python操作Redis缓存
https://www.cnblogs.com/guotianbao/p/8683037.html
学习资料: 电子书资源
联系邮箱:gmu1592618@gmail.com
flask微电影: movie_project
正文
一、Redis的安装
xshell连上服务器,依次输入以下代码:
|
1
2
3
4
|
wget http://download.redis.io/releases/redis-3.0.6.tar.gztar xzf redis-3.0.6.tar.gzcd redis-3.0.6make |

如果不巧发生以下截图中的错误:

说明未安装gcc,如果是centos系统,输入:yum install gcc安装gcc即可,然后再次输入make执行。
输入make后,很不幸,再次发生如下截图错误:

推测是因为编译库的问题。
将make改为make MALLOC=libc 再次运行!好事多磨。

终于安装成功了!
还有配置文件的修改什么的先不折腾了,此时已然可以启动Redis服务
|
1
2
3
4
5
6
7
8
|
src/redis-server # 启动服务端# 启动客户端的代码如下src/redis-cliredis> set foo barOKredis> get foo"bar" |
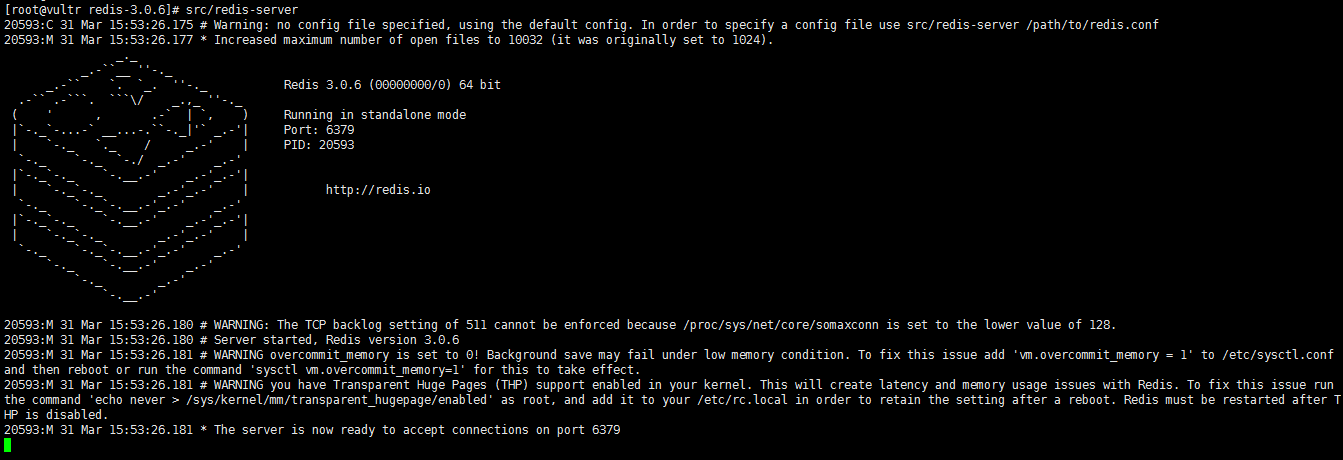
看到上面的图像,说明服务端已经起来了!
但是看到很多WARNING,没错,此时你用pycharm写了连接redis服务端的代码,但是你发现服务端竟然没有响应
OK,在服务端Ctrl + C ,先把服务断开
分别执行下面的语句:
|
1
2
3
4
|
echo 511 > /proc/sys/net/core/somaxconnecho "vm.overcommit_memory = 1" >> /etc/sysctl.confsysctl vm.overcommit_memory=1echo never > /sys/kernel/mm/transparent_hugepage/enabled |
在/etc下的rc.local的最后添加:
|
1
|
echo never > /sys/kernel/mm/transparent_hugepage/enabled |
最后的重点来了,折腾半天还是服务器不鸟我,无奈之下试了试临时关闭防火墙:
|
1
|
service iptables stop |
唉呀呀,终于成功了!
