摘要:当我们希望MySQL能够以更高的性能运行查询时,最好的办法就是弄清楚MySQL是如何优化和执行查询的。
本文分享自华为云社区《mysql执行查询全流程解析》,作者:breakDraw。
mysql执行查询的过程
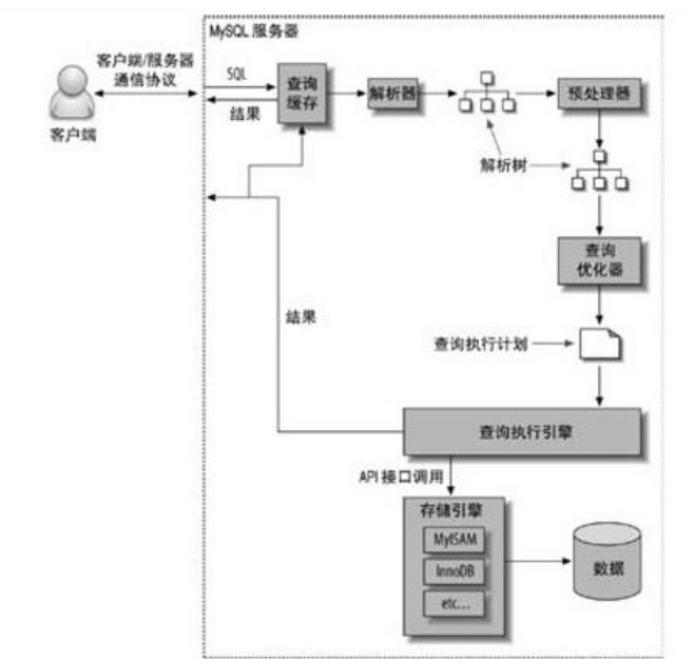
- 客户端先发送查询语句给服务器
- 服务器检查缓存,如果存在则返回
- 进行sql解析,生成解析树,再预处理,生成第二个解析树,最后再经过优化器,生成真正的执行计划
- 根据执行计划,调用存储引擎的API来执行查询
- 将结果返回给客户端。
一、客户端到服务端之间的原理
- 客户端和服务端之间是半双工的, 即一个通道内只能一个在发一个接收, 不能同时互相发互相接收
- 客户端只会发送一个数据包给服务端,并不会在应用层拆成2个数据包去发(max_allowed_packet可以设置数据包最大长), 这关系到sql语句不能太长。
- 服务端返回给客户端可以有多个数据包, 但是客户端必须完整接收,不能接到一半停掉连接或用连接去做其他事(UI界面可以操作,不同的线程)
- 例如java,如果没设置fetchSize,那么都是一次性把结果读进内存。当你使用resultSet的时候,其实已经全部进来了,而不是一条条从服务端获取。————使用fetch Size边读边处理的坏处: 服务端占用的资源时间变久了。
查询mysql服务此时的状态
使用 show full processlist 命令可以查看mysql服务端某些线程的状态
- Sleep 正在等待客户端发送新的请求
- Query 正在执行查询, 或者发结果发给客户端
- Locked 正在等待表锁(注意表锁是服务器层的, 而行锁是存储引擎层的,行锁时状态为query)
- Analyzing and statistics 正在生成查询的计划或者收集统计信息
- copying to tmp table 临时表操作,一般是正在做group by等操作
- sorting result 正在对结果集做排序
- sending data 正在服务器线程之间传数据
二、查询缓存
- 缓存的查询在sql解析之前进行。
- 缓存的查找通过一个 对大小写敏感的哈希表实现,即直接比对sql字符串。
- 因此只要有一个字节不同,都不会匹配中。(毕竟还没开始解析,大小写什么的他也不知道要不要区分)
- 第7章中有更详细的查询缓存。
三、查询优化处理
1.语法解析器和预处理
- 这里就是把sql做解析, 变成一个解析树。解析时会做mysql语法规则验证。
- 语法解析器: 检查关键字错误、关键字顺序、引号匹配
- 预处理:和元数据关联校验, 检查数据表和列是否存在,解析名字和别名。
- 权限校验
2.查询优化器(重点)
- mysql可能会生成多种计划, 他会分别计算一个预测成本值,然后选一个成本最小的计划
- 计算信息来自于 表的页面个数、索引分布、长度、个数、数据行长度
- 因为多种原因,可能不会选择到最优的计划,有偏差
- 静态优化和动态优化的区别:
静态优化类似“编译期优化”,只和语句结构有关,和具体值无关
动态优化是在运行中去优化的,需要依赖索引行数、where取值,执行次数可能比静态优化要多。
mysql的优化类型
