一、本地运行模式
1.1 官方Grep案例
① 创建在hadoop-2.7.2文件下面创建一个input文件夹
[root@hadoop103 hadoop-2.7.2]# mkdir input
② 将Hadoop的xml配置文件复制到input
[root@hadoop103 hadoop-2.7.2]# cp etc/hadoop/*.xml input
③执行share目录下的MapReduce程序
[root@hadoop103 hadoop-2.7.2]# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input output 'dfs[a-z.]+'
④查看输出结果
[root@hadoop103 output]# ll
总用量 4
-rw-r--r--. 1 root root 11 5月 21 20:14 part-r-00000
-rw-r--r--. 1 root root 0 5月 21 20:14 _SUCCESS
1.2 官方WordCount案例
①创建在hadoop-2.7.2文件下面创建一个wcinput文件夹
[root@hadoop103 hadoop-2.7.2]# mkdir wcinput
②wcinput文件下创建一个wc.input文件
[root@hadoop103 wcinput]# vi wc.input
hadoop yarn
hadoop mapreduce
hc
hc
③执行程序
[root@hadoop103 hadoop-2.7.2]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wcinput wcoutput
④查看结果
[root@hadoop103 hadoop-2.7.2]# cat wcoutput/part-r-00000
hc 2
hadoop 2
mapreduce 1
yarn 1
二、伪分布式运行模式
2.1 配置
①配置hadoop-env.sh、yarn-env.sh、mapred-env.sh的JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
配置HDFS:
②配置core-site.xml
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop103:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
③配置hdfs-site.xml
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
配置YARN:
⑤配置yarn-site.xml
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
⑥配置mapred-site.xml
<!-- 指定MR运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
2.2 运行MapReduce程序
①启动
格式化NameNode(第一次启动时格式化):
[root@hadoop103 hadoop-2.7.2]# bin/hdfs namenode -format
启动NameNode:
[root@hadoop103 hadoop-2.7.2]# sbin/hadoop-daemon.sh start namenode
启动DataNode:
[root@hadoop103 hadoop-2.7.2]# sbin/hadoop-daemon.sh start datanode
启动ResoureManager:
[root@hadoop103 hadoop-2.7.2]# sbin/yarn-daemon.sh start resourcemanager
启动NodeManager:
[root@hadoop103 hadoop-2.7.2]# sbin/yarn-daemon.sh start nodemanager
②运行WordCount案例
- 在
HDFS文件系统上创建一个input文件夹
[root@hadoop103 hadoop-2.7.2]# bin/hdfs dfs -mkdir -p /user/hucheng/input
- 将测试文件
wc.input上传到HDFS上
[root@hadoop103 hadoop-2.7.2]# bin/hdfs dfs -put wcinput/wc.input /user/hucheng/input/
- 查看上传的文件
[root@hadoop103 hadoop-2.7.2]# bin/hdfs dfs -cat /user/hucheng/input/wc.input
Hello Hadoop
- 运行
MapReduce程序
[root@hadoop103 hadoop-2.7.2]# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/hucheng/input/ /user/hucheng/output
- 查看输出结果
[root@hadoop103 hadoop-2.7.2]# bin/hdfs dfs -cat /user/hucheng/output/*
Hadoop 1
Hello 1
- 浏览器查看输出文件
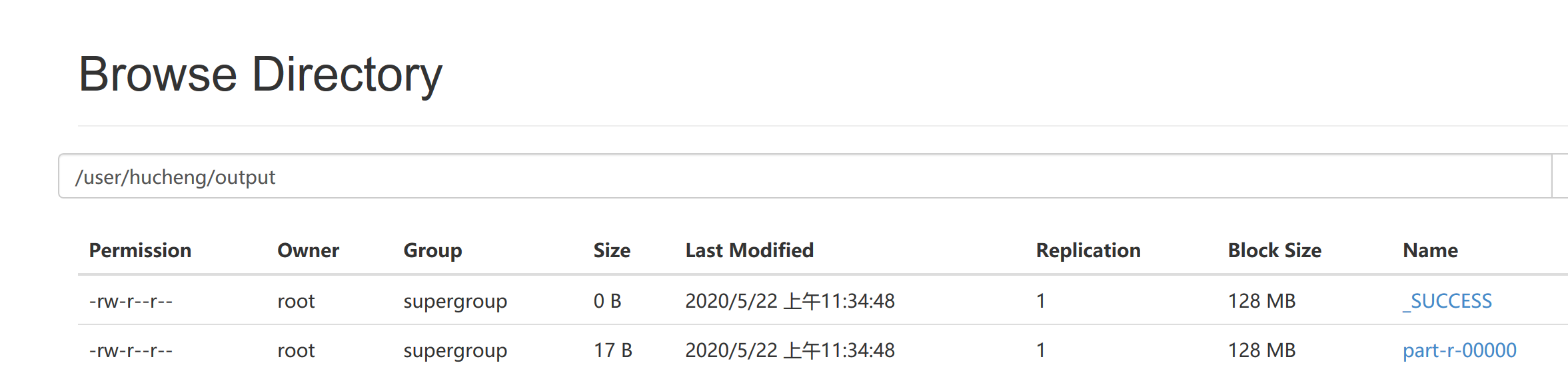
- 下载输出结果
[root@hadoop103 hadoop-2.7.2]# hdfs dfs -get /user/hucheng/output/part-r-00000 ./wcinput/
- 删除输出结果
[root@hadoop103 hadoop-2.7.2]# hdfs dfs -rm -r /user/hucheng/output
2.3 为什么不能一直格式化NameNode
格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。所以格式化NameNode时,一定要先删除data数据和log日志,然后再格式化NameNode。
2.4 配置历史服务器
① 配置mapred-site.xml
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop103:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop103:19888</value>
</property>
②启动历史服务器
[root@hadoop103 hadoop-2.7.2]# sbin/mr-jobhistory-daemon.sh start historyserver
