梯度和自动微分
官网
1. Gradient tapes
tf.GradientTape API可以进行自动微分,根据某个函数的输入变量来计算它的导数。它会将上下文的变量操作都记录在tape上,然后用反向微分法来计算这个函数的导数。
(y=x^2)的标量例子
x = tf.Variable(3.0)
with tf.GradientTape() as tape:
y = x**2
# dy = 2x * dx
dy_dx = tape.gradient(y, x)
dy_dx.numpy()
# ==>6.0
使用tensor的例子,tape.gradient方法会根据入参返回对应的类型
# w(3,2)
w = tf.Variable(tf.random.normal((3, 2)), name='w')
# b(2,)
b = tf.Variable(tf.zeros(2, dtype=tf.float32), name='b')
# x(1,3)
x = [[1., 2., 3.]]
with tf.GradientTape(persistent=True) as tape:
y = x @ w + b
loss = tf.reduce_mean(y**2)
# 使用数组传入参数
[dl_dw, dl_db] = tape.gradient(loss, [w, b])
# 使用字典传入参数
my_vars = {
'w': w,
'b': b
}
grad = tape.gradient(loss, my_vars)
grad['b']
2. 计算模型中的所有梯度
通常变量会被聚合到tf.Module或它的子类(layers.Layer、keras.Model)中,所以可以用以下方法进行梯度计算
layer = tf.keras.layers.Dense(2, activation='relu')
x = tf.constant([[1., 2., 3.]])
with tf.GradientTape() as tape:
# Forward pass
y = layer(x)
# 定义损失函数
loss = tf.reduce_mean(y**2)
# 计算模型中所有可训练变量的梯度
grad = tape.gradient(loss, layer.trainable_variables)
3. 控制Tape记录的内容
GradientTape默认只会记录对Variable的操作,主要原因是:
- Tape需要记录前向传播的所有计算过程,之后才能计算后向传播
- Tape会记录所有的中间结果,不需要记录没用的操作
- 计算模型中的可训练参数就是GradientTape的最通用用法
下面的demo展示了一些没被记录的情况
# A trainable variable
x0 = tf.Variable(3.0, name='x0')
# Not trainable
x1 = tf.Variable(3.0, name='x1', trainable=False)
# Not a Variable: A variable + tensor returns a tensor.
x2 = tf.Variable(2.0, name='x2') + 1.0
# Not a variable
x3 = tf.constant(3.0, name='x3')
with tf.GradientTape() as tape:
y = (x0**2) + (x1**2) + (x2**2)
grad = tape.gradient(y, [x0, x1, x2, x3])
for g in grad:
print(g)
==>
tf.Tensor(6.0, shape=(), dtype=float32)
None
None
None
使用方法GradientTape.watched_variables,可以查看被记录的变量。而GradientTape.watch方法可以手动加入需要记录的参数
[var.name for var in tape.watched_variables()]
# 手动指定记录tensor
x = tf.constant(3.0)
with tf.GradientTape() as tape:
tape.watch(x)
y = x**2
# dy = 2x * dx
dy_dx = tape.gradient(y, x)
print(dy_dx.numpy())
通过设置参数watch_accessed_variables=False可以关闭默认的记录规则
x0 = tf.Variable(0.0)
x1 = tf.Variable(10.0)
with tf.GradientTape(watch_accessed_variables=False) as tape:
tape.watch(x1)
y0 = tf.math.sin(x0)
y1 = tf.nn.softplus(x1)
y = y0 + y1
ys = tf.reduce_sum(y)
4. 中间结果
可以使用gradient(计算的中间变量,需要求偏导的变量)来获取中间结果。
默认情况下,GradientTape中的所有参数记录会在调用gradient()方法时全部释放,可以使用参数persistent=True让gradient()方法可以多次返回结果,但是需要使用del tape来手动释放资源!
x = tf.constant([1, 3.0])
with tf.GradientTape(persistent=True) as tape:
tape.watch(x)
y = x * x
z = y * y
# 中间结果
# z对x求导
print(tape.gradient(z, x).numpy()) # 108.0 (4 * x**3 at x = 3)
# y对x求导
print(tape.gradient(y, x).numpy()) # 6.0 (2 * x)
# dz_dx = 2 * y, where y = x ** 2
print(tape.gradient(z, y).numpy()) # 18 (x = 3)
del tape # Drop the reference to the tape
5. 注意事项
- 使用Tape记录变量的开销一般很小,使用Eager Execution的情况这个开销几乎可以忽略。但是使用时还是应该把作用域控制在小的范围内
- Tape使用内存记录了输入、输出和中间结果
- 一些没必要记录的中间结果会在前向传播的时候被丢弃,如ReLU的结果。但是如果使用了persistent=True,所有记录都不会被丢弃,并会占用大量内存
6.求导目标不是标量(Gradient of non-scalar targets)
梯度的本质就是对目标求导,但是如果传入了多个目标,那么结果将是:
- 多个目标函数的梯度进行求和
- 多个参数在目标函数梯度进行求和
多个目标函数的情况,结果是 y0对x求导 + y1对x求导
x = tf.Variable(2.0)
with tf.GradientTape() as tape:
y0 = x**2
y1 = 1 / x
print(tape.gradient({'y0': y0, 'y1': y1}, x).numpy())
==>
3.75
多个参数的情况,结果是 y对x求导,x=3和x=4的结果求和
x = tf.Variable(2.)
