Redis的持久化方式
一、什么是持久化?
持久化(Persistence),即把数据(如内存中的对象)保存到可永久保存的存储设备中(如磁盘)。持久化的主要应用是将内存中的对象存储在数据库中,或者存储在磁盘文件中、XML数据文件中等等。

二、Redis为什么要持久化?
Redis是一个内存数据库,所有的数据将保存在内存中,这与传统的MySQL、Oracle、SqlServer等关系型数据库直接把数据保存到硬盘相比,Redis的读写效率非常高。但是保存在内存中也有一个很大的缺陷,一旦断电或者宕机,内存数据库中的内容将会全部丢失。为了弥补这一缺陷,Redis提供了把内存数据持久化到硬盘文件,以及通过备份文件来恢复数据的功能。
三、Redis官方提供了不同级别的持久化方式
1、RDB(Redis DataBase)
在指定的时间间隔内生成数据集的时间点快照(point-in-time snapshot)。
它是Redis数据库中数据的内存快照,并且是一个二进制文件(默认名称为dump.rdb,可修改),存储了文件生成时Redis数据库中所有的数据内容。可用于Redis的数据备份、转移与恢复。
1) 配置文件参数及说明
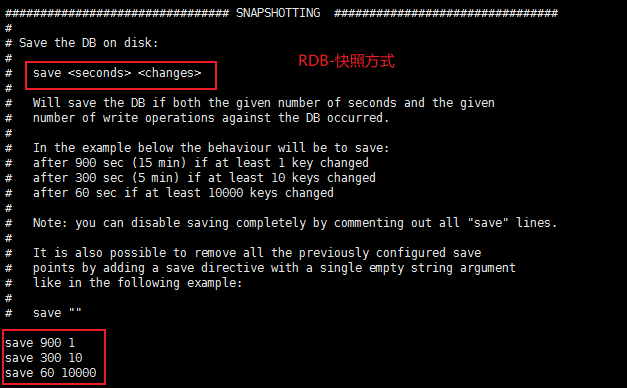
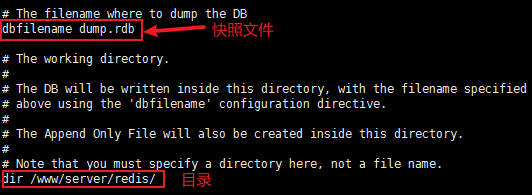
在redis.conf配置文件中可以配置:
################################ SNAPSHOTTING ################################ # Redis触发自动备份的触发策略 # save <seconds> <changes> save 900 1 # 在900秒(15分钟)之后,如果至少有1个key发生变化,则dump内存快照 save 300 10 # 在300秒(5分钟)之后,如果至少有10个key发生变化,则dunp内存快照 save 60 10000 # 在60秒(1分钟)之后,如果至少有10000个key发生变化,则dump内存快照 # 如果持久化出错,主进程是否停止写入 stop-writes-on-bgsave-error yes # 是否压缩 rdbcompression yes # 导入时是否检查 rdbchecksum yes # 文件名称 dbfilename dump.rdb # 文件保存路径 dir /www/server/redis/