③查看历史服务器是否启动
[root@hadoop103 hadoop-2.7.2]# jps
2583 JobHistoryServer
④查看JobHistory
访问:http://hadoop103:19888/jobhistory
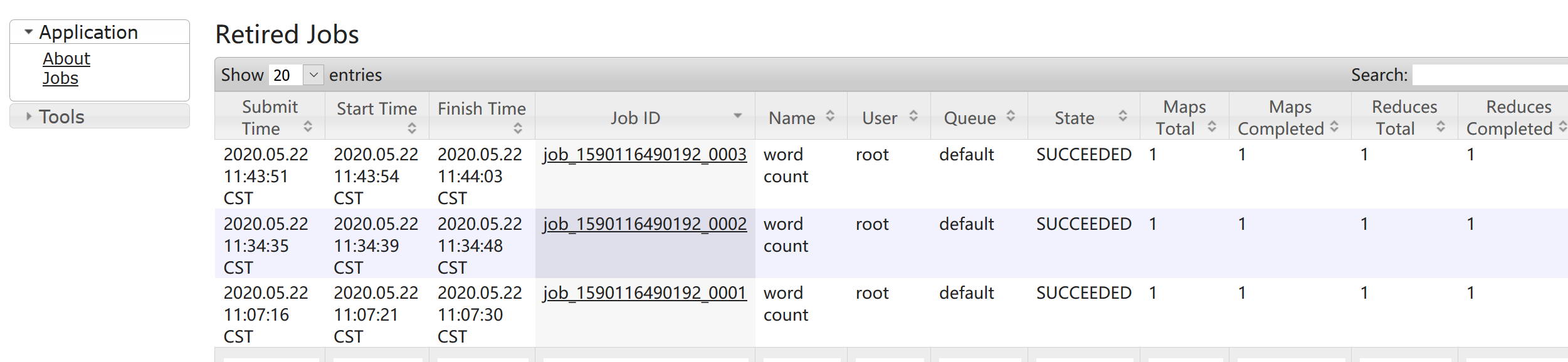
2.5 配置日志聚集
应用运行完成以后,将程序运行日志信息上传到HDFS系统上。可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动NodeManager、ResourceManager和HistoryManager。
①配置yarn-site.xml
<!-- 日志聚集功能使能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
重启后访问JobHistory:
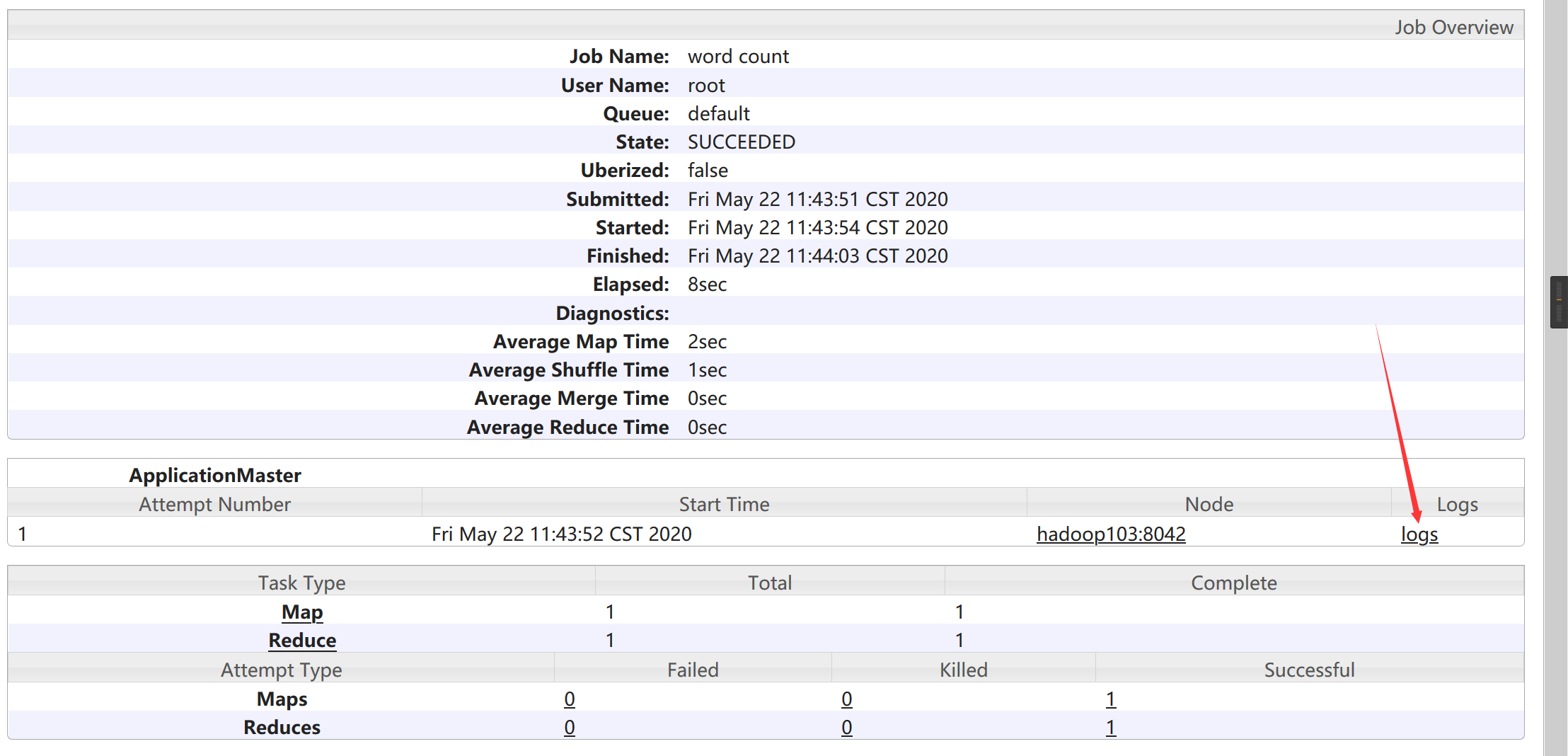
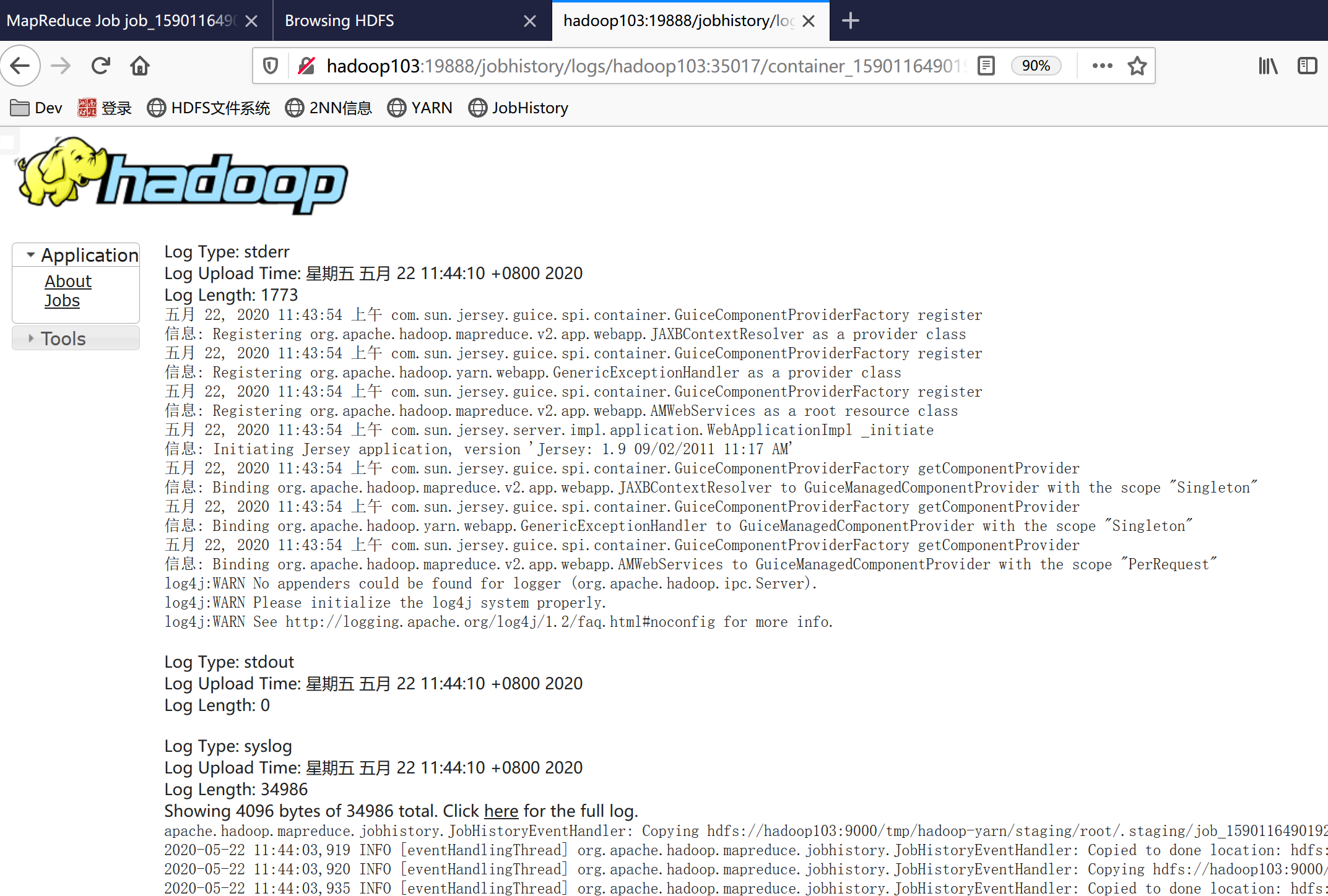
三、完全分布式运行模式
3.1 集群部署规划
通常Hadoop集群通常需要3个DataNode节点、3个NodeManageer节点,再加上NameNode、SecondaryNameNode、ResourceManager,至少需要9台服务器去搭建集群。由于资源的紧缺,我们可以采用以下方式进行混搭:
| hadoop100 | hadoop101 | hadoop102 | |
|---|---|---|---|
| HDFS | NameNode/DataNode | DataNode | SecondaryNameNode/DataNode |
| YARN | NodeManager | ResourceManager/NodeManager | NodeManager |
3.2 配置集群
①每台服务器/opt/module/hadoop-2.7.2/etc/hadoop下的hadoop-env.sh、mapred-env.sh、yarn-env.sh添加上JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
②配置核心配置文件core-site.xml
[root@hadoop100 hadoop]$ vim core-site.xml
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop100:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
③配置HDFS配置文件hdfs-site.xml
<!--主机数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定Hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop102:50090</value>
</property>
④配置YARN配置文件yarn-site.xml
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop101</value>
</property>
⑤配置MapReduce配置文件mapred-site.xml
