Apache Spark Examples
These examples give a quick overview of the Spark API. Spark is built on the concept of distributed datasets, which contain arbitrary Java or Python objects. You create a dataset from external data, then apply parallel operations to it. The building block of the Spark API is its RDD API. In the RDD API, there are two types of operations: transformations, which define a new dataset based on previous ones, and actions, which kick off a job to execute on a cluster. On top of Spark’s RDD API, high level APIs are provided, e.g. DataFrame API and Machine Learning API. These high level APIs provide a concise way to conduct certain data operations. In this page, we will show examples using RDD API as well as examples using high level APIs.
-
-
实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core中还包含了对弹性分布式数据集(Resilient Distributed DataSet,简称RDD)的API定义
-
-
Spark SQL
-
是Spark用来操作结构化数据的程序包。通过Spark SQL,我们可以使用 SQL或者Hive SQL来查询数据。Spark SQL支持多种数据源,比如Hive表、Parquet以及JSON等
-
-
Spark Streaming
-
是Spark提供的对实时数据进行流式计算的组件。提供了用来操作数据流的API,并且与Spark Core中的 RDD API高度对应
-
-
Spark MLlib
-
提供常见的机器学习(ML)功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据 导入等额外的支持功能
-
-
集群管理器
-
Spark 设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。为了实现这样的要求,同时获得最大灵活性,Spark支持在各种集群管理器(Cluster Manager)上运行,包括Hadoop YARN、Apache Mesos,以及Spark自带的一个简易调度器,叫作独立调度器(Standalone)

-
spark核心模块
Spark Core:


1 package rdd 2 3 import org.apache.spark.{SparkConf, SparkContext} 4 import org.apache.spark.rdd.RDD 5 object RDDCommonUsage { 6 def main(args: Array[String]): Unit = { 7 //这是spark安装目录中自带的测试数据。 8 val filepath="file:///D:/spark-2.4.5-bin-hadoop2.7/examples/src/main/resources/people.csv" 9 val conf =new SparkConf().setMaster("local[2]").setAppName("common usage") 10 val sc=new SparkContext(conf) 11 val rdd=sc.textFile(filepath) 12 val rdd1=sc.parallelize(Array(1,2,3,4,5)) 13 14 //转换操作 15 rdd.map(line=>(line,1)) 16 rdd.filter(line=>line.contains("xiaohua")) 17 rdd.flatMap(line=>line.split(",")) 18 var x=rdd1.map(x=>(x,1)) 19 x.reduceByKey((a,b)=>a+b)//有K,V=>K,V1;操作是针对value而言的,groupByKey也是针对value的 20 rdd.flatMap(_.split(",")).map(word=>(word,1)).groupByKey().foreach(println)//K,V=>K,Iterable 21 x.groupByKey() 22 x.countByKey() 23 //groupByKey只能生产一个序列,本身不能自定义函数,需要先用groupByKey生成RDD,然后再map。 24 //而reduceByKey能够在本地先进行merge操作,并且merge操作可以通过函数自定义。 25 x.sortByKey() 26 x.keys 27 x.values 28 x.join(x).foreach(println)//join键值对的内连接操作,key相等时,才连接。(K,V1)和(K,V2)---(K,(V1,V2)) 29 30 31 //行动操作 32 rdd1.count() 33 rdd1.collect() 34 rdd1.first() 35 rdd1.take(2) 36 rdd1.reduce((a,b)=>a+b) 37 rdd1.foreach(println) 38 rdd1.top(2)//top k 元素 39 40 //实例 41 42 //1.wordcount 43 val wordCount1=wordCount(rdd) 44 wordCount1.cache()//中间结果暂存到内存中。 45 wordCount1.collect().foreach(println) 46 47 //2.图书的平均销量,数据格式为(key,value),key表示图书名称,value表示某天图书销量. 48 49 50 } 51 def wordCount(rdd:RDD[String]) :RDD[(String,Int)]={ 52 val wordCount :RDD[(String,Int)]= rdd.flatMap(line=>line.split(",")) 53 .map(word=>(word,1)).reduceByKey((a,b)=>a+b) 54 55 wordCount 56 } 57 58 59 }