我在另一台服务器用了另一种搭建方法:传送门也成功了,但是也不要忘记要临时关掉防火墙。
二、Redis的两种连接方式
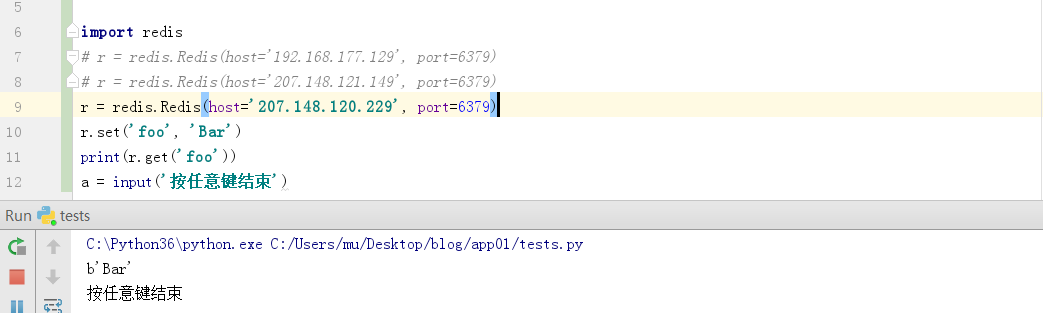
1.简单连接
|
1
2
3
4
5
|
import redisconn = redis.Redis(host='207.148.120.229', port=6379)conn.set('foo', 'Bar')print(conn.get('foo'))a = input('按任意键结束') |
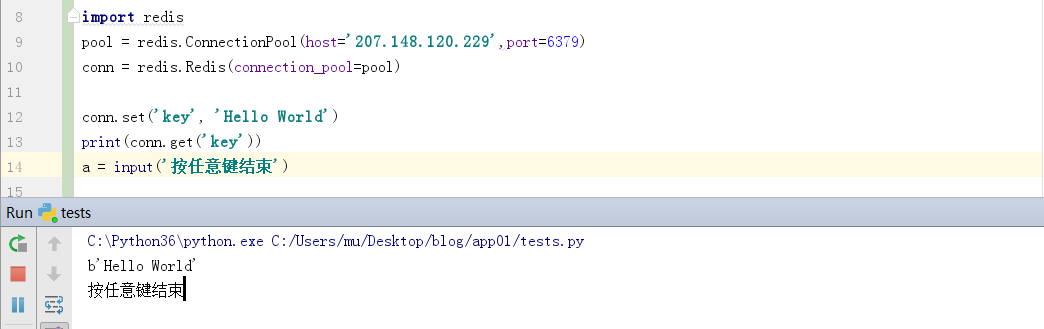
2.使用连接池
为了减少每次建立、释放连接的开销,推荐使用连接池
redis使用connection pool来管理对一个redis服务的所有连接。
多个redis实例可共享一个连接池。
|
1
2
3
4
5
6
7
|
import redispool = redis.ConnectionPool(host='207.148.120.229',port=6379)conn = redis.Redis(connection_pool=pool)conn.set('key', 'Hello World')print(conn.get('key'))a = input('按任意键结束') |
三、五大数据类型
1.String操作
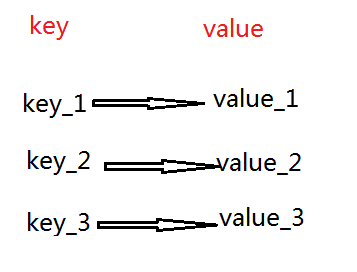
redis中的String在在内存中按照一个key对应一个value来存储。以键值对的方式存储。
set(name, value, ex=None, px=None, nx=False, xx=False)
mset(*args, **kwargs) 批量设置值
 View Code
View Codeget(name) 获取值
print(conn.get('k1'))
mget(keys, *args) 批量获取值
View Codegetset(name, value) 设置新值并获取原来的值
View Codegetrange(key, start, end) 获取name对应value的指定字节
View Codesetrange(name, offset, value) 从指定字节开始替换新值
View Codestrlen(name) 获取name对应的value的长度
View Codeincr(self, name, amount=1) name存在,则自增amount,否则设置name的value值为amount
View Codedecr(self, name, amount=1) 自减(整数)
View Codeappend(key, value)
View Code2.Hash操作
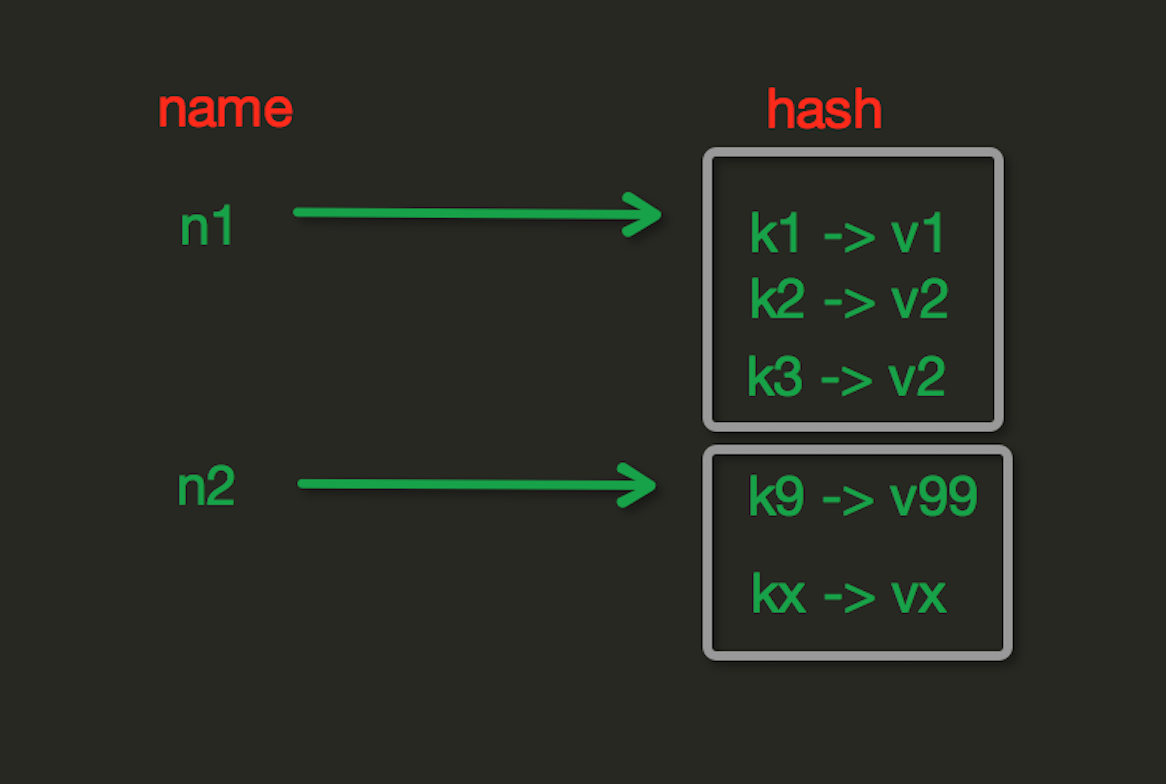
hset(name, key, value) 设置值
View Code hmset(name, mapping) 批量设置值
View Codehmget(name, keys, *args) 获取多个值
View Codehgetall(name) 获取name对应hash的所有键值
View Codehlen(name) 获取name对应的hash中键值对的个数
hkeys(name) 获取name对应的hash中所有的key的值
hvals(name) 获取name对应的hash中所有的value的值
