一、大型互联网系统特点
-
高并发和大流量 如天猫双11,一分钟内有超过一千万的独立用户访问整个天猫系统,大规模并发用户访问对系统处理能力造成巨大冲击,系统需要有足够强的处理能力
-
高可用 大型互联网系统必须要7X24小时不间断提供服务,为此要对系统做特别的架构设计
-
海量数据存储 因为互联网需要满足大量的用户使用,这些用户会产生很多数据,需要对这些数据进行重组和管理。除了用户提交的数据,互联网还会采集很多其他数据,包括一些用户行为数据,第三方数据和网络爬虫数据,通过大数据技术对这些数据做进一步分析,对用户做更精准的营销和服务,已发现新的业务增长点
-
用户分布广泛,网络情况复杂 互联网是为全球用户服务,为了使所有用户得到统一的良好体验,需要对系统架构进行相关设计
-
安全环境恶劣 互联网是开放的,很容易受到攻击
-
需求变化快,发布频繁 大型网站的产品发布一般以周为单位,每个星期都会发布新的版本来更新产品特性
二、系统处理能力提升的两种途径
-
垂直伸缩 提升单台服务器处理能力,如用更快频率、更多核的CPU,更大的内存,更快的网卡,更多的磁盘组成一台服务器 缺点:
-
到一定程度后,继续增加服务能力需要花费更多的钱,从服务器到小型机,到中型机,再到大型机
-
有物理极限,单台服务器处理能力终究是有极限的,而互联网的需求是没有极限的
-
操作系统的设计或者应用程序的设计制约着垂直伸缩。在单一服务器上运行的程序,就需要充分利用系统资源,然而应用程序的核心价值是处理业务逻辑从而满足用户需求,如果应用程序大量代码去管理系统资源,必然导致应用程序复杂度提高,难以开发和维护
-
-
水平伸缩 并不是提升单台服务器处理能力,而是使用更多服务器,将这些服务器构成一个分布式集群,这个集群统一对外服务,来提高系统整体处理能力
水平伸缩没有垂直伸缩那些问题,只要架构合理,能够将服务器添加到集群中,系统就可以始终正常运行,没有极限,成本也不高。
三、大型互联网架构演化过程
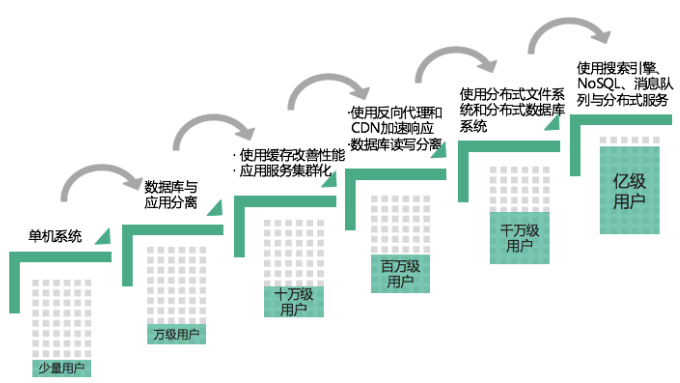
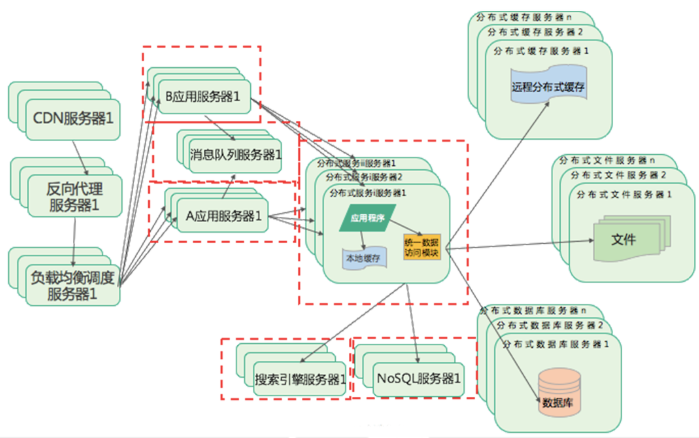
-
单机系统
