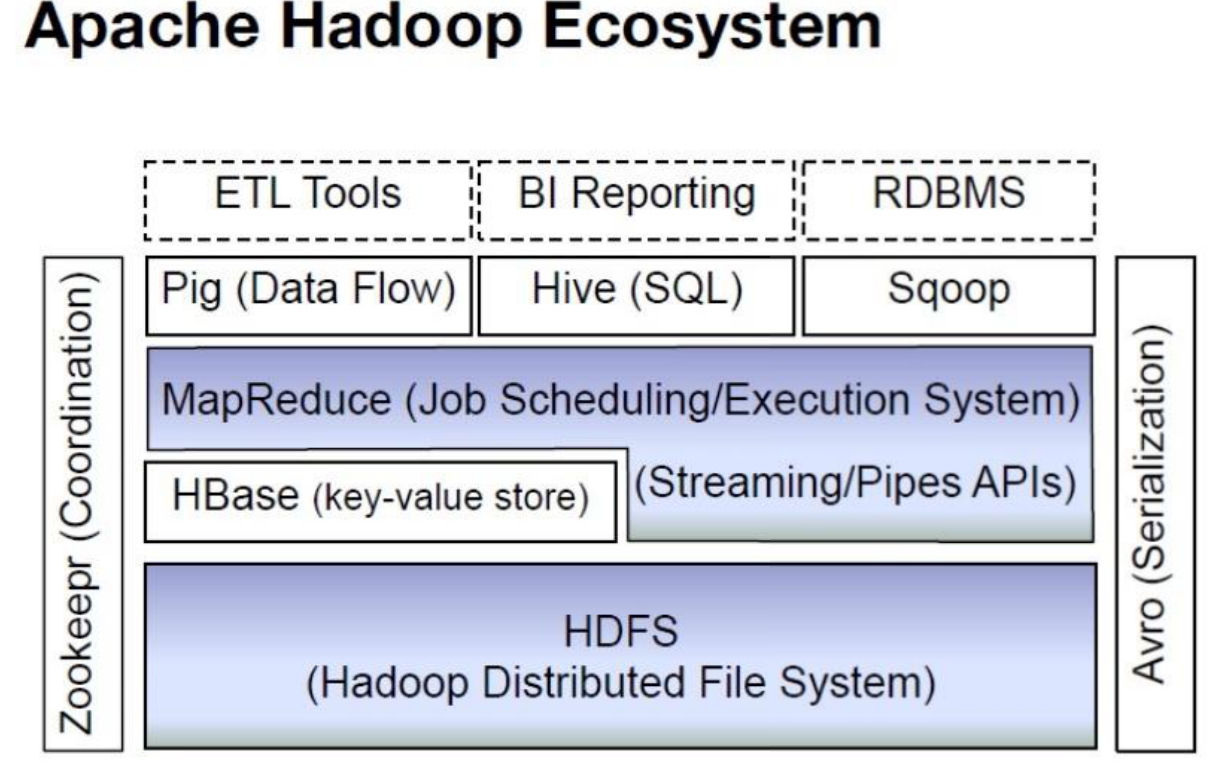
分布式爬虫系统—存储
分布式爬虫—数据库
MongoDB
MongoDB
Schema less - MongoDB is a document database in which one collection holds different documents. Number of fields,content and size of the document can differ from one
document to another.
Structure of a single object is clear.
No complex joins .
Deep query-ability. MongoDB supports dynamic queries on documents using a document-based query language that's nearly as powerful as SQL.
Ease of scale-out-MongoDB is easy to scale .
Conversion/ mapping of application objects to database objects not needed
Installation
download
https://www.mongodb.com/download-center?jmp=nav#community
https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-amazon-3.4.2.tgz
setup
mkdir mongodb
tar xzvf mongodb-liunx-x86_64-amazon-3.4.2.tgz-C mongodb
client
mongo
Mongo DB
db.collection.findOneAndUpdate(filter,update,options)
Returns one document that satisfies the specified query criteria.
Returns the first document according to natural order, means insert order
Find and update are done atomically
