一、总体设计:
1.电子计算机是由具有各种逻辑功能的逻辑部件组成的,加法器就属于其中的组合逻辑电路。如果对传统的加法器电路进行改进,在超前进位链的基础上,用一种新的超前进位链树的设计方法不仅可以克服串行进位加法器速度低的缺点,也可以解决单纯的超前进位加法器带负载能力不足等问题,从而在实际电路中使加法器的运算速度达到最优。根据这种理论,可以推导得到最优的任意位加法器。
2.原理如下:
设二进制加法器第i位为Ai,Bi,输出为Si,进位输入为Ci,进位输出为Ci+1
则有:
Si=Ai⊕Bi⊕Ci
Ci+1 =Ai * Bi+ Ai *Ci+ Bi*Ci =Ai * Bi+(Ai+Bi)* Ci
令Gi = Ai * Bi , Pi = Ai+Bi
则Ci+1= Gi+ Pi *Ci
当Ai和Bi都为1时,Gi = 1, 产生进位Ci+1 = 1
当Ai和Bi有一个为1时,Pi = 1,传递进位Ci+1= Ci
因此Gi定义为进位产生信号,Pi定义为进位传递信号。Gi的优先级比Pi高,也就是说:当Gi = 1时(当然此时也有Pi = 1),无条件产生进位,而不管Ci是多少;
当Gi=0而Pi=1时,进位输出为Ci,跟Ci之前的逻辑有关。
3.总体设计思想:设计先行进位加法器的初衷是为了减少甚至消除各个位之间的进位延迟,由上面的原理可思考得到用p和g来表示进位c。但是仅仅求出每个位的p和g是远远不够的,需要进行级联,不同位之间先行进位代替串行,以保证前一个进位可以影响后面多个位的进位,换句话说,就是后面的位的进位可以由很靠前的位的进位求得,以此来减少相邻位之间的进位延迟。进位c得出后,结果s和zero,overflow更是不再话下了。
4.原理图:
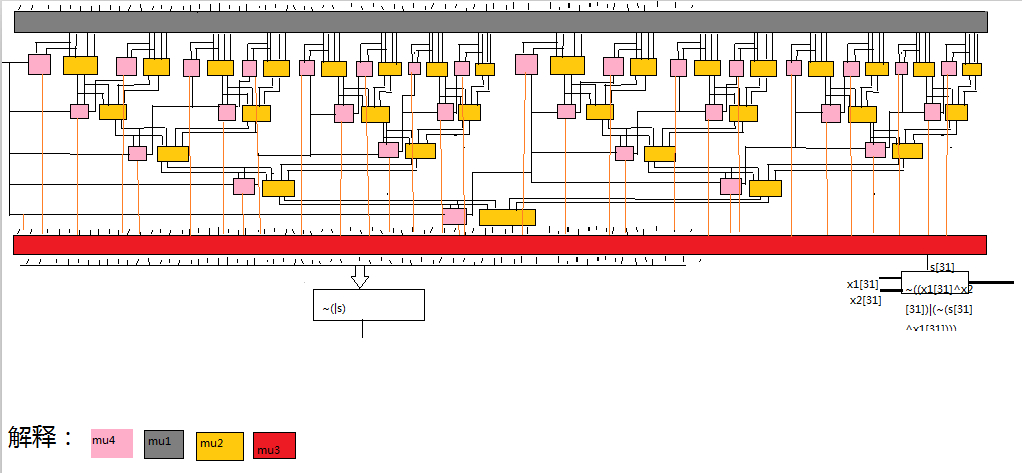
二、功能模块设计:
总共9个模块,1个主模块,4个核心模块,4个辅助模块。
1.主模块mu0:即32位先行进位加法器,输入为两个加数32位的x1和x2,输出为结果32位的s,以及判零标识信号和溢出标识信号。内部调用各个子模块以及判零标识信号和溢出标识信号的产生。见3.1之原理图。
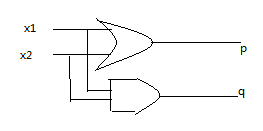
2.核心模块mu1:输入为两个加数32位的x1和x2,输出为进位产生信号g和进位传递信号p。功能即由x1和x2求出p和g。p[31:0] = x1[31:0]| x2[31:0],g[31:0] = x1[31:0]&x2[31:0]。见下图:
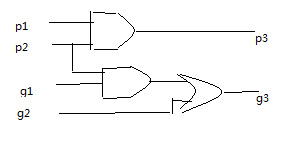
3.核心模块mu2:输入为一位的p1, g1, p2, g2, 输出为p3, g3。即进位产生信号与进位传递信号的级联模块。p3=p1&p2; g3=g2|(p2&g1)。即a+b=11时,进位才可传递,p才为1;而g3若为1,则要么g2为1,最高位产生进位,要么次高位产生进位且最高位可传递进位。 见下图:
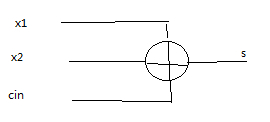
4.核心模块mu3:输入为两个加数32位的x1、x2和每一位的进位cin,输出为结果s。s[31:0]=x1[31:0]^x2[31:0]^cin[31:0]。显然是对的。见下图:
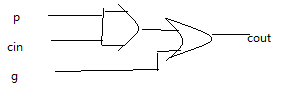
5.核心模块mu4:输入为一位的进位产生信号g和进位传递信号p,以及上一个进位cin,输出为下一个进位cout。cout=g|(p&cin)。见下图:
6.辅助模块mu01:将一级级联的16个模块mu2嵌套,并行处理。
7.辅助模块mu02:将二级级联的8个模块mu2嵌套,并行处理。
8.辅助模块mu03:将三级级联的4个模块mu2嵌套,并行处理。
9.辅助模块mu04:将四级级联的2个模块mu2嵌套,并行处理。
三、源代码:
module mu0(x1,x2,s,zero,overflow); input [31:0]x1,x2; output [31:0]s; output zero,overflow; wire [31:0]p,g,c; wire [15:0]p1,g1; wire [7:0]p2,g2; wire [3:0]p3,g3; wire [1:0]p4,g4; reg zero,overflow; assign c[0]=0; mu1 i0 (x1[31:0],x2[31:0],p[31:0],g[31:0]); mu01 i161 (p[31:0],g[31:0],p1[15:0],g1[15:0]); mu02 i162 (p1[15:0],g1[15:0],p2[7:0],g2[7:0]); mu03 i163 (p2[7:0],g2[7:0],p3[3:0],g3[3:0]); mu04 i164 (p3[3:0],g3[3:0],p4[1:0],g4[1:0]); mu4 i001 (p[0],g[0],c[0],c[1]); mu4 i002 (p1[0],g1[0],c[0],c[2]); mu4 i003 (p[2],g[2],c[2],c[3]); mu4 i004 (p2[0],g2[0],c[0],c[4]); mu4 i005 (p[4],g[4],c[4],c[5]); mu4 i006 (p1[2],g1[2],c[4],c[6]); mu4 i007 (p[6],g[6],c[6],c[7]); mu4 i008 (p3[0],g3[0],c[0],c[8]); mu4 i009 (p[8],g[8],c[8],c[9]); mu4 i010 (p1[4],g1[4],c[8],c[10]); mu4 i011 (p[10],g[10],c[10],c[11]); mu4 i012 (p2[2],g2[2],c[8],c[12]); mu4 i013 (p[12],g[12],c[12],c[13]); mu4 i014 (p1[6],g1[6],c[12],c[14]); mu4 i015 (p[14],g[14],c[14],c[15]); mu4 i016 (p4[0],g4[0],c[0],c[16]); mu4 i017 (p[16],g[16],c[16],c[17]); mu4 i018 (p1[8],g1[8],c[16],c[18]); mu4 i019 (p[18],g[18],c[18],c[19]); mu4 i020 (p2[4],g2[4],c[16],c[20]); mu4 i021 (p[20],g[20],c[20],c[21]); mu4 i022 (p1[10],g1[10],c[20],c[22]); mu4 i023 (p[22],g[22],c[22],c[23]); mu4 i024 (p3[2],g3[2],c[16],c[24]); mu4 i025 (p[24],g[24],c[24],c[25]); mu4 i026 (p1[12],g1[12],c[24],c[26]); mu4 i027 (p[26],g[26],c[26],c[27]); mu4 i028 (p2[6],g2[6],c[24],c[28]); mu4 i029 (p[28],g[28],c[28],c[29]); mu4 i030 (p1[14],g1[14],c[28],c[30]); mu4 i031 (p[30],g[30],c[30],c[31]); mu3 i1 (x1[31:0],x2[31:0],c[31:0],s[31:0]); always @(s) begin zero=~(|s); end always @(x1[31] or x2[31] or s[31]) begin overflow=~((x1[31]^x2[31])|(~(s[31]^x1[31]))); end endmodule module mu1(x1,x2,p,g); input [31:0]x1,x2; output [31:0]p,g; assign p[31:0]=x1[31:0]|x2[31:0],g[31:0]=x1[31:0]&x2[31:0]; endmodule module mu2(p1,g1,p2,g2,p3,g3); input p1,g1,p2,g2; output p3,g3; assign p3=p1&p2; assign g3=g2|(p2&g1); endmodule module mu3(x1,x2,cin,s); input [31:0]x1,x2,cin; output [31:0]s; assign s[31:0]=x1[31:0]^x2[31:0]^cin[31:0]; endmodule module mu4(p,g,cin,cout); input p,g,cin; output cout; assign