hdel(name,*keys) 将name对应的hash中指定key的键值对删除
hincrby(name, key, amount=1) 自增(整数)
View Codehincrbyfloat(name, key, amount=1.0) 自增(浮点数)
hscan(name, cursor=0, match=None, count=None) 增量式迭代获取
View Codehscan_iter(name, match=None, count=None)
View Code3.List操作
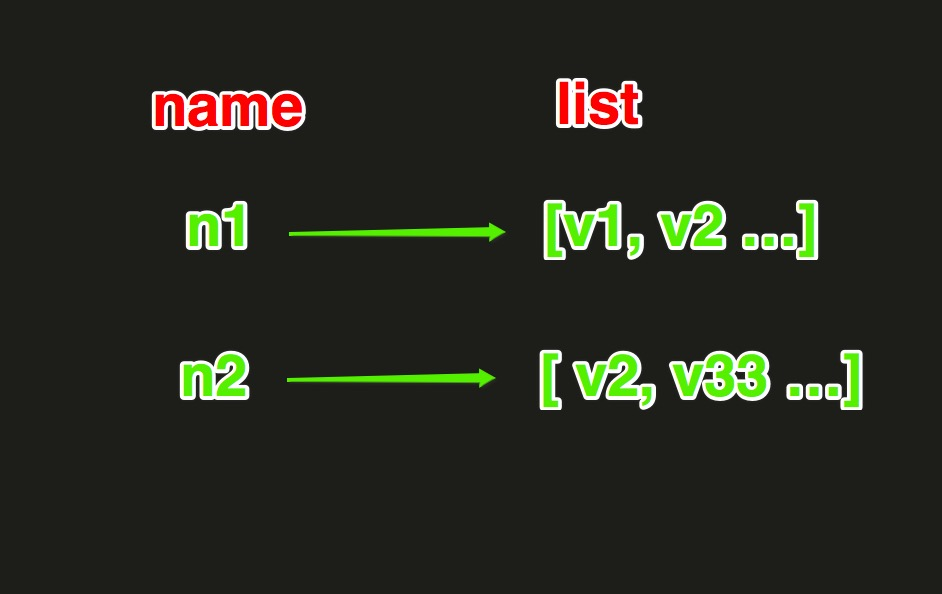
lpush(name,values)
View Codelpushx(name,value)
View Code llen(name) name对应的list元素的个数
linsert(name, where, refvalue, value))
View Code r.lset(name, index, value)
View Code r.lrem(name, value, num)
View Code lpop(name)
View Codelindex(name, index) 在name对应的列表中根据索引获取列表元素
lrange(name, start, end)
View Code ltrim(name, start, end)
View Code rpoplpush(src, dst)
View Code blpop(keys, timeout)


# 将多个列表排列,按照从左到右去pop对应列表的元素
# 参数:
# keys,redis的name的集合
# timeout,超时时间,当元素所有列表的元素获取完之后,阻塞等待列表内有数据的时间(秒), 0 表示永远阻塞
# 更多:
# r.brpop(keys, timeout),从右向左获取数据
brpoplpush(src, dst, timeout=0)
View Code自定义增量迭代
View Code4.Set操作
Set集合就是不允许重复的列表
sadd(name,values) name对应的集合中添加元素
scard(name) 获取name对应的集合中元素个数
sdiff(keys, *args) 在第一个name对应的集合中且不在其他name对应的集合的元素集合
sdiffstore(dest, keys, *args) 获取第一个name对应的集合中且不在其他name对应的集合,再将其新加入到dest对应的集合中
sinter(keys, *args) 获取多一个name对应集合的并集
sinterstore(dest, keys, *args) 获取多一个name对应集合的并集,再讲其加入到dest对应的集合中
sismember(name, value) 检查value是否是name对应的集合的成员
smembers(name) 获取name对应的集合的所有成员
smove(src, dst, value) 将某个成员从一个集合中移动到另外一个集合
spop(name) 从集合的右侧(尾部)移除一个成员,并将其返回
srandmember(name, numbers) 从name对应的集合中随机获取 numbers 个元素
srem(name, values) 在name对应的集合中删除某些值
sunion(keys, *args) 获取多一个name对应的集合的并集
sunionstore(dest,keys, *args) 获取多一个name对应的集合的并集,并将结果保存到dest对应的集合中
