前言
管道:可以互相通信、数据共享,但容易出现数据抢占问题,可以加锁解决。
进程池:每开启进程,开启属于这个进程的内存空间;能提升计算机的效率,进程过多 操作系统的调度;
一、初识管道
1、初识管道,可以互相通信。
# 1、初识管道,可以互相通信。 from multiprocessing import Pipe conn1, conn2 = Pipe() conn1.send('123') print(conn2.recv()) conn2.send('321') print(conn1.recv())
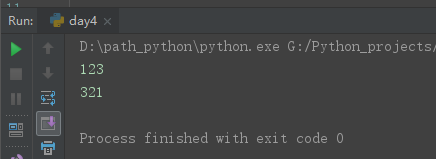
2、管道实现:生产者/消费者模型。
但是这里可能会有个问题,消费者可能同时拿同一个数据,那怎样才好呢?(接收的时候上锁:lock)
所以管道 + 锁来控制操作管道的行为 来避免进程之间争抢数据造成的数据不安全现象。
# 2、管道实现:生产者/消费者模型 from multiprocessing import Pipe,Process import time,random def consumer(con,pro,name): pro.close() while 1: try: m=con.recv() print('%s使用了 %s' % (name,m)) time.sleep(random.random()) except EOFError: con.close() break def producer(con,pro,name,mask): con.close() for i in range(1,6): time.sleep(random.random()) m='%s生产了%s %s'%(name,mask,i) print(m) pro.send(m) pro.close() if __name__ == '__main__': con,pro=Pipe() p=Process(target=producer,args=(con,pro,'大厂','N95 ')) p.start() c=Process(target=consumer,args=(con,pro,'A企业')) c.start() c1=Process(target=consumer,args=(con,pro,'B企业')) c1.start() con.close() pro.close()

3、Manager,数据共享,但不安全的,进程之间也会抢占资源。
但可以加锁进行约束解决。
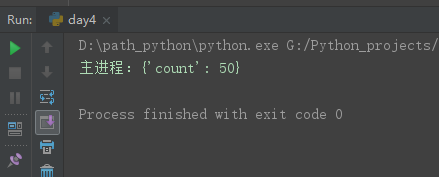
# 3、Manager,数据共享不安全的,但会进程之间抢占资源。 # 但可以加锁约束解决 from multiprocessing import Manager,Process,Lock def func(dic,lock): # lock.acquire() dic['count']+=1 # lock.release() if __name__ == '__main__': lock=Lock() m=Manager() dic=m.dict({'count':0}) p_lst=[] for i in range(50): p=Process(target=func,args=(dic,lock)) p.start() p_lst.append(p) for i in p_lst:i.join() print('主进程:%s'%dic)
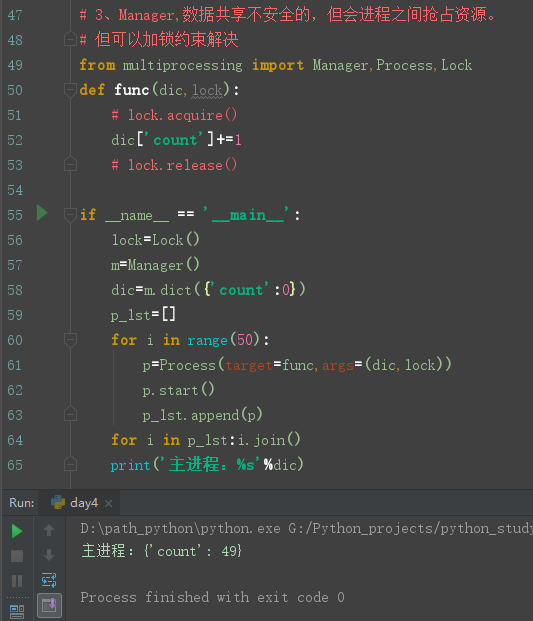
加锁后:数值一直是准确的。
二、进程池
- python中的进程池,是先创建一个属于进程的池子;
- 进程池能指定能存放n个进程执行;
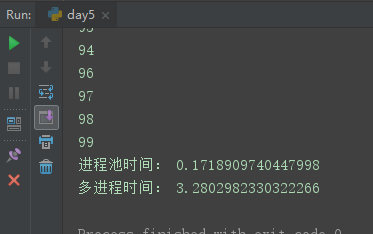
1、进程池与多进程效率对比:
同样是执行100个进程,进程池每次处理5个,而多进程for循环处理。结果进程池效率胜过多进程。
from multiprocessing import Pool,Process import time def func(i): print(i) if __name__ == '__main__': # 进程池的效果 st=time.time() pool=Pool(5) # 池子可放5个(一般CPU的个数+1) pool.map(func,range(100)) # 100个进程任务 t1=time.time()-st st=time.time() print('进程池时间:',t1) # 原来多进程的效果 p_lst=[] for i in range(100): p=Process(target=func,args=(i,)) p_lst.append(p) p.start() for p in p_lst:p.join() t2=time.time()-st print('多进程时间:',t2)
2、进程池传多个参数:
# 2、进程池传多个参数: from multiprocessing import Pool import time def func(i): print(i) if __name__ == '__main__': st=time.time() pool=Pool(5) pool.map(func,[(10,'name','age'),100])