cout=g|(p&cin); endmodule module mu01(p,g,p1,g1); input [31:0]p,g; output [15:0]p1,g1; mu2 i101 (p[0],g[0],p[1],g[1],p1[0],g1[0]); mu2 i102 (p[2],g[2],p[3],g[3],p1[1],g1[1]); mu2 i103 (p[4],g[4],p[5],g[5],p1[2],g1[2]); mu2 i104 (p[6],g[6],p[7],g[7],p1[3],g1[3]); mu2 i105 (p[8],g[8],p[9],g[9],p1[4],g1[4]); mu2 i106 (p[10],g[10],p[11],g[11],p1[5],g1[5]); mu2 i107 (p[12],g[12],p[13],g[13],p1[6],g1[6]); mu2 i108 (p[14],g[14],p[15],g[15],p1[7],g1[7]); mu2 i109 (p[16],g[16],p[17],g[17],p1[8],g1[8]); mu2 i110 (p[18],g[18],p[19],g[19],p1[9],g1[9]); mu2 i111 (p[20],g[20],p[21],g[21],p1[10],g1[10]); mu2 i112 (p[22],g[22],p[23],g[23],p1[11],g1[11]); mu2 i113 (p[24],g[24],p[25],g[25],p1[12],g1[12]); mu2 i114 (p[26],g[26],p[27],g[27],p1[13],g1[13]); mu2 i115 (p[28],g[28],p[29],g[29],p1[14],g1[14]); mu2 i116 (p[30],g[30],p[31],g[31],p1[15],g1[15]); endmodule module mu02(p1,g1,p2,g2); input [15:0]p1,g1; output [7:0]p2,g2; mu2 i21 (p1[0],g1[0],p1[1],g1[1],p2[0],g2[0]); mu2 i22 (p1[2],g1[2],p1[3],g1[3],p2[1],g2[1]); mu2 i23 (p1[4],g1[4],p1[5],g1[5],p2[2],g2[2]); mu2 i24 (p1[6],g1[6],p1[7],g1[7],p2[3],g2[3]); mu2 i25 (p1[8],g1[8],p1[9],g1[9],p2[4],g2[4]); mu2 i26 (p1[10],g1[10],p1[11],g1[11],p2[5],g2[5]); mu2 i27 (p1[12],g1[12],p1[13],g1[13],p2[6],g2[6]); mu2 i28 (p1[14],g1[14],p1[15],g1[15],p2[7],g2[7]); endmodule module mu03(p2,g2,p3,g3); input [7:0]p2,g2; output [3:0]p3,g3; mu2 i31 (p2[0],g2[0],p2[1],g2[1],p3[0],g3[0]); mu2 i32 (p2[2],g2[2],p2[3],g2[3],p3[1],g3[1]); mu2 i33 (p2[4],g2[4],p2[5],g2[5],p3[2],g3[2]); mu2 i34 (p2[6],g2[6],p2[7],g2[7],p3[3],g3[3]); endmodule module mu04(p3,g3,p4,g4); input [3:0]p3,g3; output [1:0]p4,g4; mu2 i41 (p3[0],g3[0],p3[1],g3[1],p4[0],g4[0]); mu2 i42 (p3[2],g3[2],p3[3],g3[3],p4[1],g4[1]); endmodule
有个网址的16位先行进位加法器设计很不错:http://wenku.baidu.com/link?url=0rD1UQWOlEreA_09-jYhruuWrpBgk_YKFm0UlfB8jrfIxbDVO-j8Fm80NXRYBkXKtXIIlZiW0aLq7PAoHuXbW11lEFTIdhvdk0AOHbqz70u