sscan_iter(name, match=None, count=None) 同字符串的操作,用于增量迭代分批获取元素,避免内存消耗太大
5.有序集合
在集合的基础上,为每元素排序;元素的排序需要根据另外一个值来进行比较,所以,对于有序集合,每一个元素有两个值,即:值和分数,分数专门用来做排序。
zadd(name, *args, **kwargs) 在name对应的有序集合中添加元素
View Codezcard(name) 获取name对应的有序集合元素的数量
zcount(name, min, max) 获取name对应的有序集合中分数 在 [min,max] 之间的个数
zincrby(name, value, amount) 自增name对应的有序集合的 name 对应的分数
View Coder.zrange( name, start, end, desc=False, withscores=False, score_cast_func=float)
View Codezrank(name, value)
View Codezrangebylex(name, min, max, start=None, num=None)
View Codezrem(name, values)
View Codezremrangebyrank(name, min, max) 根据排行范围删除
zremrangebyscore(name, min, max) 根据分数范围删除
zremrangebylex(name, min, max) 根据值返回删除
zscore(name, value) 获取name对应有序集合中 value 对应的分数
zinterstore(dest, keys, aggregate=None)
View Codezunionstore(dest, keys, aggregate=None)
View Codezscan_iter(name, match=None, count=None,score_cast_func=float) 同字符串相似,相较于字符串新增score_cast_func,用来对分数进行操作
6.其他常用操作
delete(*names) 根据name删除redis中的任意数据类型
exists(name) 检测redis的name是否存在
keys(pattern='*')
View Codeexpire(name ,time) 为某个redis的某个name设置超时时间
rename(src, dst) 对redis的name重命名
move(name, db) 将redis的某个值移动到指定的db下
randomkey() 随机获取一个redis的name(不删除)
type(name) 获取name对应值的类型
scan(cursor=0, match=None, count=None)
scan_iter(match=None, count=None) 同字符串操作,用于增量迭代获取key
四、管道
redis-py默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作,如果想要在一次请求中指定多个命令,则可以使用pipline实现一次请求指定多个命令,并且默认情况下一次pipline 是原子性操作。
View Code五、发布和订阅

发布者:服务器
订阅者:Dashboad和数据处理
Demo如下:
RedisHelper订阅者:
View Code发布者:
View Code