- Scala版:
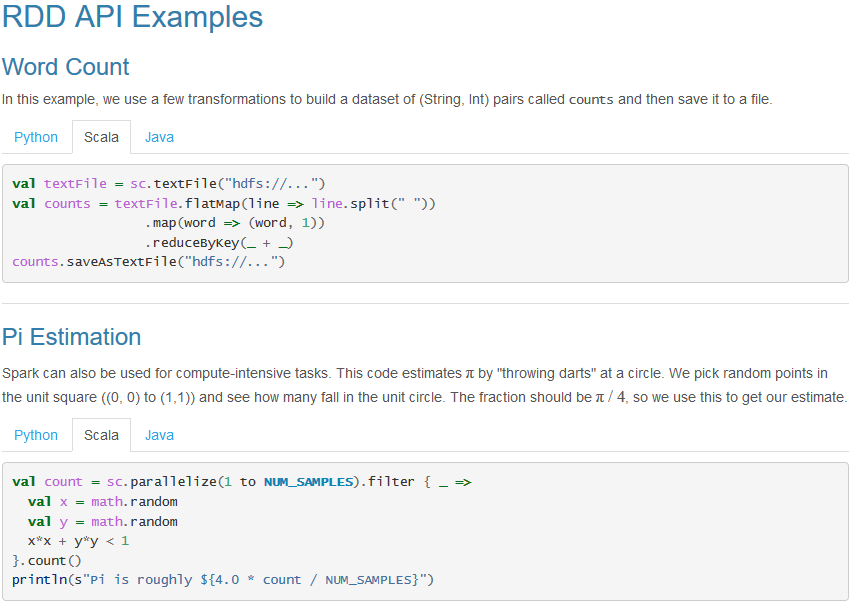
- Python版:
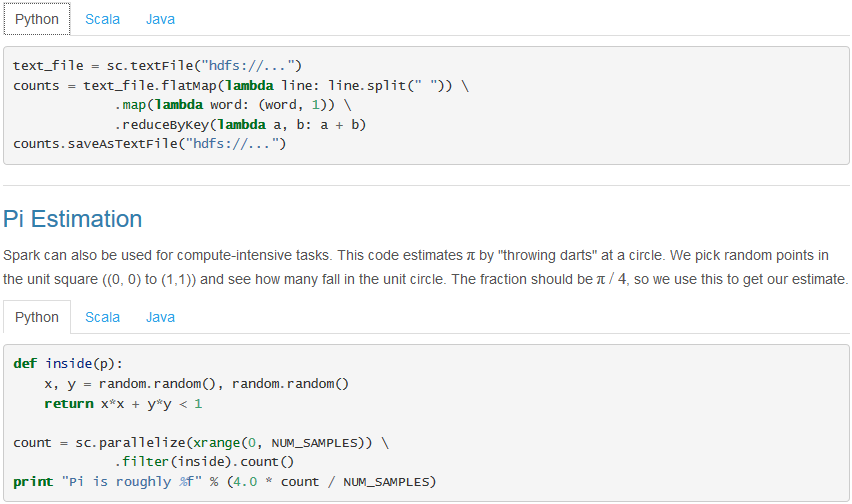
Spark SQL
1 package dataframe.mysql2df 2 3 import java.util.Properties 4 import org.apache.spark.sql.{Row, SparkSession} 5 import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType} 6 7 object Mysql2DataFrame { 8 def main(args: Array[String]): Unit = { 9 val spark = SparkSession.builder 10 .master("local[*]") 11 .appName("MySql2DataFrame") 12 .config("spark.sql.warehouse.dir", "file:///F:/code_environment/BigData/spark-warehouse") 13 .getOrCreate() 14 val url="jdbc:mysql://localhost:3306/spark?serverTimezone=UTC" 15 val jdbcDF = spark.read.format("jdbc") 16 //spark is dbname;?serverTimezone is necessary for MySql8 17 .option("url",url ) 18 .option("driver", "com.mysql.cj.jdbc.Driver") 19 .option("user", "root") 20 .option("password", "1995") 21 .option("dbtable", "student") 22 .load() 23 //insert new data into MySQL ,table fields :(| id|name|gender|age|) 24 25 //header 26 val schema = StructType(List(StructField("id", IntegerType, nullable = true), 27 StructField("name", StringType, nullable = true), 28 StructField("gender", StringType, nullable = true), 29 StructField("age", IntegerType, nullable = true))) 30 //contents 31 val studRDD = spark.sparkContext.parallelize(Array("3 Rongcheng M 26", "4 Guanhua M 27")).map(_.split(" ")) 32 val rowRDD = studRDD.map(p => Row(p(0).toInt, p(1).trim, p(2).trim, p(3).toInt)) 