在我们的开发过程中,会遇到这样的情况:
给出下面的信息,让我们进行建立索引,并且进行搜索信息

这个时候,我们应该怎样处理呢?
要实现这样的功能,其实使用lucene会变得简单很多!!
========================================
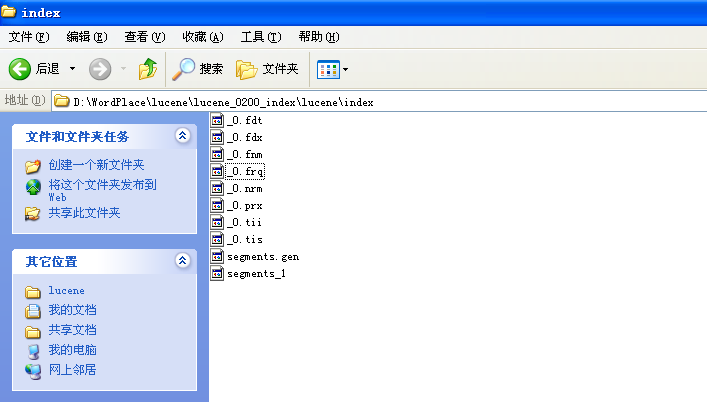
项目结构:

运行
1 @Test 2 public void testIndex(){ 3 LuceneUtil util = new LuceneUtil(); 4 util.index(); 5 }
效果:
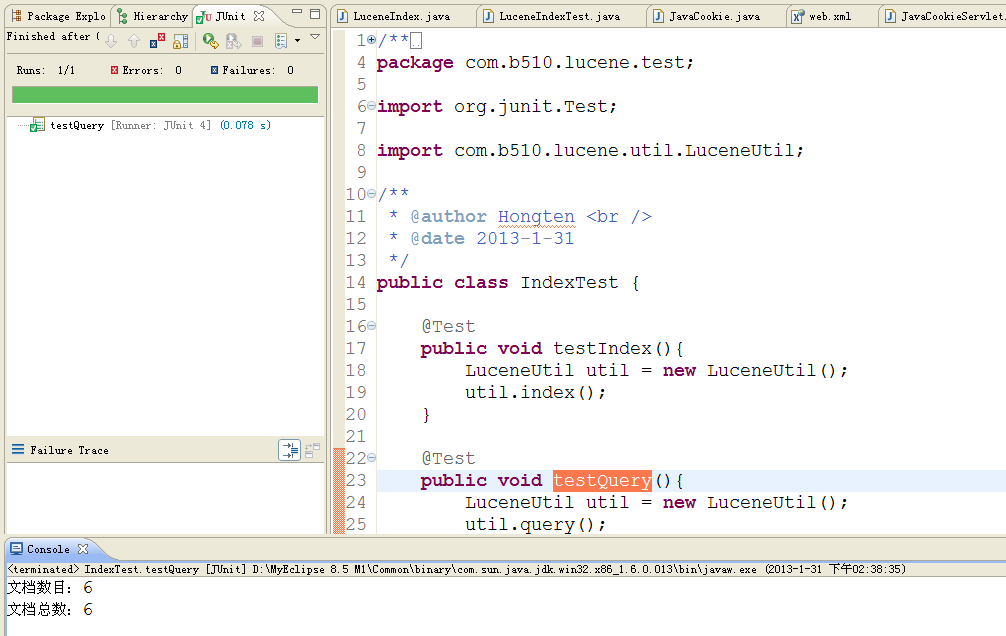
运行
1 @Test 2 public void testQuery(){ 3 LuceneUtil util = new LuceneUtil(); 4 util.query(); 5 }
效果:
=========================================================
代码部分:
=========================================================
/lucene_0200_index/src/com/b510/lucene/util/LuceneUtil.java
1 /** 2 * 3 */ 4 package com.b510.lucene.util; 5 6 import java.io.File; 7 import java.io.IOException; 8 9 import org.apache.lucene.analysis.standard.StandardAnalyzer; 10 import org.apache.lucene.document.Document; 11 import org.apache.lucene.document.Field; 12 import org.apache.lucene.index.CorruptIndexException; 13 import org.apache.lucene.index.IndexReader; 14 import org.apache.lucene.index.IndexWriter; 15 import org.apache.lucene.index.IndexWriterConfig; 16 import org.apache.lucene.store.Directory; 17 import org.apache.lucene.store.FSDirectory; 18 import org.apache.lucene.store.LockObtainFailedException; 19 import org.apache.lucene.util.Version; 20 21 /** 22 * @author Hongten <br /> 23 * @date 2013-1-31 24 */ 25 public class LuceneUtil { 26 27 /** 28 * 邮件id 29 */ 30 private String[] ids = { "1", "2", "3", "4", "5", "6" }; 31 /** 32 * 邮箱 33 */ 34 private String[] emails = { "aa@sina.com", "bb@foxmail.com", "cc@qq.com", 35 "dd@163.com", "ee@gmail.com", "ff@sina.com" }; 36 /** 37 * 邮件内容 38 */ 39 private String[] contents = { "hello,aa", "hello,bb", "hello,cc", 40 "hello,dd", "hello,ee", "hello,ff" }; 41 /** 42 * 邮件的附件 43 */ 44 private int[] attachs = { 1, 5, 3, 4, 2, 6 }; 45 /** 46 * 收件人的名称 47 */ 48 private String[] names = { "hongten", "hanyuan", "Devide", "Tom", "Steven", 49 "Shala" }; 50 51 private Directory directory = null; 52 53 public LuceneUtil() { 54 try { 55 directory = FSDirectory.open(new File( 56 "D:/WordPlace/lucene/lucene_0200_index/lucene/index")); 57 } catch (IOException e) { 58 e.printStackTrace(); 59 } 60 } 61 62 /** 63 * 创建索引 64 */ 65 public void index() { 66 IndexWriter writer = null; 67 try { 68 writer = new IndexWriter(directory, new IndexWriterConfig( 69 Version.LUCENE_35, new StandardAnalyzer(Version.LUCENE_35))); 