2) RDB持久化工作原理
- Redis调用fork(),产生一个子进程。
- 子进程把数据写到一个临时的RDB文件。
- 当子进程写完新的RDB文件后,把旧的RDB文件替换掉。
3) RDB持久化触发方式
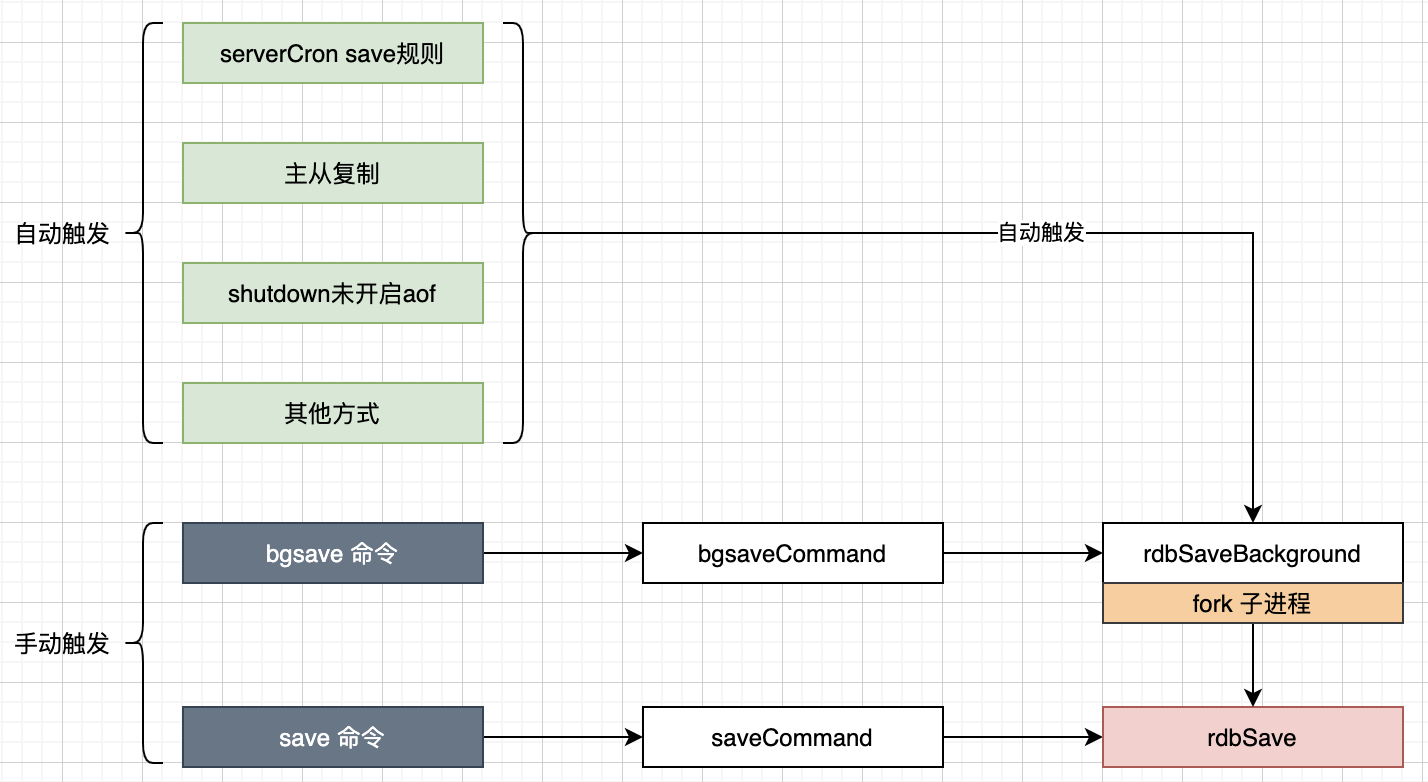
手动触发
save:会阻塞redis的服务器进程,直到RDB文件被创建完毕,线上环境应该禁止使用。
bgsave:该触发方式会fork一个子进程,由子进程负责持久化过程,因此阻塞只会发生在fork子进程的时候。

重启redis服务端和客户端,看数据是否真的持久化了

自动触发
1)根据 save <seconds> <changes> 配置规则自动触发
2)从节点全量复制时,主节点发送rdb文件给从节点完成复制操作,主节点会触发 bgsave
3)执行 debug reload 时
4)执行 shutdown时,如果没有开启aof,也会触发
说明:自动触发对应 bgsave 命令,Redis进程执行fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短。
由于 save 基本不会被使用到,我们重点看看 bgsave 这个命令是如何完成RDB的持久化的。
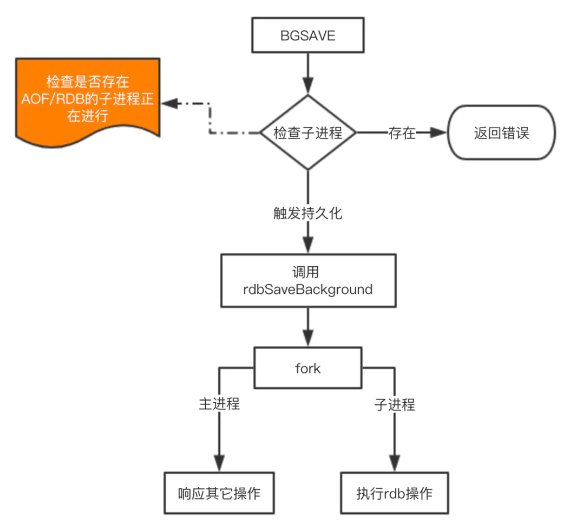
这里需要注意的是 fork 操作会阻塞,导致Redis读写性能下降。我们可以控制单个Redis实例的最大内存,来尽可能降低Redis在fork时的事件消耗。以及上面提到的自动触发的频率减少fork次数,或者使用手动触发,根据自己的机制来完成持久化。
4) RDB持久化优缺点
优点
1)RDB文件是一个很简洁的单文件,它保存了某个时间点的Redis数据,很适合用于做备份。你可以设定一个时间点对RDB文件进行归档,这样就能在需要的时候很轻易的把数据恢复到不同的版本。
2)基于上面所描述的特性,RDB很适合用于灾备。单文件很方便就能传输到远程的服务器上。
3)RDB的性能很好,需要进行持久化时,主进程会fork一个子进程出来,然后把持久化的工作交给子进程,自己不会有相关的I/O操作。
4)比起AOF,在数据量比较大的情况下,RDB的启动速度更快。
缺点
1)RDB容易造成数据的丢失。假设每5分钟保存一次快照,如果Redis因为某些原因不能正常工作,那么从上次产生快照到 Redis 出现问题这段时间的数据就会丢失了。