with tf.GradientTape() as tape:
y = x * [3., 4.]
print(tape.gradient(y, x).numpy())
==>
7
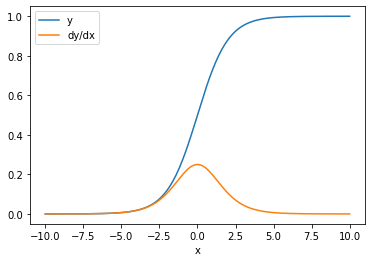
使用Jacobians可以获得每一项的梯度,会在后续总结中介绍。而对于 element-wise calculation(指sigmoid函数本来就可以支持多个参数的计算??)计算出的梯度本来就是独立的。
x = tf.linspace(-10.0, 10.0, 200+1)
with tf.GradientTape() as tape:
tape.watch(x)
y = tf.nn.sigmoid(x)
dy_dx = tape.gradient(y, x)
plt.plot(x, y, label='y')
plt.plot(x, dy_dx, label='dy/dx')
plt.legend()
_ = plt.xlabel('x')
7. 分支控制
由于Tape需要记录变量的操作,所以也就必须能处理逻辑分支(if和while等),Tape只会记录执行过的操作。
x = tf.constant(1.0)
v0 = tf.Variable(2.0)
v1 = tf.Variable(2.0)
with tf.GradientTape(persistent=True) as tape:
tape.watch(x)
if x > 0.0:
result = v0
else:
result = v1**2
dv0, dv1 = tape.gradient(result, [v0, v1])
print(dv0)
print(dv1)
===>
tf.Tensor(1.0, shape=(), dtype=float32)
None
8. None梯度的原因
如果求导目标和函数没有关系,会返回None梯度。
x = tf.Variable(2.)
y = tf.Variable(3.)
with tf.GradientTape() as tape:
z = y * y
print(tape.gradient(z, x))
8.1 Variable被替换成Tensor
一个常见的错误就是把变量替换成了张量,张量默认又不会被记录到Tape中,所以导致结果为None。原因是因为没有使用assign相关方法对变量进行修改
x = tf.Variable(2.0)
for epoch in range(2):
with tf.GradientTape() as tape:
y = x+1
print(type(x).__name__, ":", tape.gradient(y, x))
# 循环的第一次会将x替换成tensor,第二次循环梯度就计算不出来了
x = x + 1 # This should be `x.assign_add(1)`
===>
ResourceVariable : tf.Tensor(1.0, shape=(), dtype=float32)
EagerTensor : None
8.2 使用Tensorflow之外的方法进行计算
下图中因为使用np.mean来进行计算,因此x2和y并没有关联上,x也就和y没有关联上,所以结果是None
x = tf.Variable([[1.0, 2.0],
[3.0, 4.0]], dtype=tf.float32)
with tf.GradientTape() as tape:
x2 = x**2
# This step is calculated with NumPy
y = np.mean(x2, axis=0)
# Like most ops, reduce_mean will cast the NumPy array to a constant tensor
# using `tf.convert_to_tensor`.
y = tf.reduce_mean(y, axis=0)
print(tape.gradient(y, x))
===>
None
8.3 使用整型或字符串
Integer和strings是不可微的,所以求导结果是None
# 由于没写小数点,创建的常量是整型
x = tf.constant(10)
with tf.GradientTape() as g:
g.watch(x)
y = x * x
print(g.gradient(y, x))
8.4 使用有状态的对象
当使用参数的时候,Tape只会关心其当前状态,而不会关心它是怎么被赋予现在值的。
x0 = tf.Variable(3.0)
x1 = tf.Variable(0.0)
with tf.GradientTape() as tape:
# Update x1 = x1 + x0.
x1.assign_add(x0)
# The tape starts recording from x1.
y = x1**2 # y = (x1 + x0)**2
# This doesn't work.
print(tape.gradient(y, x0)) #dy/dx0 = 2*(x1 + x0)
上面的逻辑能看出 x1虽然被赋值后看似与x0关联了起来,实际上Tape只记录了y和x1的关系,它不关心x1内部属性的变化。
9. 没有梯度的注册
一些tf.Operation被注册为不可微的,会返回None;剩余的就是没有被注册的。
tf.raw_ops里展示了哪些方法是被注册为可微的,如果在Tape中使用一个没有被注册的方法,调用gradient()时会报错。
比如tf.image.adjust_contrast这个方法可以计算梯度,但是目前没有现实
image = tf.Variable([[[0.5, 0.0, 0.0]]])
delta = tf.Variable(0.1)
with tf.GradientTape() as tape:
new_image = tf.image.adjust_contrast(image, delta)
try:
print(tape.gradient(new_image, [image, delta]))
assert False # This should not happen.
except LookupError as e:
print(f'{type(e).__name__}: {e}')
===>
LookupError: gradient registry has no entry for: AdjustContrastv2
10. 替换None梯度
当变量没有被连接到函数时,如果你不希望Tape返回None,可以使用unconnected_gradients参数来指定返回值。
x = tf.Variable([2., 2.])
y = tf.Variable(3.)
with tf.GradientTape() as tape:
z = y**2
print(tape.gradient(z, x, unconnected_gradients=tf.UnconnectedGradients.ZERO))