原子性
要么一起成功要么都不成功
隔离性
多次状态的转换不能互相影响,执行顺序要有一定的规律
一致性
最终的结果符合现实中的约束,就是符合一致性
持久性
状态的改变会永久性保存
redo日志
我们知道 数据库与磁盘交互是以页为单位的,页被缓存在buffer pool中,修改了数据之后为了不使数据丢失,就需要把buffer pool中对应的页同步到磁盘中,这一步是很耗时的,为了解决效率问题,mysql设计了一个redo日志 只将事务执行的redo日志同步到磁盘中
redo的优点
1. 体积小
2. 顺序存储

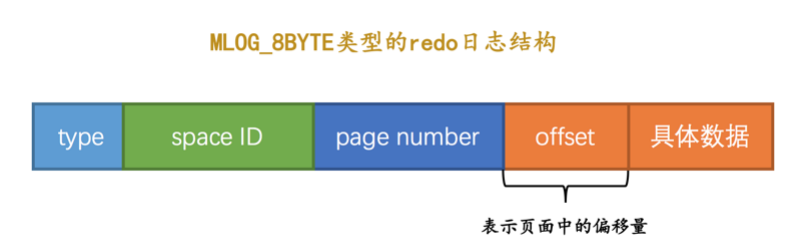
type: 日志类型
spaceId: 表空间id
page number: 页号
data: 该条日志的具体信息
以隐藏列row_id为例,数据库会在内存中维护一个row值,当用到隐藏列的表中插入一条记录时row_id+1,这一步是在buffer pool中完成的,并生成一条redo日志,当row_id是256的倍数时,会同步数据到磁盘中的系统表空间
根据页面写入数据的大小划分了几种不同类型的redo
- MLOG_1BYTE 写入1byte的redo日志
- MLOG_2BYTE 写入2byte的redo日志
- MLOG_4BYTE 写入4byte的redo日志
- MLOG_8BYTE 写入8byte的redo日志
-MLOG_WRITE_STRING 写入了一串数据

针对MLOG_COMP_REC_INSERT为例,由于数据是存储在聚簇索引的,并且数据都有额外数据,redo是不记录全部的额外数据的,只是记录一些插入函数需要的参数,在恢复数据的时候调用,这种方式称为逻辑日志
mini-transaction
redo日志分组,因为在一条数据库操作中会生成多条redo日志,由于要保证这些redo日志是事务性的,mysql把这一类redo日志放到一个组里,
如何实现分组呢?在一组redo日志的最后一条记录加上一条特殊类型的redo日志 该类型为MLOG_MULTI_REC_END
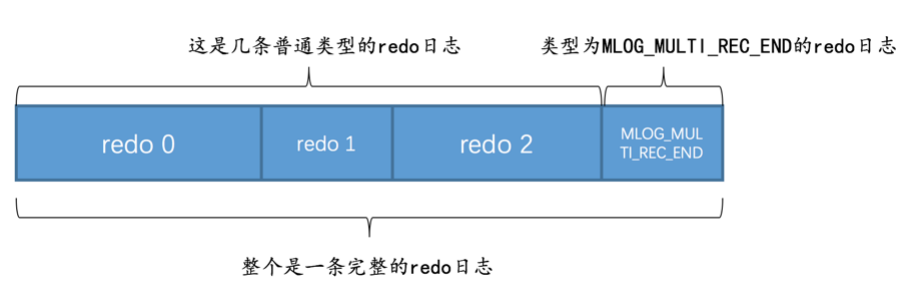
这代表一组redo日志
如何确认这条记录是单条日志 还是一组日志,type属性的第一个byte为1 代表只产生了一条redo日志 为0表示产生了多条redo日志 这组redo是不可分割的整体,在崩溃恢复的时候要么一起成功要么失败
redo写入过程
minitransaction生成的redo日志存储到了一个512字节的页中
系统启动时会申请一串连续的空间存放redo log block 称为redo日志缓冲区 log buffer
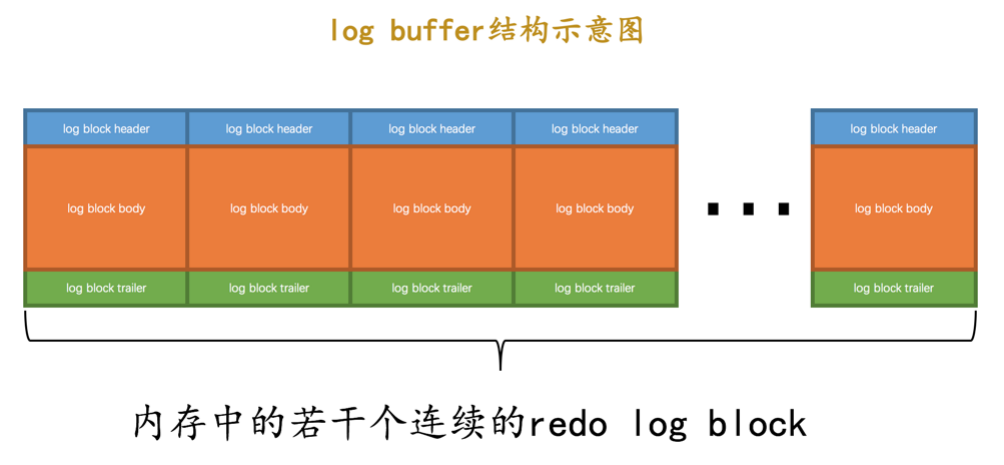
redo log block中是顺序存储redo log的,当一个block写满再写下一组,那么写入的时候如何知道这次从哪个位置写呢?
