K-近邻算法概述:
K-近邻算法就是采用测量不同特征值之间的距离方法来进行分类
优点:精度高,对异常值不敏感,无数据输入假设。
缺点:计算复杂度高、空间复杂度高。
适用于数值型和标称型数据。
对未知类别属性的数据集中的每个点依次执行以下操作:
(1)计算已知类别数据集中的点与当前点之间的距离。
(2)按照距离递增次序排序。
(3)选取与当前点距离最小的 k 个点。
(4)确定前 k 个点坐在类别的出现频率。
(5)返回前 k 个点出现频率最高的类别作为当前点的预测分类。
以欧式距离为例:
预备知识:
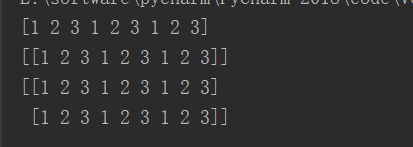
1、numpy 中的 tile() 函数
a = [1,2,3] b = np.tile(a,3) c = np.tile(a,(1,3)) d = np.tile(a,(2,3))
运行结果为:
2、python字典当中的 get() 函数
dict.get(key,default=None)
查找key,如果不存在,则返回默认值None
3、python中的 axis 函数
numpy当中axis的值表示的是这个多维数组维度的下标,比如有一个二维数组a,a的shape是(5,6),也就是说a有5行6列,axis=0表示的就是[5,6]中的第一维,
也就是行,axis=1表示的是[5,6]中的第二个维度,也就是列。
K-近邻算法代码如下:
import numpy as np import operator from sklearn.datasets import load_iris # 创建数据集 def createDataSet(): group = np.array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]]) labels = ['A','A','B','B'] return group,labels # shape[a] 当a=0时返回的是数组的行数,当a=1时返回的时数组的列数 def classify(inx,dataset,lables,k): # 计算距离 datasetsize = dataset.shape[0] diffmat = np.tile(inx,(datasetsize,1))-dataset sqdiffmat = diffmat**2 sqdistance = sqdiffmat.sum(axis=1) distance = sqdistance**0.5 # 选择距离最小的k个点 sortdistindicies = distance.argsort() classcount={} for i in range(k): votelable = lables[sortdistindicies[i]] classcount[votelable] = classcount.get(votelable,0)+1 '''dict.get(key,default=None) 查找key,如果不存在,则返回默认值None''' # 排序 sortedclasscount = sorted(classcount.items(),key=operator.itemgetter(1),reverse=True) return sortedclasscount
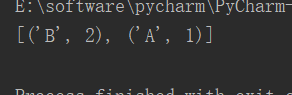
a = classify([0,0,0,0],group,lables,3)
print(a)
结果如下:
代码内各个参数结果如下:
datasetsize = 4
diffmat = [[-1.0,-1.1],[-1.0,-1.0],[0,0],[0,0.01]]
sqdiffmat = [[1,1.21],[1,1],[0,0],[0,0.01]]
distance = [2.21,2,0,0.01]
sortdistindicies = [2,3,1,0]
classcount = {'B':2,'A':1}
sortedclasscount = [('B',2),('A',1)]