0.个人信息:
姓名:张越
学号:201821121006
班级:计算1811
1.记录内存使用状况:
//每个进程分配到的内存块的描述
struct allocated_block
{
int pid;
int size; //进程大小
int start_addr; //进程分配到的内存块的起始地址
char process_name[PROCESS_NAME_LEN]; //进程名
struct allocated_block *next; //指向下一个进程控制块
};
首先我们需要进行上述链表allocated_block进行定义,其中具体描述包括:pid(进程id),size(进程大小),start_addr(开始地址),pro_name[](进程名数组),next(next指针)。还需要一个这个链表计算机的内存块信息,头指针初始值设置为空,一旦进行内存分配了,头指针进行向下移动。
2.记录空闲分区
//描述每一个空闲块的数据结构
struct free_block_type
{
int size; //空闲块大小
int start_addr; //空闲块起始位置
struct free_block_type *next; //指向下一个空闲块
};
还是用链表来记录空闲分区,首先定义一个结构体free_block_type来存放空闲内存块,接着定义一个全局指针变量free_block来指向链表的头结点。当内存空间进行了初始化之后,所有的内存分区都是空闲分区。
3. 内存分配算法
首次适应算法:
//按照首次适应算法给新进程分配内存空间
int allocate_FF(struct allocated_block *ab)
{
int ret;
struct free_block_type *pre= NULL,*ff= free_block;
if(ff== NULL)
return -1;
while(ff!= NULL)
{
if(ff->size>= ab->size)
{
ret= allocate(pre,ff,ab);
break;
}
pre= ff;
pre= pre->next;
}
if(ff== NULL&¤t_free_mem_size> ab->size)
ret= mem_retrench(ab);
else
ret= -2;
rearrange_FF();
return ret;
}
原理:该算法从空闲分区链首开始查找,直至找到一个能满足其大小要求的空闲分区为止。然后再按照作业的大小,从该分区中划出一块内存分配给请求者,余下的空闲分区仍留在空闲分区链 中。
特点: 该算法倾向于使用内存中低地址部分的空闲区,在高地址部分的空闲区很少被利用,从而保留了高地址部分的大空闲区。显然为以后到达的大作业分配大的内存空间创造了条件。
4.内存释放算法
//释放ab数据结构结点
int dispose(struct allocated_block *free_ab)
{
struct allocated_block *pre,*ab;
if(free_block== NULL)
return -1;
if(free_ab== allocated_block_head) //如果要释放第一个结点