2)RDB方式无法做到实时或秒级持久化。因为 RDB 使用 fork() 产生子进程进行数据的持久化,而fork操作是一个耗时操作,无法做到实时性。如果数据比较大的话可能就会花费点时间,造成Redis停止服务几毫秒。如果数据量很大且CPU性能不是很好的时候,停止服务的时间甚至会达到1秒。
2、AOF(Append Only File)
快照功能(RDB)并不是非常耐久(durable): 如果 Redis 因为某些原因而造成故障停机, 那么服务器将丢失最近写入、且仍未保存到快照中的那些数据。 从 1.1 版本开始, Redis 增加了一种完全耐久的持久化方式: AOF 持久化。
1)配置文件参数以及说明
开启AOF功能需要配置:appendonly yes,默认不开启。
2)工作原理
AOF持久化会把被执行的写命令写到AOF文件的末尾,记录数据的变化。默认情况下,Redis是没有开启AOF持久化的,开启后,每执行一条更改Redis数据的命令,都会把该命令追加到AOF文件中,这是会降低Redis的性能,但大部分情况下这个影响是能够接受的,另外使用较快的硬盘可以提高AOF的性能
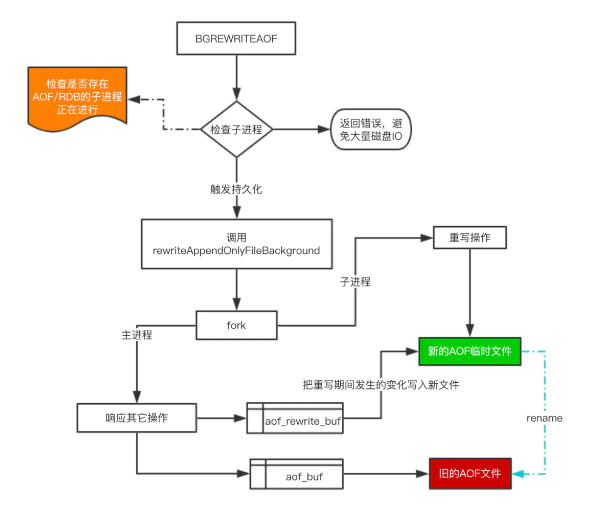
AOF的整个流程大体来看可以分为两步,第一步是命令的实时写入(如果是 appendfsync everysec 配置,会有1s损耗),第二步是对 aof 文件的重写。
aof 重写是为了减少aof文件的大小,使得 AOF文件的体积不会超出保存数据集状态所需的实际大小。可以手动或者自动触发。fork的操作也是发生在重写这一步,也是这里会对主进程产生阻塞。
实际上,AOF持久化并不会立即将命令写入到硬盘文件中,而是写入到硬盘缓存,在接下来的策略中,配置多久来从硬盘缓存写入到硬盘文件。所以在一定程度一定条件下,还是会有数据丢失,不过可以大大减少数据损失。
重写的流程图如下:
AOF持久化提供三种策略:
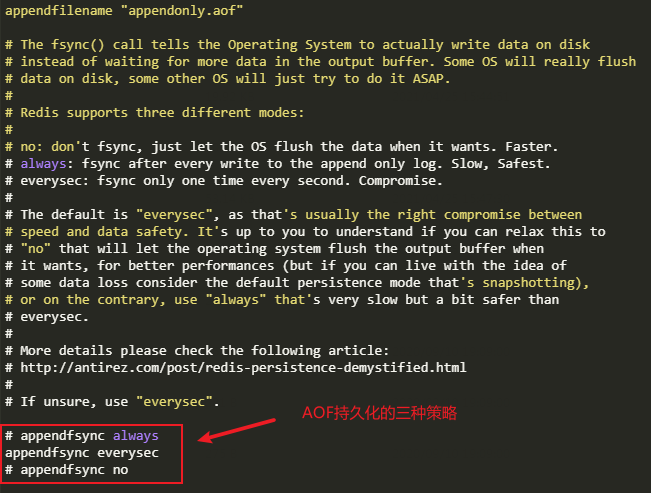
always: 每次操作都会立即写入aof文件中
everysec: 每秒持久化一次(默认配置)
no: 不主动进行同步操作,默认30s一次。写入AOF文件中的操作由操作系统决定,一般而言为了提高效率,操作系统会等待缓存区被填满,才会开始同步数据到磁盘。