33 val studDF = spark.createDataFrame(rowRDD, schema) 34 //prepare for write 35 val prop = new Properties() 36 prop.put("driver","com.mysql.cj.jdbc.Driver") 37 prop.put("user", "root") 38 prop.put("password", "1995") 39 studDF.write.mode("append").jdbc(url, "spark.student", prop) 40 41 42 println(jdbcDF.show()) 43 } 44 45 }
Spark DataFrame
- DataFrame:它不是spark sql提出来的,而是早期在R、Pandas语言就已经有了的
- DataSet: A DataSet is a distributed collection of data. (分布式的数据集)
- DataFrame:A DataFrame is a DataSet organized into named columns. 以列(列名,列类型,列值)的形式构成的分布式的数据集,按照列赋予不同的名称
概念
1)分布式的数据集,并且以列的方式组合的。相当于具有schema的RDD
2)相当于关系型数据库中的表,但是底层有优化
3)提供了一些抽象的操作,如select、filter、aggregation、plot
4)它是由于R语言或者Pandas语言处理小数据集的经验应用到处理分布式大数据集上
5)在1.3版本之前,叫SchemaRDD
DataFrame对比RDD
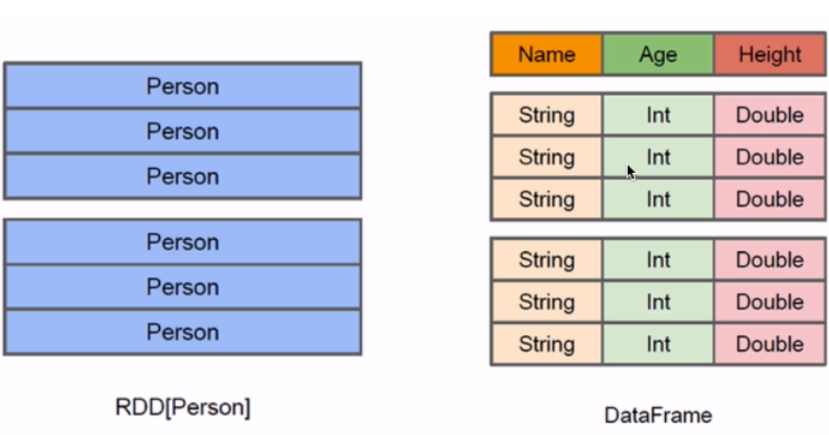
RDD介绍:
RDD,即弹性分布式数据集(Resilient Distributed Dataset,RDD)。RDD是Spark的最基本抽象,是对分布式内存的抽象使用,实现了以操作本地集合的方式来操作分布式数据集的抽象实现。RDD是Spark最核心的东西,它表示已被分区,不可变的并能够被并行操作的数据集合,不同的数据集格式对应不同的RDD实现,并且RDD必须是可序列化的。RDD可以cache到内存中,每次对RDD数据集的操作之后的结果,都可以存放到内存中,下一个操作可以直接从内存中输入,省去了MapReduce大量的磁盘IO操作。这对于迭代运算比较常见的机器学习算法, 交互式数据挖掘来说,效率提升比较大。
RDD的特点:
1)创建:只能通过转换 ( transformation ,如map/filter/groupBy/join 等) ,从两种数据源中创建 RDD 1 )稳定存储中的数据; 2 )其他 RDD
2)只读:状态不可变,不能修改。
3)分区:支持使RDD 中的元素根据指定 key 来分区 ( partitioning ) ,保存到多个结点上。还原时只会重新计算丢失分区的数据,而不会影响整个系统。
4)路径:在 RDD 中叫世族或血统 ( lineage ) ,即 RDD 有充足的信息关于它是如何从其它RDD 产生而来的。
5)持久化:支持将 会被重用的 RDD 进行持久化[ cache() 或 persist() ]。
6)延迟计算: Spark会延迟计算 RDD (lazy 模式) ,使其能够将转换管道化 (pipeline transformation)。