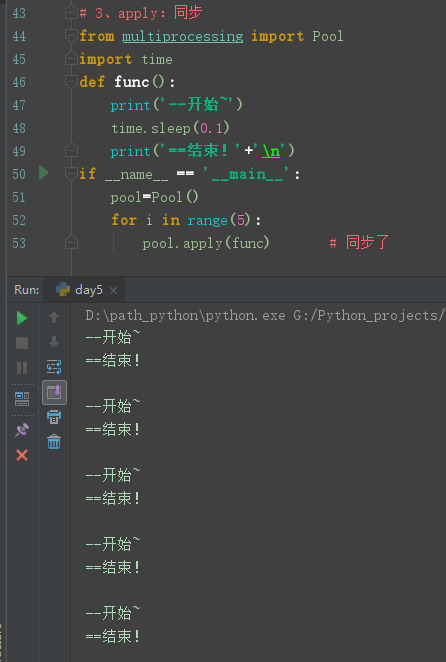
3、apply:同步
# 3、apply:同步 from multiprocessing import Pool import time def func(): print('--开始~') time.sleep(0.1) print('==结束!'+' ') if __name__ == '__main__': pool=Pool() for i in range(5): pool.apply(func) # 同步了
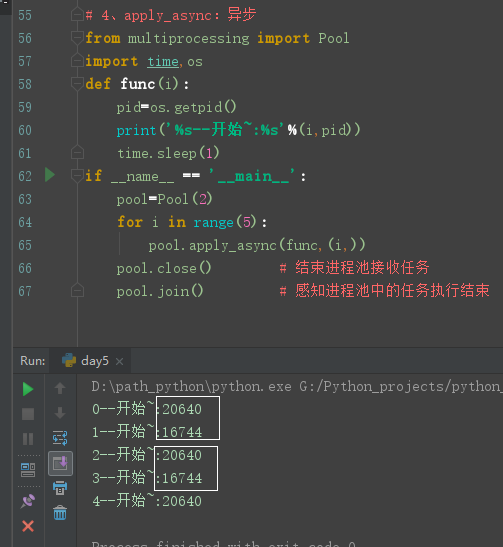
4、apply_async:异步
配合close()、join()进行使用。有没有发现进程池中的pid有重复的?那是因为进程池有固定的N个进程,所以不会变。
# 4、apply_async:异步 from multiprocessing import Pool import time,os def func(i): pid=os.getpid() print('%s--开始~:%s'%(i,pid)) time.sleep(1) if __name__ == '__main__': pool=Pool(2) for i in range(5): pool.apply_async(func,(i,)) pool.close() # 结束进程池接收任务 pool.join() # 感知进程池中的任务执行结束
5、进程池的返回值:
- apply:直接接收返回值
- apply_async:需要get(),会堵塞因等待返回值,解决可先放列表get()
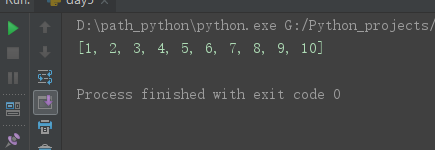
- map:一次性返回所有返回值,自带的
# 5、进程池的返回值 # apply:直接接收返回值 # apply_async:需要get(),会堵塞因等待返回值,解决可先放列表get()。 from multiprocessing import Pool import time def func(i): time.sleep(0.5) return i+1 if __name__ == '__main__': p=Pool(3) p_lst=[] # for i in range(10): # res=p.apply(func,args=(i,)) # 直接接收返回值 # print(res) # res=p.apply_async(func,args=(i,)) # apply_async # p_lst.append(res) # for i in p_lst:print(i.get()) res=p.map(func,range(10)) # map一次性返回 print(res)
①apply同步返回值:

②apply_async返回值:
因3个线程,所以每次打印3个信息。
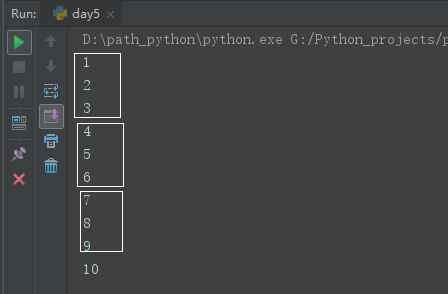
③map返回值:
6、进程池回调函数:
- 先执行异步函数func,将func返回值传入func1函数中的ii参数。
- 回调函数是在主进程中执行,而不是子进程中。
# 6、进程池回调函数 # 先执行异步函数func,将func返回值传入func1函数中的ii参数。 # 回调函数是在主进程中执行,而不是子进程中。 from multiprocessing import Pool def func(i): return i def func1(ii): print('i+1=',ii+1) if __name__ == '__main__': p=Pool() for i in range(5): p.apply_async(func,args=(i,),callback=func1) p.close() p.join()
小结:
- 管道实现的代码一般加上锁Lock
- p=Pool():实例化;
- p.map(函数名,可迭代类型):默认异步的执行任务,且自带close和join;
- p.apply:同步调用;
- p.apply_async:异步调用和主进程完全异步,需要手动close和join;
欢迎来大家QQ交流群一起学习:482713805