MongoClient methods :
db.spider.mfw.find_one_and_uodate()
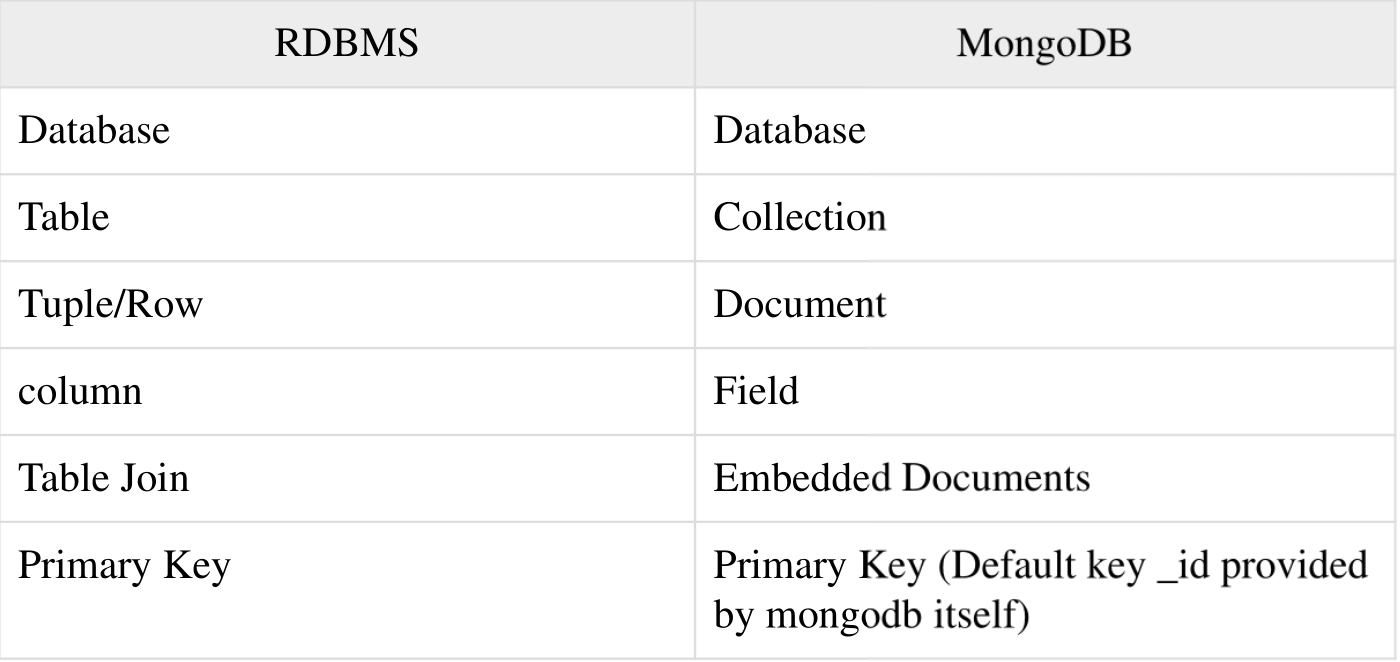
数据库类型
Redis Overview
基于KEY VALUE 模式的内存数据库
支持复杂的对象模型(MemoryCached 仅支持少量类型)
支持Replication,实现集群(MemoryCached 不支持分布式部署)
所有操作都是原子性(MemoryCached 多数操作都不是原子的)
可以序列化到磁盘(MemoryCached 不能序列化)
Redis Environment Setup
downlod
$ wget http://download.redis.io/releases/redis-3.2.7.tar.gz
$ tar xzf redis-3.2.7.tar.gz
$ cd redis-3.2.7
$ make
Start server and cli
$ nohup src/ redis-server&
$ src/redis-cli
Test it
redis >set foo bar
OK
redis >get foo
"bar"
python Redis
Installation
$ sudo pip install redis
Sample Code
>>>import redis
>>>r=redis.StricRedis(host='localhost',port=6379,db=0)
>>>
>>>r.set(‘foo’,‘bar’)
True
>>>r.get(‘foo’)
‘bar’
Mongo的优化
url作为_id,默认会被创建索引,创建索引是需要额外开销的
index尽量简单,url长一些
dequeueUrl find_one()并没有利用index,会全库扫描,但是仍然会很快,因为扫描到第一个后就停止了,但是当下载完后的数量特别大的时候,扫描依然是很费时的,考虑一下能不能进一步优化
插入的操作很频繁,每一个网页对应着几百次插入,到了depth=3的时候,基数网页是百万级,插入检查将会是亿级,考虑使用更高效的方式来检查
Mongo with Redis
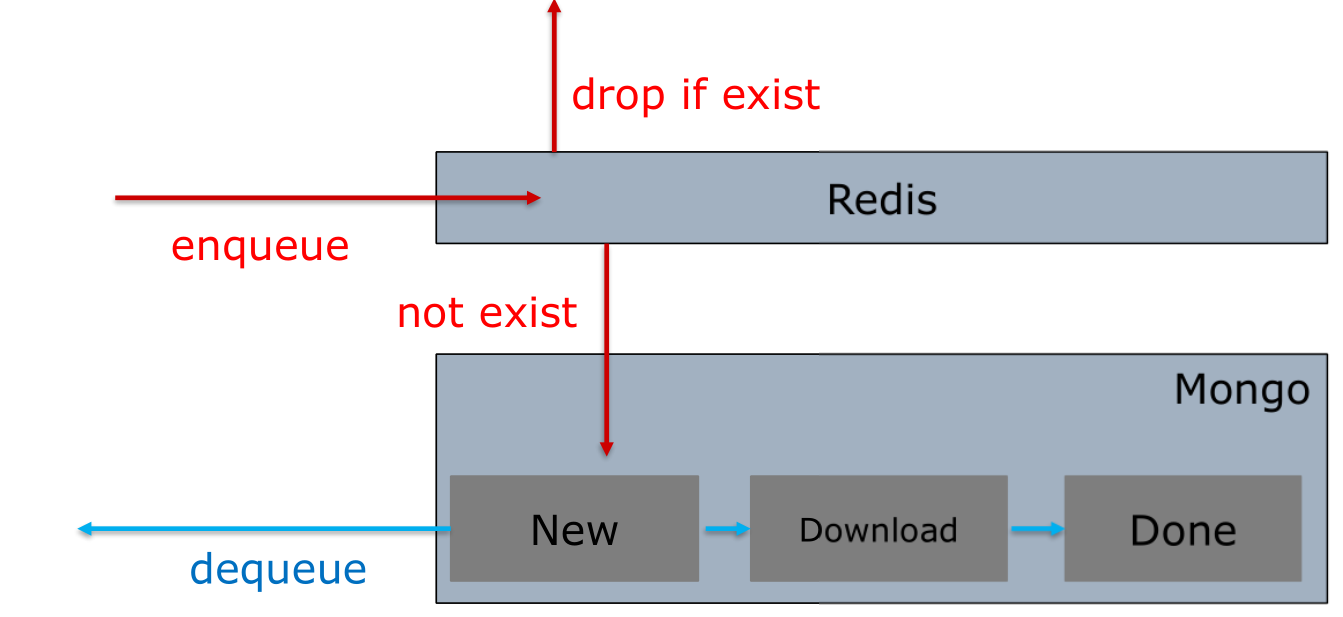
status:create index OR in different collections
Code Snippet