7)操作:丰富的转换(transformation)和动作 ( action ) , count/reduce/collect/save 等。
执行了多少次transformation操作,RDD都不会真正执行运算(记录lineage),只有当action操作被执行时,运算才会触发
Spark的延迟计算:
All transformations in Spark are lazy, in that they do not compute their results right away. Instead, they just remember the transformations applied to some base dataset (e.g. a file). The transformations are only computed when an action requires a result to be returned to the driver program. (RDD Operations)
在 Spark 中,所有的 transformation() 类型操作都是延迟计算的,Spark 只是记录了将要对数据集进行的操作。只有当执行action操作将数据返回到 Driver 程序时(即触发 Action 类型操作),所有已记录的 transformation() 才会执行。
Spark Job 执行逻辑
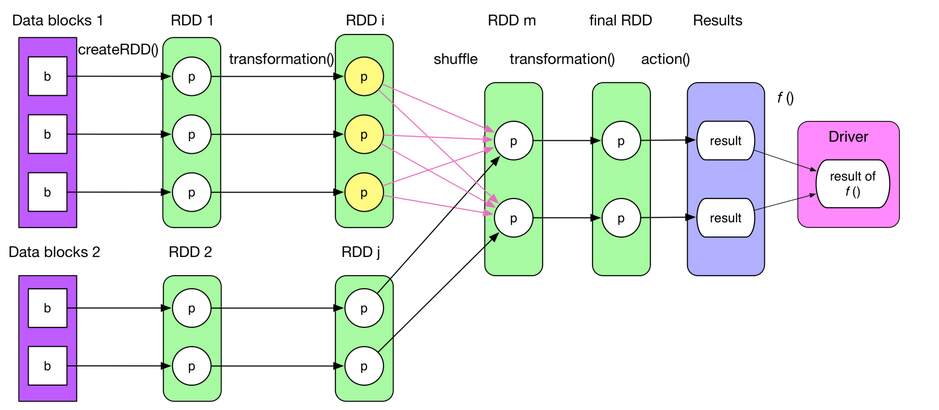
Spark 在每次 transformation() 的时候使用了新产生的 RDD 来记录计算逻辑,这样就把作用在 RDD 上的所有计算逻辑串起来形成了一个链条,逻辑执行图上表示的实际上就是是 Spark Job 的计算链。当然某些 transformation() 比较复杂,会包含多个子 transformation(),因而会生成多个 RDD。这就是实际 RDD 个数会比我们想象的多一些的原因。当对 RDD 进行 action() 时,Spark 会调用在计算链条末端最后一个 RDD 的compute()方法,这个方法会接收它上一个 RDD 或者数据源的 input records,并执行自身定义的计算逻辑,从而输出结果。一句话总结 Spark 执行 action() 的流程就是:从计算链的最后一个 RDD 开始,依次从上一个 RDD 获取数据并执行计算逻辑,最后输出结果。
compute 方法
在 RDD 中,compute()被定义为抽象方法,要求其所有子类都必须实现,该方法接受的参数之一是一个Partition对象,目的是计算该分区中的数据。以之前flatmap操作生成得到的MapPartitionsRDD类为例。
|
override def compute(split: Partition, context: TaskContext): Iterator[U] = f(context, split.index, firstParent[T].iterator(split, context)) |
|---|
其中,firstParent在 RDD 中定义。
|
/** Returns the first parent RDD */protected[spark] def firstParent[U: ClassTag] = { dependencies.head.rdd.asInstanceOf[RDD[U]]} |