用一个全局变量buf_free 指向日志写入的位置,redo log是以组的形式存入log buffer中的.
redo 刷盘时机
那么日志是何时刷盘的呢?
1. log buffer的容量被占用一半以上就刷新
2. 事务提交时刷新
3. 后台任务大约每秒都刷新
4. 正常关闭服务器时
5. 做所谓的checkpoint时
log sequeue number(lsn日志序列号) 日志的写入量+log block header + log block trailer
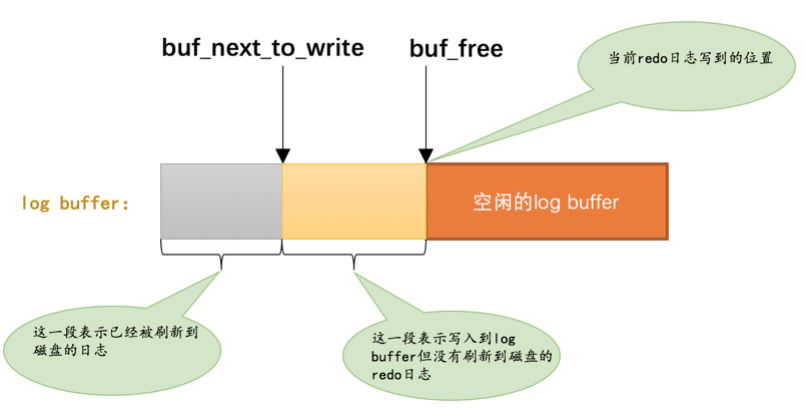
buf_next_to_write 标记当前log buffer已经有哪些日志刷新到磁盘了
flushed_to_disk_lsn刷新到磁盘的redo日志量的变量
lsn是一个全局变量,初始值是8704
每一组redo log都对应着一个lsn,lsn越小说明日志产生的越早.
redo日志是先写到log buffer中再写入到磁盘中的,mysql用了buf_next_to_write变量去保存刷新log buffer到哪个位置了,用flushed_to_disk_lsn表示buffer中的redo刷新到磁盘中的数据长度
当redo 存入到log buffer 中的时候lsn增加,flushed_to_disk_lsn不变,初始时flushed_to_disk_lsn跟lsn是一样的,当刷新的时候flushed_to_disk_lsn才增加,当lsn跟flushed_to_disk_lsn数值一致的时候,说明buffer中的日志全部刷新到磁盘中了
checkpoint_lsn可以覆盖的redo日志总量初始值为8704
redo日志可以被覆盖的前提条件是 对应的页被刷新到了磁盘中,那么redo的lsn值小于flush链表中最后节点的oldest_modification就可以被覆盖
将checkpoint_lsn值,redo日志文件组偏移量checkpoint_offset以及checkpoint_no写到日志文件的管理信息中
如果系统修改页面太频繁后台线程处理不过来,就需要用户线程同步刷新flush链表末尾页到磁盘
崩溃恢复
系统崩溃了需要恢复,第一步
确认恢复的起点
checkpoint_no最大值的checkpoint_lsn值就是起点
确认恢复的终点
每个redo log block LOG_BLOCK_HDR_DATA_LEN属性不是512的
如何恢复
根据redo日志的表空间id+页号生成hash值,存入hash表中,相同key的用链表按redo生成顺序连接,然后遍历hash表这样可以一次性将一个页的数据恢复好
,如何避免重复?页面中存着每次修改对应页面的lsn值,如果恢复的时候redo的lsn值小于页面的lsn就不恢复