- 关联表(join)的顺序可能会变
- outer join可能会变成内连接
- 优化条件表达式, 例如 5=5 AND a>5被简化成a>5
- 优化MAX\MIN, 如果是MAX(索引),那么直接拿B+树的第一条或者最后一条即可。
- 当发现某个查询或者表达式的结果是可以提前计算出来的时候,就会优化成常数
- 索引覆盖,如果只要返回索引列,就不会走到最底层去。
- 子查询优化
- 提前终止查询(例如LIMIT)
- 等值传播: join中可能把左表的where 拿给右表一起用
- IN(1,2,3,4,5,6)这个条件, 并不是简单遍历判断, 会先排序,然后用二分去判断是否存在。
3.数据和索引的统计信息
- 统计信息是存储引擎去计算的,不同的存储引擎有不同的统计信息
- 服务器层生成查询计划时,会向存储引擎获取这些信息。
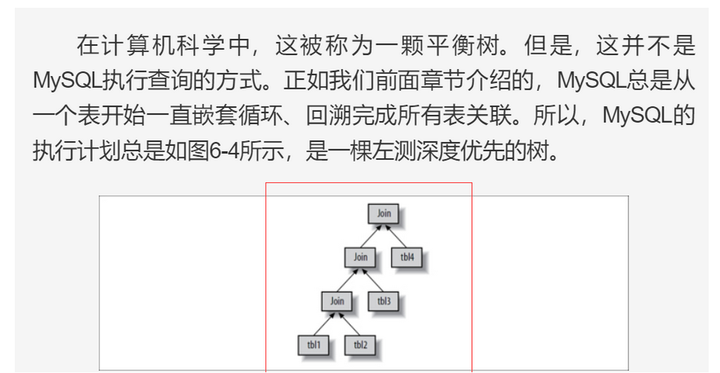
4.MYSQL对关联查询的执行
- join查询的本质其实是读取临时表做关联
- 例如a inner join b on a.id=b.id where a.xx=y
- 遍历a的每一行(此时a表本质上是 select * from a where a.xx=y)
- 在那行中a的id被定下来, 那么就会去获取一个临时表,临时表为(select * from b where a.id = id)
- 接着用这个临时表和a那一行拼接,输出多行。
- 然后再用这里的结果作为临时表,给更上层的关联去用(嵌套查询的含义)。
- 如果是left join,则就是临时表如果为空,则给a那一行拼接一个null。
5. 执行计划中的join树
6. 关联查询优化器
- join实际执行的顺序会关系到性能
- 例如a\b\c三个表关联, 可能先让a和b关联得到的临时表里的记录只有10条, 而如果让a和c先关联,会有10000条, 那么后面的效率就会截然不同
- EXPLAIN EXTENDED可以展示关联的顺序
- STRAIGHT_JOIN可以手动指定关联顺序
- mysql自己会评估搜索一个最优的顺序, 但如果join表太多,则无法搜完所有结果(O(n!)), 那时候就会采用贪心。 是否使用贪心算法的边界值可以根据optimizer_seartch_depth去指定。
7.排序优化
- 如果排序的量小,就用内存快速排序;如果排序的量大,就用文件排序
- mysql有2种取排序数据的方式:
- 两次传输排序: 先取要排序的字段加行序号,按照字段排序好之后,再根据行索引一条条取读
优点: 排序时占用内存小。
缺点: 排序之后读的过程会很慢,根据行序号取读不是很方便 - 单次传输排序: 直接把行读出来(行里只有需要用的列,不一定是整行) ,然后排序
优点: 把全部行读出来相当于顺序IO,读取速度快
缺点: 可能会很大导致需要文件排序
- 关联查询order by的注意事项
如果order by的列 都 来自关联的 第一张 表,则直接第一张表join的时候就排序了。
除此之外!! 都是全部join完,再排序! 就算用了limit,也是全部join+排序后, 再limit的!
四、查询执行计划
- 执行计划是一个数据结构
五、返回结果给客户端
- 用tcp封包并逐步传送,而不是全部准备好再发送。