|---|
MapPartitionsRDD类的compute方法调用当前 RDD 内的第一个父 RDD 的iterator方法,该方的目的是拉取父 RDD 对应分区内的数据,它返回一个迭代器对象,迭代器内部存储的每个元素即父 RDD 对应分区内已经计算完毕的数据记录。得到的迭代器作为f方法的一个参数。compute方法会将迭代器中的记录一一输入f方法,得到的新迭代器即为所求分区中的数据。
iterator方法
iterator方法的实现在 RDD 类中。
|
/** * Internal method to this RDD; will read from cache if applicable, or otherwise compute it. * This should ''not'' be called by users directly, but is available for implementors of custom * subclasses of RDD. */final def iterator(split: Partition, context: TaskContext): Iterator[T] = { if (storageLevel != StorageLevel.NONE) { SparkEnv.get.cacheManager.getOrCompute(this, split, context, storageLevel) } else { computeOrReadCheckpoint(split, context) }} |
|---|
iterator方法首先检查当前 RDD 的存储级别,如果存储级别不为None,说明分区的数据要么已经存储在文件系统当中,要么当前 RDD 曾经执行过cache、persise等持久化操作,
因此需要想办法把数据从存储介质中提取出来。iterator方法继续调用CacheManager的getOrCompute方法。
|
/** Gets or computes an RDD partition. Used by RDD.iterator() when an RDD is cached. */ def getOrCompute[T]( rdd: RDD[T], partition: Partition, context: TaskContext, storageLevel: StorageLevel): Iterator[T] = { val key = RDDBlockId(rdd.id, partition.index) blockManager.get(key) match { case Some(blockResult) => // Partition is already materialized, so just return its values context.taskMetrics.inputMetrics = Some(blockResult.inputMetrics) new InterruptibleIterator(context, blockResult.data.asInstanceOf[Iterator[T]]) case None => // 省略部分源码 val computedValues = rdd.computeOrReadCheckpoint(partition, context) val cachedValues = putInBlockManager(key, computedValues, storageLevel, updatedBlocks) new InterruptibleIterator(context, cachedValues) } // 省略部分源码} |