{
allocated_block_head= allocated_block_head->next;
free(free_ab);
}
else
{
pre= allocated_block_head;
ab= allocated_block_head->next;
//找到free_ab
while(ab!= free_ab)
{
pre= ab;
ab= ab->next;
}
pre->next= ab->next;
free(ab);
}
return 1;
}
//将ab所表示的已分配区归还,并进行可能的合并
int free_mem(struct allocated_block *ab)
{
int algorithm= ma_algorithm;
struct free_block_type *fbt,*pre,*work;
fbt= (struct free_block_type*)malloc(sizeof(struct free_block_type));
if(!fbt)
return -1;
pre= free_block;
fbt->start_addr= ab->start_addr;
fbt->size= ab->size;
fbt->next= NULL;
if(pre!= NULL)
{
while(pre->next!= NULL)
pre= pre->next;
pre->next= fbt;
}
else
{
free_block= fbt;
}
rearrange_FF();
pre= free_block;
work= pre->next;
while(work!= NULL)
{
if(pre->start_addr+ pre->size== work->start_addr)
{
pre->size+= work->size;
free(work);
work= pre->next;
}
else
{
pre= work;
work= work->next;
}
}
current_free_mem_size+= ab->size;
return 1;
}
//删除进程,归还分配的存储空间,并删除描述该进程内存分配的结点
void kill_process()
{
struct allocated_block *ab;
int pid;
printf("Kill Process,pid=");
scanf("%d",&pid);
getchar();
ab= find_process(pid);
if(ab!= NULL)
{
free_mem(ab); //释放ab所表示的分配区
dispose(ab); //释放ab数据结构结点
}
}
关于内存释放分为三个步骤:首先是释放ab结点,接着将ab所表示的已分配区归还,并进行可能的合并,最后删除进程,归还分配的存储空间,并删除描述该进程内存分配的结点。
5.运行结果:
测试代码:
int main(int argc, char const *argv[]){ int p1,p2; int total=0; //统计分配内存的次数 free_block = init_free_block(mem_size); //初始化空闲区域 Prc prc[PROCESS_NUM]; init_program(prc,PROCESS_NUM);//初始化进程 srand( (unsigned)time( NULL ) ); for(int i=0;i<DATA_NUM;++i){ p1=rand()%2; int count=0; for(int j=0;j<PROCESS_NUM;++j){ if(prc[j].pid!=-1) count++; } if((count==PROCESS_NUM && p1==0)||total==10){ p1=1; } if(count==0 && p1==1){ p1=0; } if(p1==0){ do{ p2=rand()%PROCESS_NUM; }while(prc[p2].pid!=-1); alloc_process(prc[p2]); prc[p2].pid=pid; total++; display_mem_usage();//输出内存使用情况 } else { do{ p2=rand()%PROCESS_NUM; }while(prc[p2].pid==-1); kill_process(prc[p2].pid); prc[p2].pid=-1; display_mem_usage(); } } }
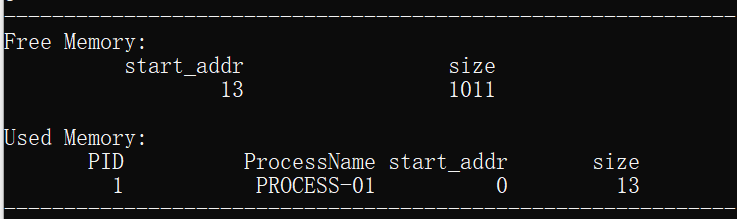

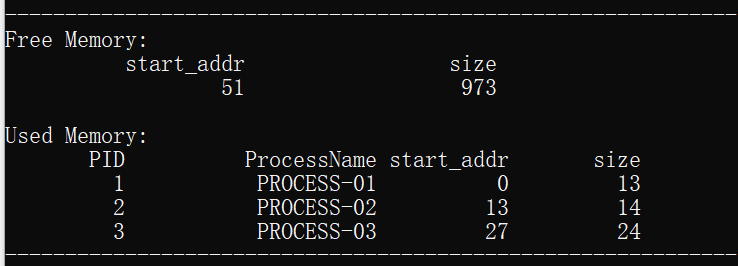
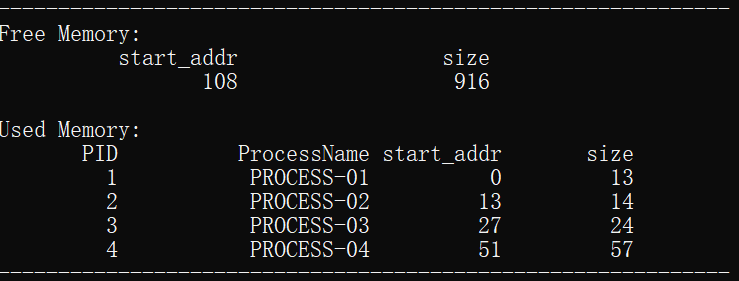
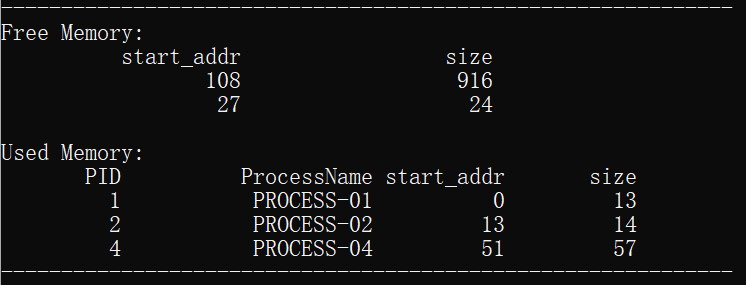
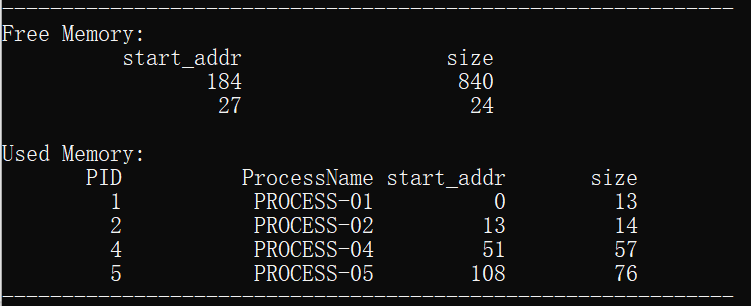
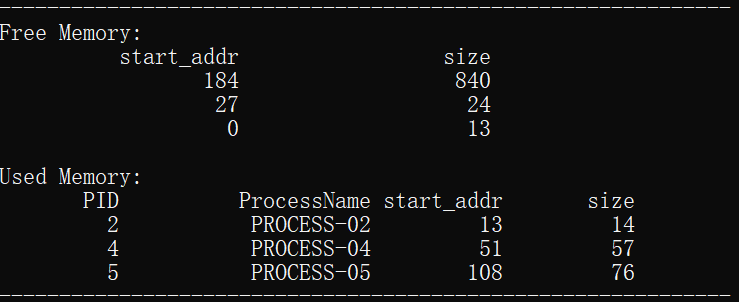
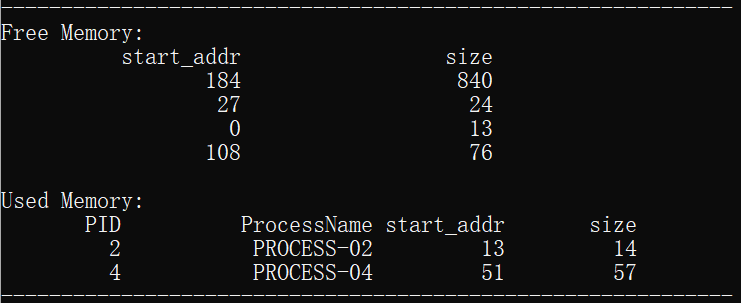
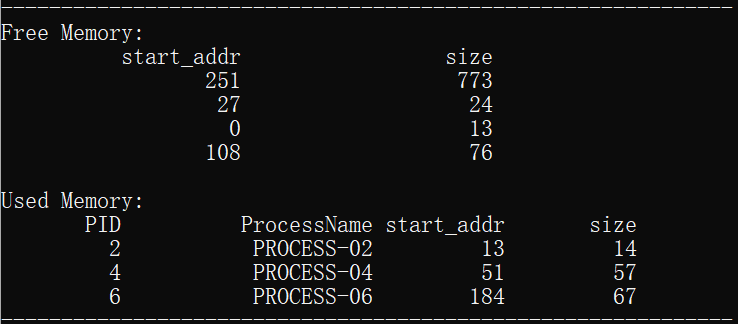
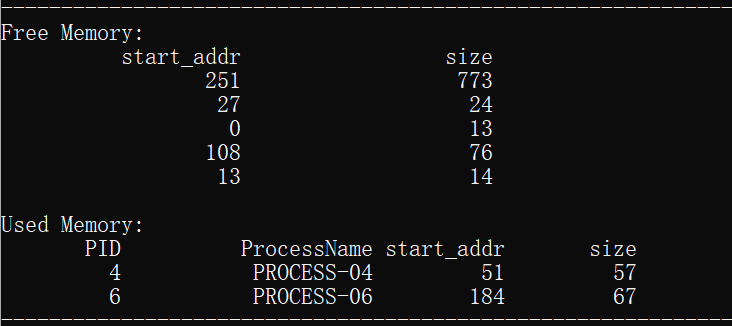
下面对前4组数据进行具体的内容分析:
说明:我设置的初始空闲分区的内存范围为0-1024。
1.为进程process_01分配了起始地址为0,大小为13的内存空间,分配结束后空闲分区的剩余存储地址从13开始,大小为1011的空间。
2.为进程process_02分配了起始地址为13,大小为14的内存空间,分配结束后空闲分区的剩余存储地址从27开始,大小为997的空间。
3.为进程process_03分配了起始地址为27,大小为24的存储空间,分配结束后空闲分区的剩余存储地址从51开始,大小为973的空间。
3.为进程process_04分配了起始地址为51,大小为57的存储空间,分配结束后空闲分区的剩余存储地址从51开始,大小为916的空间
参考链接:
https://www.cnblogs.com/XNQC1314/p/9065236.html
https://blog.csdn.net/weixin_39282491/article/details/81045441