3)触发方式
手动触发
bgrewriteaof
自动触发
根据配置规则来触发,当然自动触发的整体时间还跟Redis的定时任务频率有关系。
4)AOF持久化优缺点
优点
1) 比RDB可靠
可以制定不同的fsync策略:不进行fsync、每秒fsync一次和每次查询进行fsync。默认是每秒fsync一次。这意味着最多丢失一秒钟的数据。
2)AOF日志文件是一个纯追加的文件
就算是遇到突然停电的情况,也不会出现日志的定位或者损坏问题。甚至如果因为某些原因(例如磁盘满了)命令只写了一半到日志文件里,我们也可以用redis-check-aof这个工具很简单的进行修复。
3)通过重写来减少aof文件的大小
当AOF文件太大时,Redis会自动在后台进行重写。重写很安全,因为重写是在一个新的文件上进行,同时Redis会继续往旧的文件追加数据。新文件上会写入能重建当前数据集的最小操作命令的集合。当新文件重写完,Redis会把新旧文件进行切换,然后开始把数据写到新文件上。
4)快速恢复数据
AOF把操作命令以简单易懂的格式一条接一条的保存在文件里,很容易导出来用于恢复数据。例如我们不小心用FLUSHALL命令把所有数据刷掉了,只要文件没有被重写,我们可以把服务停掉,把最后那条命令删掉,然后重启服务,这样就能把被刷掉的数据恢复回来。
缺点:
- 在相同的数据集下,AOF文件的大小一般会比RDB文件大。
- 在某些fsync策略下,AOF的速度会比RDB慢。通常fsync设置为每秒一次(everysec)就能获得比较高的性能,而在禁止fsync的情况下速度可以达到RDB的水平。
- 在过去曾经发现一些很罕见的BUG导致使用AOF重建的数据跟原数据不一致的问题。
3、同时开启RDB和AOF
在这种情况下,当redis重启的时候会优先载入 AOF 文件来恢复原始的数据。因为在通常情况下 AOF 文件保存的数据集要比 RDB 文件保存的数据集要完整。
4、不使用持久化
数据的生命周期只存在于服务器的运行时间里
参考链接:
https://segmentfault.com/a/1190000002906345
http://redisdoc.com/topic/persistence.html
https://www.cnblogs.com/xuwenjin/p/9876432.html
https://juejin.cn/post/6844903655527677960