|---|
getOrCompute方法会根据 RDD 编号与分区编号计算得到当前分区在存储层对应的块编号,通过存储层提供的数据读取接口提取出块的数据。这时候会有两种可能情况发生:
- 数据之前已经存储在存储介质当中,可能是数据本身就在存储介质(如读取 HDFS 中的文件创建得到的 RDD)当中,也可能是 RDD 经过持久化操作并经历了一次计算过程。这时候就能成功提取得到数据并将其返回。
- 数据不在存储介质当中,可能是数据已经丢失,或者 RDD 经过持久化操作,但是是当前分区数据是第一次被计算,因此会出现拉取得到数据为 None 的情况。这就意味着我们需要计算分区数据,继续调用 RDD 类 computeOrReadCheckpoint 方法来计算数据,并将计算得到的数据缓存到存储介质中,下次就无需再重复计算。
- 如果当前RDD的存储级别为 None,说明为未经持久化的 RDD,需要重新计算 RDD 内的数据,这时候调用 RDD 类的 computeOrReadCheckpoint 方法,该方法也在持久化 RDD 的分区获取数据失败时被调用。
|
/** * Compute an RDD partition or read it from a checkpoint if the RDD is checkpointing. */private[spark] def computeOrReadCheckpoint(split: Partition, context: TaskContext): Iterator[T] = { if (isCheckpointed) firstParent[T].iterator(split, context) else compute(split, context)} |
|---|
computeOrReadCheckpoint方法会检查当前 RDD 是否已经被标记成检查点,如果未被标记成检查点,则执行自身的compute方法来计算分区数据,否则就直接拉取父 RDD 分区内的数据。
RDD的容错机制
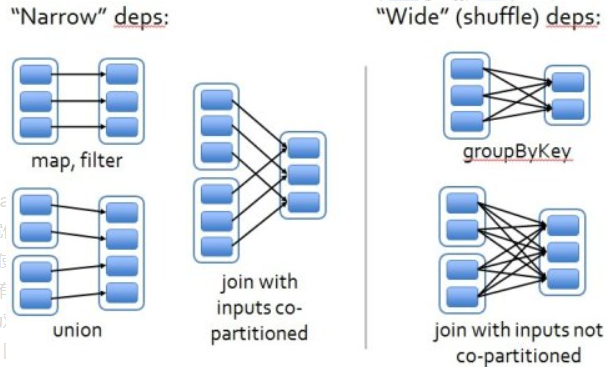
RDD的容错机制实现分布式数据集容错方法有两种:数据检查点和记录更新,RDD采用记录更新的方式:记录所有更新点的成本很高。所以,RDD只支持粗颗粒变换,即只记录单个块(分区)上执行的单个操作,然后创建某个RDD的变换序列(血统 lineage)存储下来(变换序列指,每个RDD都包含了它是如何由其他RDD变换过来的以及如何重建某一块数据的信息);因此RDD的容错机制又称“血统”容错。 要实现这种“血统”容错机制,最大的难题就是如何表达父RDD和子RDD之间的依赖关系。实际上依赖关系可以分两种,窄依赖和宽依赖。
窄依赖:子RDD中的每个数据块只依赖于父RDD中对应的有限个固定的数据块;宽依赖:子RDD中的一个数据块可以依赖于父RDD中的所有数据块。例如:map变换,子RDD中的数据块只依赖于父RDD中对应的一个数据块;groupByKey变换,子RDD中的数据块会依赖于多块父RDD中的数据块,因为一个key可能分布于父RDD的任何一个数据块中, 将依赖关系分类的两个特性:
第一,窄依赖可以在某个计算节点上直接通过计算父RDD的某块数据计算得到子RDD对应的某块数据;宽依赖则要等到父RDD所有数据都计算完成之后,并且父RDD的计算结果进行hash并传到对应节点上之后才能计算子RDD。
第二,数据丢失时,对于窄依赖只需要重新计算丢失的那一块数据来恢复;对于宽依赖则要将祖先RDD中的所有数据块全部重新计算来恢复。
所以在“血统”链特别是有宽依赖的时候,需要在适当的时机设置数据检查点。也是这两个特性要求对于不同依赖关系要采取不同的任务调度机制和容错恢复机制。
RDD运行逻辑
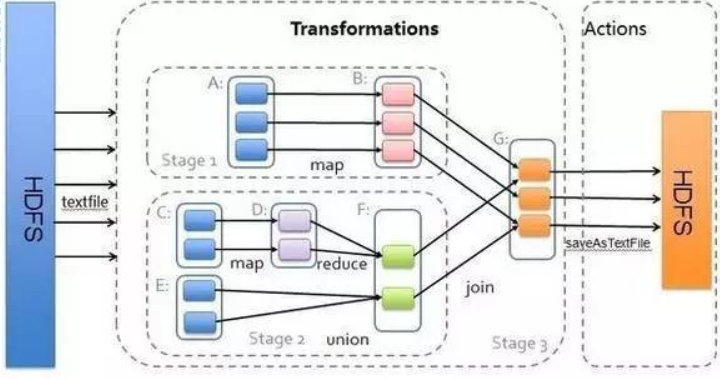
RDD依赖关系

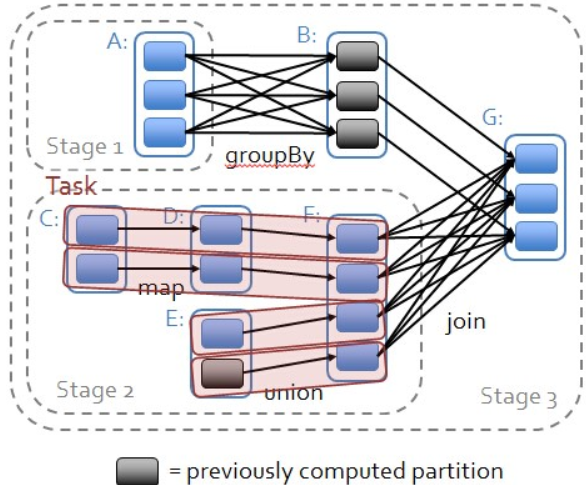
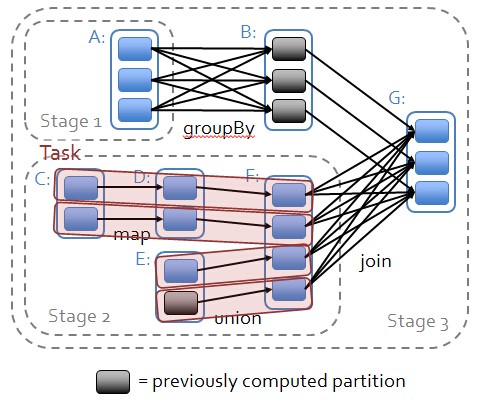
1.从后往前推理,遇到宽依赖就断开,遇到窄依赖就把当前的RDD加入到Stage中;
2.每个Stage里面的Task的数量是由该Stage中最后一个RDD的Partition数量决定的;
3.最后一个Stage里面的任务的类型是ResultTask,前面所有其他Stage里面的任务类型都是ShuffleMapTask;
4.代表当前Stage的算子一定是该Stage的最后一个计算步骤;
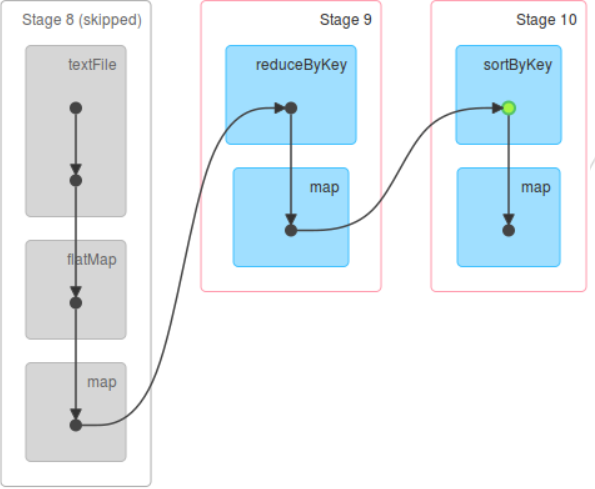
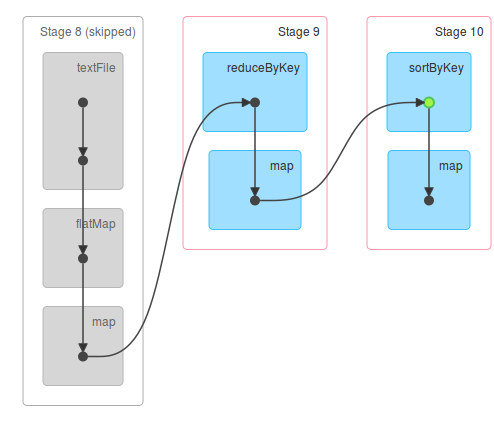
RDD如何操作
1)RDD的创建方式
1)从Hadoop文件系统(或与Hadoop兼容的其他持久化存储系统,如Hive、Cassandra、HBase)输入(例如HDFS)创建。
2)从父RDD转换得到新RDD。
3)通过parallelize或makeRDD将单机数据创建为分布式RDD。
2)RDD的两种操作算子
对于RDD可以有两种操作算子:转换(Transformation)与行动(Action)。
1)转换(Transformation):Transformation操作是延迟计算的,也就是说从一个RDD转换生成另一个RDD的转换操作不是马上执行,需要等到有Action操作的时候才会真正触发运算。
2)行动(Action):Action算子会触发Spark提交作业(Job),并将数据输出Spark系统。
1.Transformation具体内容:
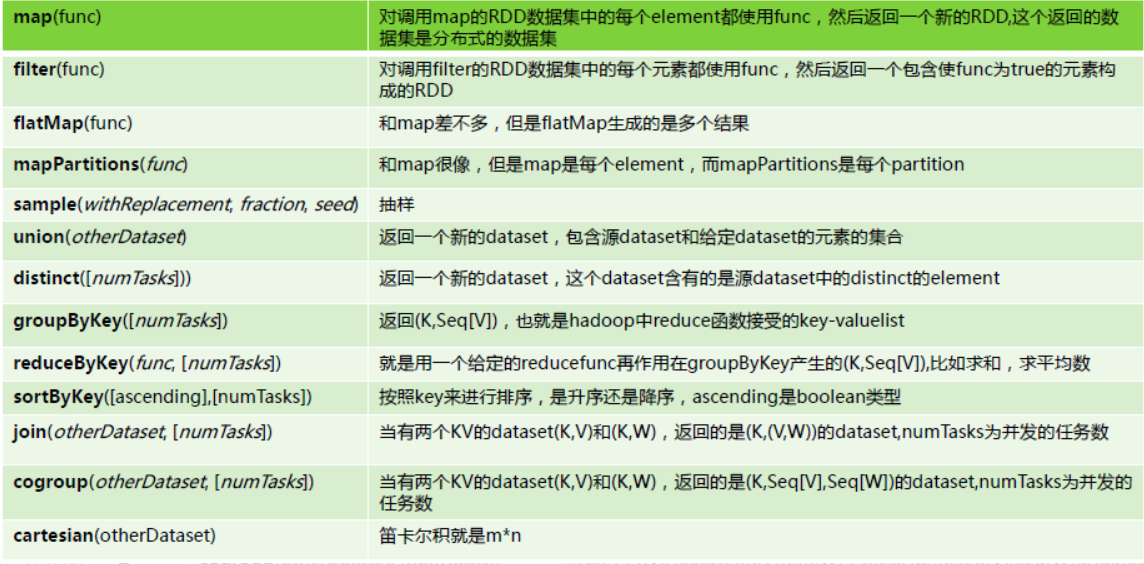
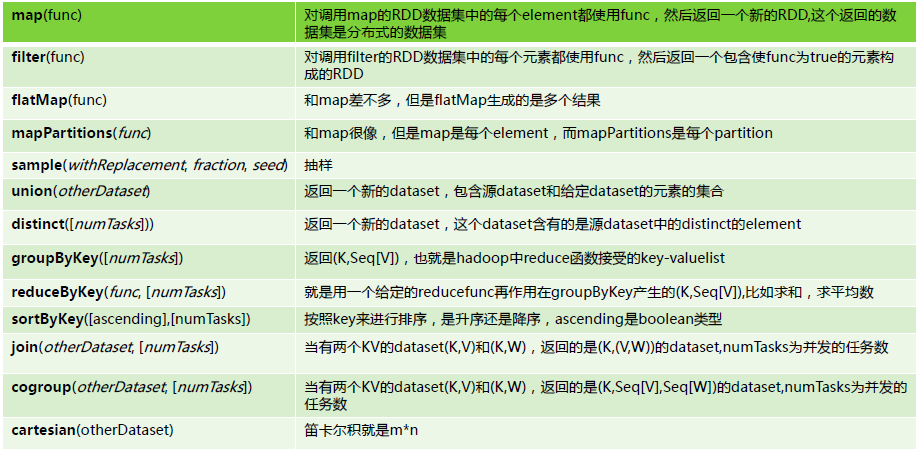
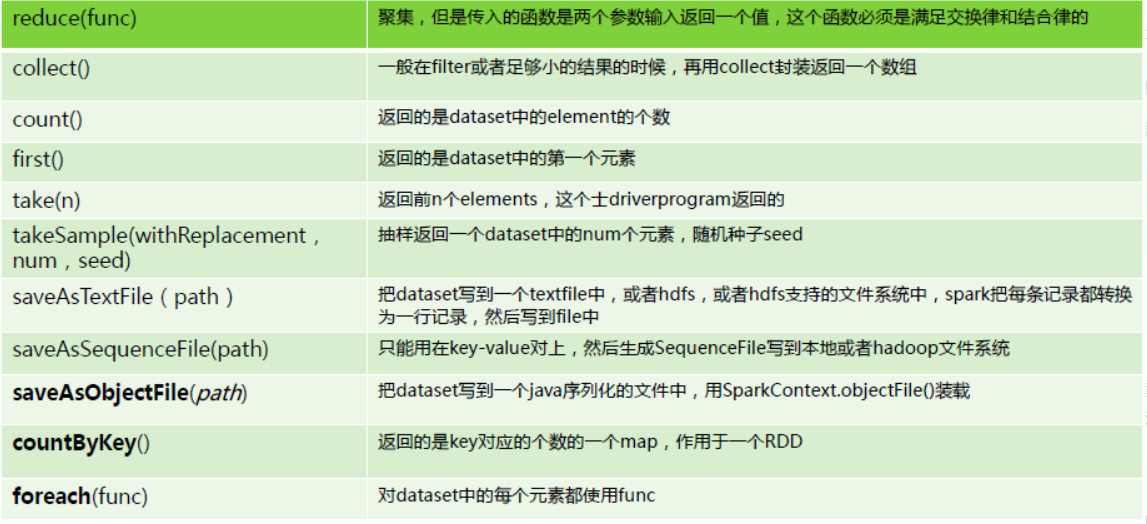
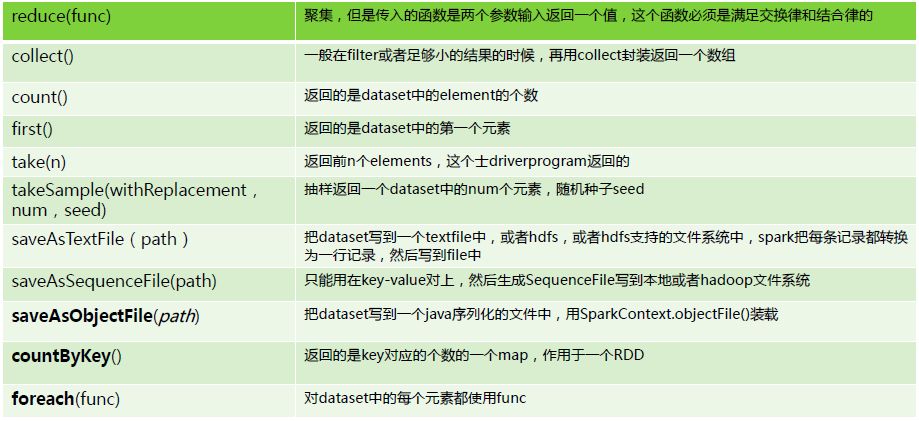
2.Action具体内容:
参考连接:
http://spark.apache.org/examples.html
https://www.cnblogs.com/justisme/p/12731233.html
https://blog.csdn.net/chenxun_2010/article/details/79075693
https://www.jianshu.com/p/c7928366eb4a
https://cloud.tencent.com/developer/article/1332317