首先需要准备好数据集,这里有labelme标签数据转coco数据集标签的说明:labelme转coco数据集 - 一届书生 - 博客园 (cnblogs.com)
1. 准备工作目录
我们的工作目录,也就是mmdetection目录,如下所示:
|-- configs
| |-- _base_
| |--- .......
|-- data
| |--- coco
| | |--- annotations
| | |--- train2017
| | |--- val2017
| | |--- visualization
|-- mmdet
| |--- core
| |--- datasets
| |--- .......
|-- tools
-
configs就是我们的配置文件,里边包含所有的文件。
-
data就是我们的数据集文件,文件目录如上。
-
mmdet是我们所需要修改的目录。
-
tools是我们的mmdetection提供的工具箱,里边包含我们要用的训练和测试文件。
2. 修改mmdetection模型的配置
1️⃣ 如果自己的GPU显存不够用,修改下面文件里的img_scale=(1333, 800),改成小一点的数值。三个文件都要改。
configs/_base_/datasets/coco_detection.py
configs/_base_/datasets/coco_instance.py
configs/_base_/datasets/coco_instance_semantic.py
2️⃣ 选择你要训练的模型对应的配置文件修改,假如我要训练的模型是mask_rcnn_r101_fpn_2x_coco.py,我打开configs/mask_rcnn/mask_rcnn_r101_fpn_2x_coco.py,内容如下:
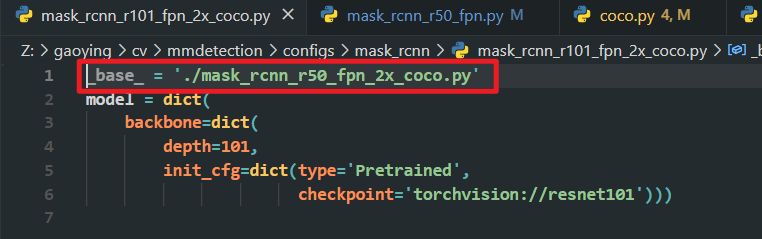
然后我们找到这个目录下的文件,修改文件里的 num_classes=80 ,修改成自己的类别数目。
configs/_base_/models/mask_rcnn_r50_fpn.py
3️⃣ 修改我们的类别名,两个文件需要修改,第一个文件是:
mmdet/core/evaluation/class_names.py
修改里边的def coco_classes(): ,将return内容修改成自己的类别。
第二个文件:
mmdet/datasets/coco.py
修改里边的class CocoDataset(CustomDataset): ,将 CLASSES = () 修改成自己的类别。
至此,修改结束,我们还需要重新编译一遍,这样才能生效,在我们的mmdetection目录下运行:
python setup.py install
3. 开始训练
1️⃣ 单GPU训练
python tools/train.py configs/mask_rcnn/mask_rcnn_r101_fpn_2x_coco.py
- configs/mask_rcnn/mask_rcnn_r101_fpn_2x_coco.py 就是我们要训练的模型
2️⃣ 多GPU训练
bash ./tools/dist_train.sh configs/mask_rcnn/mask_rcnn_r101_fpn_2x_coco.py 2
- configs/mask_rcnn/mask_rcnn_r101_fpn_2x_coco.py 就是我们要训练的模型
- 2 是我们的GPU数目