<!-- 指定MR运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
⑥分发配置文件到其他主机
[root@hadoop100 hadoop]$ xsync /opt/module/hadoop-2.7.2/
3.3 集群单点启动
①第一次启动格式化NameNode,注意实在配置NameNode节点下的主机格式化
[root@hadoop100 hadoop-2.7.2]$ hdfs namenode -format
②Hadoop100主机启动NameNode、DataNode、NodeManager
[root@hadoop100 hadoop]$ hadoop-daemon.sh start namenode
[root@hadoop100 hadoop]$ hadoop-daemon.sh start datanode
[root@hadoop100 hadoop]$ hadoop-daemon.sh start nodemanager
[root@hadoop100 hadoop]$ jps
[root@hadoop100 hadoop-2.7.2]# jps
1219 NameNode
1653 NodeManager
2216 Jps
1355 DataNode
③Hadoop101主机启动DataNode、NodeManager、ResourceManager
[root@hadoop101 hadoop]$ hadoop-daemon.sh start datanode
[root@hadoop101 hadoop]$ hadoop-daemon.sh start nodemanager
[root@hadoop101 hadoop]$ hadoop-daemon.sh start resourcemanager
[root@hadoop101 hadoop]$ jps
[root@hadoop101 hadoop-2.7.2]# jps
2042 Jps
1085 DataNode
1517 NodeManager
1230 ResourceManager
④Hadoop102主机启动DataNode、SecondaryNameNode、NodeManager
[root@hadoop102 hadoop]$ hadoop-daemon.sh start datanode
[root@hadoop102 hadoop]$ hadoop-daemon.sh start secondarynamenode
[root@hadoop102 hadoop]$ hadoop-daemon.sh start nodemanager
[root@hadoop102 hadoop]# jps
1184 SecondaryNameNode
1077 DataNode
1928 Jps
1230 NodeManager
3.4 群启集群
当Hadoop集群中的节点很多时,采用上面的单点启动显然是不行的,下面介绍如何一键群启集群。
①配置slaves
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行
[root@hadoop100 hadoop]$ vim /opt/module/hadoop-2.7.2/etc/hadoop/slaves
hadoop100
hadoop101
hadoop102
同步所有节点配置文件