70 // 创建文档 71 Document document = null; 72 for (int i = 0; i < ids.length; i++) { 73 // Field.Store.YES:将会存储域值,原始字符串的值会保存在索引,以此可以进行相应的回复操作,对于主键,标题可以是这种方式存储 74 // Field.Store.NO:不会存储域值,通常与Index.ANAYLIZED和起来使用,索引一些如文章正文等不需要恢复的文档 75 // ============================== 76 // Field.Index.ANALYZED:进行分词和索引,适用于标题,内容等 77 // Field.Index.NOT_ANALYZED:进行索引,但是不进行分词,如身份证号码,姓名,ID等,适用于精确搜索 78 // Field.Index.ANALYZED_NOT_NORMS:进行分词,但是不进行存储norms信息,这个norms中包括了创建索引的时间和权值等信息 79 // Field.Index.NOT_ANALYZED_NOT_NORMS:不进行分词也不进行存储norms信息(不推荐) 80 // Field.Index.NO:不进行分词 81 document = new Document(); 82 document.add(new Field("id", ids[i], Field.Store.YES, 83 Field.Index.NOT_ANALYZED_NO_NORMS)); 84 document.add(new Field("email", emails[i], Field.Store.YES, 85 Field.Index.NOT_ANALYZED)); 86 document.add(new Field("content", contents[i], Field.Store.YES, 87 Field.Index.ANALYZED)); 88 // document.add(new 89 // Field("attach",attachs[i],Field.Store.YES,Field.Index.NOT_ANALYZED_NO_NORMS)); 90 document.add(new Field("name", names[i], Field.Store.YES, 91 Field.Index.NOT_ANALYZED_NO_NORMS)); 92 writer.addDocument(document); 93 } 94 } catch (CorruptIndexException e) { 95 e.printStackTrace(); 96 } catch (LockObtainFailedException e) { 97 e.printStackTrace(); 98 } catch (IOException e) { 99 e.printStackTrace(); 100 } finally { 101 if (writer != null) { 102 try { 103 writer.close(); 104 } catch (CorruptIndexException e) { 105 e.printStackTrace(); 106 } catch (IOException e) { 107 e.printStackTrace(); 108 } 109 } 110 } 111 } 112 113 /** 114 * 查询索引 115 */ 116 public void query() { 117 try { 118 IndexReader reader = IndexReader.open(directory); 119 System.out.println("文档数目:" + reader.numDocs()); 120 System.out.println("文档总数:" + reader.maxDoc()); 121 } catch (CorruptIndexException e) { 122 e.printStackTrace(); 123 } catch (IOException e) { 124 e.printStackTrace(); 125 } 126 } 127 }
/lucene_0200_index/src/com/b510/lucene/test/IndexTest.java
/** * */ package com.b510.lucene.test; import org.junit.Test; import com.b510.lucene.util.LuceneUtil; /** * @author Hongten <br /> * @date 2013-1-31 */ public class IndexTest { @Test public void testIndex(){ LuceneUtil util = new LuceneUtil(); util.index(); } @Test public void testQuery(){ LuceneUtil util = new LuceneUtil(); util.query(); } }
项目源码:https://files.cnblogs.com/hongten/lucene_0200_index.zip
I'm Hongten