最早的时候,用户量少,业务逻辑不复杂,也就几个主要功能。应用开发完后部署在服务器上,访问自己服务器上的数据库和文件系统,如下图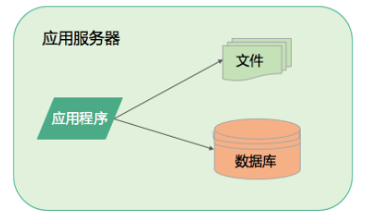
当系统体验良好,使用的用户越来越多,单个服务器就无法承受访问压力了,需要对服务做一次升级,就做了如下图的数据库和文件系统与应用程序分离,部署在不同的服务器上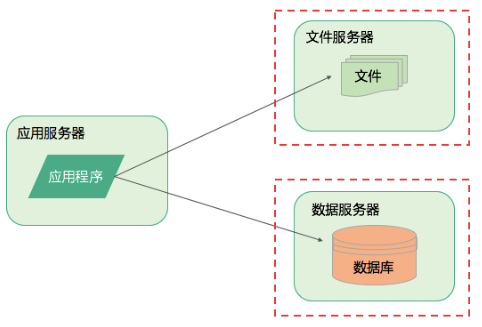
-
缓存
随着用户量继续增大,三台服务器也不能承受访问压力了,那就需要使用缓存来改善性能了。如下图,引入缓存系统,并对数据库做了读写分离,而应用程序部署到多台服务器上,并使用代理服务器做负载均衡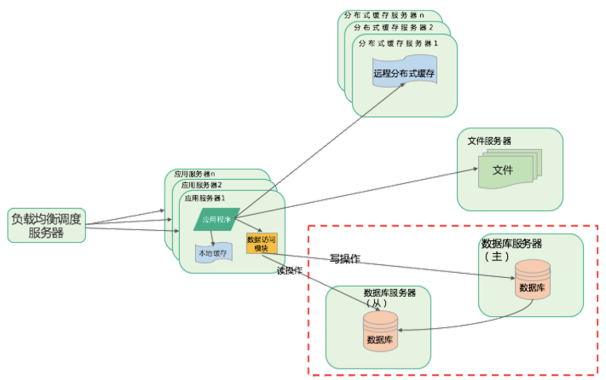
-
反向代理和CDN加速
CDN(Content Delivery Network,内容分发网络)服务就是部署在网络运营商机房里的离用户最近的一个服务器,用户请求先到这里查看有没有需要的数据,如果有就从CDN直接返回,如果没有就通过CDN进一步访问网站的数据中心,得到数据后同时缓存到CDN,供其他用户或下次访问使用,CDN本质也是一个缓存。 用户请求到达网站数据中心后,先在反向代理服务器中查找是否有需要的数据,如果有就直接返回,否则再去请求应用服务器。这两个缓存结合可以返回绝大部分用户请求的数据了,极大减少了应用服务器负载压力,提升数据中心处理能力,响应更多用户并发处理请求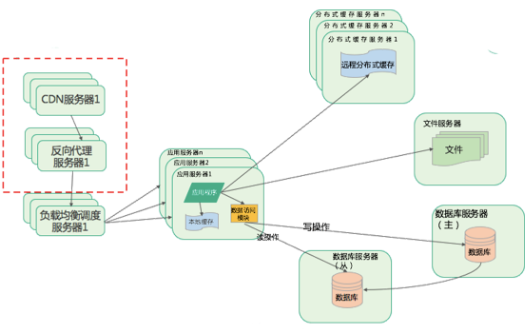
-
分布式文件系统和分布式数据库系统
服务器性能的瓶颈主要是I/O,随着用户量增加,还是会有大量用户到达数据中心,这时数据库和文件系统依然会成为性能瓶颈。 通过一组服务器集群统一对外提供文件服务,这就是分布式文件系统 对数据库做进一步水平伸缩,使用分布式数据库。通过数据分片的方式,将一张表的数据分布在多个物理服务器上,以减少单一数据库的服务器访问压力。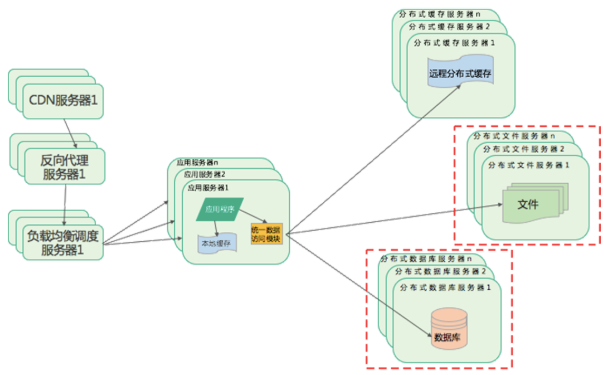
-
消息队列与分布式服务 随着用户量进一步增加,要想实现更强大的计算处理能力,可以使用的技术手段有分布式消息队列、搜索引擎和NoSQL,以及通过分布式服务,将复用的业务分离开来,部署在不同的服务器集群上。