[root@hadoop100 hadoop]$ xsync slaves
②格式化NameNode
如果集群是第一次启动,需要格式化NameNode(注意格式化之前,一定要先停止上次启动的所有namenode和datanode进程,然后再删除data和log数据)
[root@hadoop100 hadoop-2.7.2]$ bin/hdfs namenode -format
③启动HDFS
[root@hadoop100 hadoop-2.7.2]$ sbin/start-dfs.sh
④启动YARN
[root@hadoop101 hadoop-2.7.2]$ sbin/start-yarn.sh
注意:NameNode和ResourceManger如果不是同一台机器,不能在NameNode上启动 YARN,应该在ResouceManager所在的机器上启动YARN。
3.5 集群时间同步
时间同步的方式:找一个机器,作为时间服务器,所有的机器与这台集群时间进行定时的同步,比如,每隔十分钟,同步一次时间。
时间服务器配置(必须root用户)
①安装ntp
[root@hadoop100 ~]# yum -y install ntp
②修改ntp配置文件
[root@hadoop100 ~]# vim /etc/ntp.conf
a) 授权192.168.1.0-192.168.1.255网段上的所有机器可以从这台机器上查询和同步时间:
#restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap为
restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
b)集群在局域网中,不使用其他互联网上的时间,注释掉下面:
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
c)当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步,添加:
server 127.127.1.0
fudge 127.127.1.0 stratum 10
③修改/etc/sysconfig/ntpd文件
[root@hadoop100 ~]# vim /etc/sysconfig/ntpd
#让硬件时间与系统时间一起同步
SYNC_HWCLOCK=yes
④重新启动ntpd服务
[root@hadoop100 ~]# systemctl start ntpd
⑤设置ntpd服务开机启动
[root@hadoop100 ~]# chkconfig ntpd on
其他机器配置(必须root用户)
在其他机器配置10分钟与时间服务器同步一次,编写定时任务:
[root@hadoop101 ~]# crontab -e
*/10 * * * * /usr/sbin/ntpdate hadoop100
3.6 集群监控地址
HDFS文件系统:http://hadoop100:50070/dfshealth.html#tab-overview
SecondaryNameNode信息:http://hadoop102:50090/status.html
YARN信息:http://hadoop101:8088/cluster
查看JobHistory:http://hadoop101:19888/jobhistory