3️⃣ 我们可以刚开始训练便停止,对训练的一些配置进行修改。它会在你的mmdetection目录下自动生成一个work_dirs文件夹,里边包含你模型的配置文件,打开里边的.py文件,例如我的:
mmdetection/work_dirs/mask_rcnn_r101_fpn_2x_coco/mask_rcnn_r101_fpn_2x_coco.py
一般我们进行修改的就是下面这些,官方给的配置文件中所有参数的解释说明:mmdetection-readthedocs-io-zh_CN-latest.pdf
runner = dict(type='EpochBasedRunner', max_epochs=24)
# 最大的epochs,根据自己的情况来调整。
checkpoint_config = dict(interval=1)
# 模型权重的保存的间隔,建议调大一点,否则会保存大量模型权重,占用存储空间,例如interval=8。模型会默认保存最后一次训练的权重
log_config = dict(interval=50, hooks=[dict(type='TextLoggerHook')])
# 日志的输出间隔,建议调小一点,例如interval=4
需要注意的是,修改完配置文件,再训练的时候,训练语句指定的配置文件就是你刚刚修改的了,也就是work_dirs目录下面的。
修改完配置文件后,单 GPU训练
python tools/train.py work_dirs/mask_rcnn_r101_fpn_2x_coco/mask_rcnn_r101_fpn_2x_coco.py
修改完配置文件后,多GPU训练
bash ./tools/dist_train.sh work_dirs/mask_rcnn_r101_fpn_2x_coco/mask_rcnn_r101_fpn_2x_coco.py 2
4. 模型测试
python tools/test.py work_dirs/mask_rcnn_r101_fpn_2x_coco/mask_rcnn_r101_fpn_2x_coco.py work_dirs/mask_rcnn_r101_fpn_2x_coco/latest.pth --show-dir work_dirs/mask_rcnn_r101_fpn_2x_coco/test_show
我是一共有十张图片,7张图片用于训练,3张图片用于测试。有个缺点我没解决,就是螺母的中间,应该为背景,我在用labelme标注过程中都已经标注为_background_,训练的时候,我是用的num_classes=2,我再测试测试。
我自己标注的数据集链接放在这:「螺丝螺母标注数据集全文件」
可视化结果展示:
 24epochs 24epochs |
 480epochs 480epochs |
同时我们的 work_dirs/mask_rcnn_r101_fpn_2x_coco/ 目录下还会有个json文件,可以可视化我们的一些评价指标的变化情况。
python tools/analysis_tools/analyze_logs.py plot_curve work_dirs/mask_rcnn_r101_fpn_2x_coco/20211015_112915.log.json --keys bbox_mAP segm_mAP
显示结果如下图:
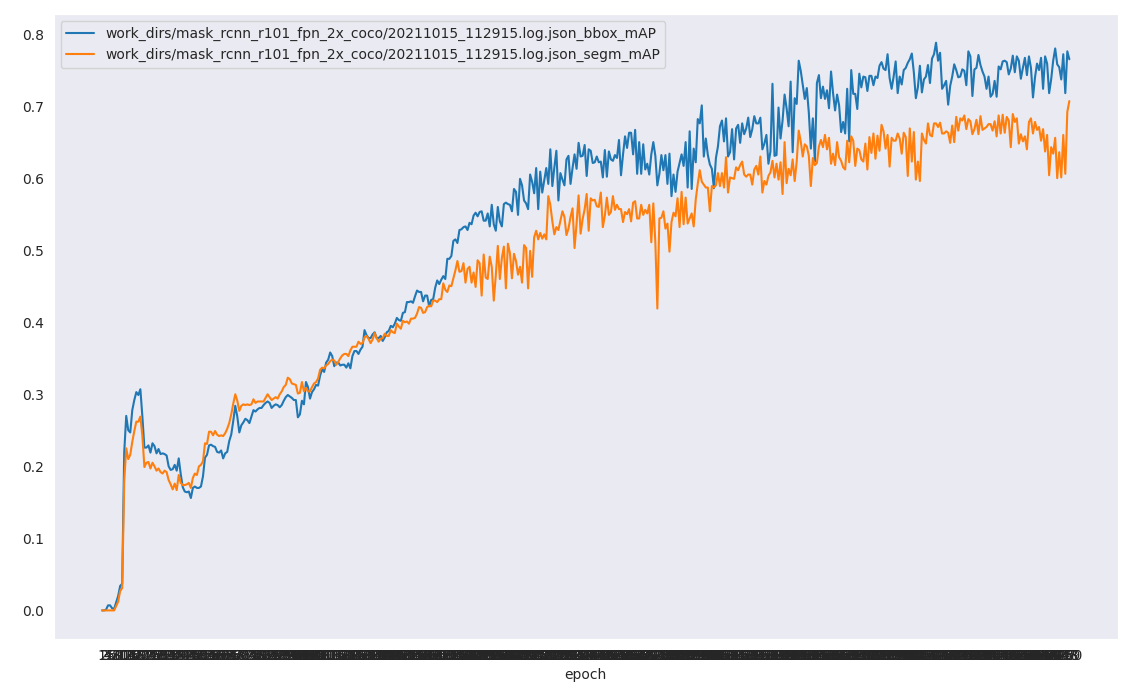
⭐ 文章到此结束了,还有一些小bug,例如上边提到的螺母中间的标注问题,以及最终的评价指标的横坐标epoch显示过于紧密。后续改后对文章继续修改。